
[벡터 압축 시리즈 2] [논문 리뷰] TurboQuant: Online Vector Quantization
![[벡터 압축 시리즈 2] [논문 리뷰] TurboQuant: Online Vector Quantization](https://images.unsplash.com/photo-1591879742348-13012c2963bf?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDJ8fHR1cmJvfGVufDB8fHx8MTc4MjAzOTA3OHww&ixlib=rb-4.1.0&q=80&w=2000)
이 글은 TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate 를 리뷰합니다.
이 글은 벡터 압축 시리즈의 두 번째 글입니다. 시리즈는 총 세 편으로 구성할 예정입니다.
- RaBitQ: 이론적 오차 보장을 가지다
- TurboQuant: online vector quantization
- RaBitQ와 TurboQuant 비교
이전 글에서는 RaBitQ를 다뤘습니다. RaBitQ는 randomized codebook을 사용해 distance estimator의 unbiasedness와 error bound를 제공했습니다. 다만 실제 적용 관점에서는 centroid를 어떻게 고를 것인지, 데이터 분포가 바뀌면 어떻게 할 것인지, 그리고 동적으로 들어오는 vector를 바로 quantize할 수 있는지와 같은 문제가 남아 있었습니다.
TurboQuant는 RabitQ의 장점을 유지하면서 위의 단점을 해결했습니다. 논문의 목표는 data-oblivious하고 online으로 적용 가능한 vector quantization입니다. 여기서 data-oblivious는 quantizer를 만들기 위해 데이터셋 전체를 학습하거나 KMeans를 돌리지 않는다는 뜻입니다. online은 vector가 들어왔을 때 별도의 index training 없이 바로 quantize할 수 있다는 의미입니다.
이 특성은 벡터 검색 시스템에서도 중요합니다. RAG나 vector database를 운영하다 보면 embedding이 계속 추가됩니다. 매번 PQ codebook을 다시 학습하거나, 새로운 데이터 분포에 맞춰 quantizer를 재조정하는 것은 부담스럽습니다.
TurboQuant의 핵심 아이디어는 다음과 같습니다.
- input vector를 random rotation합니다.
- 회전된 vector의 각 coordinate가 Beta distribution을 따르도록 만듭니다.
- 고차원에서는 coordinate들이 거의 독립처럼 행동하므로, 각 coordinate를 scalar quantizer로 독립적으로 quantize합니다.
- MSE에 최적화된 quantizer와 inner product에 최적화된 quantizer를 분리합니다.
첫 번째 글의 RaBitQ는 random codebook을 통해 거리 추정 estimator를 분석 가능한 형태로 만들었습니다. TurboQuant는 random rotation을 통해 어떤 input vector라도 회전 후 각 coordinate가 Beta distribution을 따르는 상황으로 바꿉니다. 그래서 고차원 vector quantization을 coordinate별 scalar quantization 문제로 다루었습니다.
[요약]
- TurboQuant는 데이터셋에 맞는 codebook을 학습하지 않는 online vector quantization 방법입니다.
- random rotation을 적용하면 unit vector의 각 coordinate가 Beta distribution을 따르고, 고차원에서는 거의 독립적인 scalar quantization 문제로 볼 수 있습니다.
- MSE에 최적화된 \(Q_{\mathrm{mse}}\)는 각 coordinate를 Lloyd-Max scalar quantizer로 quantize합니다.
- MSE quantizer는 inner product estimator로 쓰면 bias가 생길 수 있으므로, TurboQuant는 residual에 1-bit QJL을 적용한 \(Q_{\mathrm{prod}}\)를 따로 제안합니다.
- 이론적으로 MSE와 inner product distortion 모두 information-theoretic lower bound와 같은 \(4^{-b}\) rate를 따르며, 작은 constant factor 차이만 납니다.
- 논문 실험에서는 nearest neighbor search에서 PQ와 RaBitQ보다 높은 recall을 보였고, quantization time은 사실상 0에 가까웠습니다.
[목차]
- TurboQuant의 문제 정의
- Random rotation이 하는 일
- MSE에 최적화된 TurboQuant
- Inner product에 최적화된 TurboQuant
- Lower bound의 의미
- 효율적인 구현과 online quantization
- 실험 결과
- 나의 생각
TurboQuant의 문제 정의
논문은 vector quantization을 다음과 같이 정의합니다.
\[Q : \mathbb{R}^d \rightarrow \{0, 1\}^{B}\]
\(d\)차원 real-valued vector를 \(B\)-bit binary string으로 바꾸는 함수입니다. 보통 \(B = b \cdot d\)로 두고, \(b\)를 bit-width라고 부릅니다. 즉 \(b\)는 coordinate 하나당 평균 몇 bit를 쓰는지를 의미합니다.
quantization은 lossy compression입니다. 따라서 다시 원래 vector를 완벽하게 복원할 수는 없습니다. 대신 dequantization map을 둡니다.
\[Q^{-1} : \{0, 1\}^{B} \rightarrow \mathbb{R}^d\]
이제 좋은 quantizer란 무엇인지 정해야 합니다. TurboQuant는 두 가지 distortion을 봅니다.
첫 번째는 MSE입니다.
\[D_{\mathrm{mse}}:=\mathbb{E}_{Q}\left[\left\|x - Q^{-1}(Q(x))\right\|_2^2\right]\]
원본 vector \(x\)와 dequantized vector \(Q^{-1}(Q(x))\)가 얼마나 가까운지를 봅니다.
두 번째는 inner product error입니다.
\[D_{\mathrm{prod}}:=\mathbb{E}_{Q}\left[\left(\langle y, x\rangle-\left\langle y, Q^{-1}(Q(x))\right\rangle\right)^2\right]\]
벡터 검색이나 attention에서는 reconstruction 자체보다 query vector \(y\)와의 inner product를 잘 보존하는 것이 중요할 수 있습니다.
또한 inner product quantizer에는 unbiasedness를 요구합니다.
\[\mathbb{E}_{Q}\left[\left\langle y, Q^{-1}(Q(x))\right\rangle\right]=\langle y, x\rangle\]
즉 quantized vector로 계산한 inner product의 기대값이 원래 inner product와 같아야 합니다. 평균적으로 한쪽 방향으로 계속 크게 나오거나 작게 나오면, nearest neighbor search나 attention score에서 ranking bias가 생길 수 있습니다.
여기서 중요한 점은 MSE에 좋은 quantizer가 inner product에도 자동으로 좋은 것은 아니라는 점입니다. TurboQuant는 MSE용 quantizer와 inner product용 quantizer를 분리해서 설계합니다.
Random rotation이 하는 일
TurboQuant는 먼저 input vector \(x\)가 unit sphere 위에 있다고 가정합니다.
\[\|x\|_2 = 1\]
이제 \(x\)에 random rotation matrix \(\Pi\)를 곱합니다.
\[y = \Pi x\]
\(\Pi\)는 orthogonal matrix이므로 vector의 길이를 바꾸지 않습니다.
\[\|\Pi x\|_2 = \|x\|_2\]
그런데 fixed vector \(x\)에 random rotation을 적용하면, \(\Pi x\)는 unit sphere 위에서 uniform하게 뽑힌 random point처럼 볼 수 있습니다. 이때 각 coordinate \(y_j\)는 다음과 같은 Beta distribution을 따릅니다.
이 성질 자체는 TurboQuant 논문이 새로 제안한 것은 아니고, hypersphere 위의 uniform random point가 갖는 coordinate distribution에 대한 알려진 결과를 인용해 사용하는 것입니다.
\[f_X(t)=\frac{\Gamma(d/2)}{\sqrt{\pi}\Gamma((d-1)/2)}(1-t^2)^{(d-3)/2}\]
고차원에서는 이 분포가 평균 0, 분산 \(1/d\)인 normal distribution에 가까워집니다.
\[f_X(t) \rightarrow \mathcal{N}(0, 1/d)\]
직관적으로 unit vector가 고차원 sphere 위에 고르게 퍼져 있으면, 하나의 coordinate가 큰 값을 가지기 어렵습니다. 대부분의 coordinate는 0 근처에 있고, 크기는 대략 \(1/\sqrt{d}\) 수준입니다.
TurboQuant는 이 성질을 이용합니다. 원래 vector quantization은 \(d\)차원 vector 전체를 한 번에 quantize하는 문제입니다. 하지만 random rotation 이후에는 각 coordinate가 같은 분포를 따르고, 고차원에서는 서로 거의 독립처럼 행동합니다. 따라서 논문은 이 문제를 coordinate별 scalar quantization 문제로 바꿉니다.
original vector x
│
▼
random rotation
y = Πx
│
▼
coordinate-wise scalar quantization
[quantize y1] [quantize y2] ... [quantize yd]이 구조가 TurboQuant를 단순하게 만드는데, 각 coordinate에 같은 scalar quantizer를 적용하면 되기 때문입니다.
MSE에 최적화된 TurboQuant
먼저 MSE를 최소화하는 \(Q_{\mathrm{mse}}\)부터 보겠습니다.
random rotation 후 각 coordinate는 Beta distribution \(f_X\)를 따릅니다. 그러면 coordinate 하나를 \(b\)-bit로 quantize하는 문제는 다음과 같이 바뀝니다.
- 구간 \([-1, 1]\)을 \(2^b\)개의 bucket으로 나눕니다.
- 각 bucket을 대표하는 centroid \(c_i\)를 고릅니다.
- \(f_X\) 분포에서 평균 squared error가 최소가 되도록 centroid를 정합니다.
이는 1차원 continuous KMeans 문제입니다. 논문은 Lloyd-Max algorithm을 이용해 optimal scalar codebook을 미리 계산해둘 수 있다고 설명합니다. Lloyd-Max algorithm은 1차원 quantization에서 bucket 경계와 centroid를 번갈아 업데이트하면서 평균 squared error를 줄이는 반복 알고리즘입니다
수식으로 쓰면 다음 cost를 최소화하는 centroid를 찾는 문제입니다.
\[C(f_X, b):=\min_{-1 \le c_1 \le \cdots \le c_{2^b} \le 1}\sum_{i=1}^{2^b}\int_{\frac{c_{i-1}+c_i}{2}}^{\frac{c_i+c_{i+1}}{2}}|t-c_i|^2 f_X(t)dt\]
이 식이 복잡해 보이지만 의미는 단순합니다. coordinate 값 \(t\)가 어떤 centroid \(c_i\)로 quantize될 때 생기는 squared error를 확률분포 \(f_X\)에 대해 평균낸 것입니다. 여기서 \(f_X\)는 앞에서 본 것처럼 random rotation 이후 각 coordinate가 따르는 Beta distribution입니다.
TurboQuant의 MSE quantization 흐름은 다음과 같습니다.
Quantmse(x)
y = Πx
for each coordinate yj:
idxj = nearest centroid index
return idx
DeQuantmse(idx)
for each idxj:
y_tilde_j = centroid[idxj]
x_tilde = Πᵀ y_tilde
return x_tilde\(\Pi\)가 rotation matrix이므로, rotated space에서의 reconstruction error와 original space에서의 reconstruction error가 같습니다.
\[\|x - \tilde{x}\|_2=\|\Pi x - \tilde{y}\|_2\]
따라서 전체 MSE는 coordinate별 scalar quantization error의 합으로 볼 수 있습니다.
\[D_{\mathrm{mse}}=d \cdot C(f_X, b)\]
논문은 다음 bound를 보입니다. 증명은 논문에 나와있고, 이 글에서는 생략합니다.
\[D_{\mathrm{mse}}(Q_{\mathrm{mse}})\le\frac{\sqrt{3}\pi}{2}\cdot 4^{-b}\]
여기서 \(4^{-b}\)가 중요합니다. bit-width \(b\)가 1 증가할 때마다 distortion이 대략 4분의 1로 줄어드는 rate입니다.
작은 bit-width에서는 더 구체적인 값을 제공합니다.
| bit-width (b) | MSE distortion |
|---|---|
| 1 | 약 0.36 |
| 2 | 약 0.117 |
| 3 | 약 0.03 |
| 4 | 약 0.009 |
즉 4-bit per coordinate 정도만 써도 reconstruction MSE가 꽤 작아집니다.
논문은 entropy encoding도 잠깐 언급합니다. centroid index가 균등하게 등장하지 않으므로, index를 entropy coding하면 평균 bit-width를 조금 줄일 수 있습니다. 특히 \(b=4\)에서는 entropy가 약 3.8bit라서 평균 bit-width를 약 5퍼센트 줄일 수 있습니다. 다만 gain이 크지 않고 구현 단순성을 해치기 때문에 TurboQuant에는 넣지 않았습니다.
Inner product에 최적화된 TurboQuant
벡터 검색에서는 MSE만으로 충분하지 않을 수 있습니다. 우리가 실제로 원하는 것은 query \(y\)와 data vector \(x\)의 inner product입니다.
\[\langle y, x\rangle\]
MSE quantizer로 복원한 vector \(\tilde{x}_{\mathrm{mse}}\)를 사용하면 다음 값을 계산할 수 있습니다.
\[\left\langle y, \tilde{x}_{\mathrm{mse}}\right\rangle\]
하지만 이 estimator는 unbiased가 아닐 수 있습니다. 논문은 1-bit case를 예로 듭니다. \(b=1\)에서 MSE에 최적인 scalar codebook을 사용하면, inner product estimator에 \(2/\pi\) 형태의 multiplicative bias가 생깁니다.
직관적으로 MSE quantizer는 원본 vector를 잘 복원하는 방향으로 설계됩니다. 하지만 inner product는 특정 query 방향에서의 projection을 보는 값입니다. reconstruction error가 작더라도 그 error가 query 방향으로 체계적으로 나타나면 inner product에는 bias가 생길 수 있습니다.
그래서 TurboQuant는 inner product용 quantizer \(Q_{\mathrm{prod}}\)를 따로 만듭니다.
- \(b-1\) bit-width의 \(Q_{\mathrm{mse}}\)로 먼저 vector를 quantize합니다.
- 원본 \(x\)와 MSE reconstruction \(\tilde{x}_{\mathrm{mse}}\)의 차이인 residual을 구합니다.
- residual에 1-bit QJL을 적용합니다.
residual은 다음과 같습니다.
\[r=x - Q_{\mathrm{mse}}^{-1}(Q_{\mathrm{mse}}(x))\]
MSE quantizer가 이미 \(x\)를 잘 복원했으므로, residual의 norm은 작습니다. TurboQuant는 이 작은 residual에 1-bit Quantized Johnson-Lindenstrauss(QJL)를 적용합니다.
QJL은 unit vector에 대해 다루므로, TurboQuant는 residual의 방향과 크기를 나누어 다룹니다.
\[\gamma = \|r\|_2,\qquad\hat{r} = \frac{r}{\|r\|_2}\]
QJL은 다음과 같은 1-bit quantizer입니다.
\[Q_{\mathrm{qjl}}(\hat{r})=\mathrm{sign}(S\hat{r})\]
여기서 \(S\)는 Gaussian random matrix입니다. residual 방향에 대한 dequantization은 다음과 같이 정의됩니다.
\[\tilde{r}_{\mathrm{dir}}=\frac{\sqrt{\pi/2}}{d}S^\top z\]
그리고 residual의 크기 \(\gamma\)를 다시 곱해 scale을 복원합니다.
\[\tilde{x}_{\mathrm{qjl}}=\gamma \tilde{r}_{\mathrm{dir}}\]
QJL의 중요한 성질은 inner product estimator가 unbiased라는 점입니다.
\[\mathbb{E}\left[\left\langle y, \tilde{x}_{\mathrm{qjl}}\right\rangle\right]=\langle y, r\rangle\]
TurboQuant는 이 성질을 residual에 사용합니다. 최종 reconstruction은 MSE reconstruction과 residual reconstruction의 합입니다.
\[\tilde{x}=\tilde{x}_{\mathrm{mse}}+\tilde{x}_{\mathrm{qjl}}\]
그러면 inner product의 기대값은 다음과 같이 원래 값과 같아집니다.
$$\begin{aligned}\mathbb{E}[\langle y, \tilde{x}\rangle]&=\mathbb{E}[\langle y, \tilde{x}\_{\mathrm{mse}} + \tilde{x}\_{\mathrm{qjl}}\rangle] \\\\&=\langle y, \tilde{x}\_{\mathrm{mse}}\rangle+\langle y, r\rangle \\\\&=\langle y, \tilde{x}\_{\mathrm{mse}} + x - \tilde{x}\_{\mathrm{mse}}\rangle \\\\&=\langle y, x\rangle\end{aligned}$$
즉 MSE quantizer로 큰 구조를 잡고, 남은 residual은 QJL로 unbiased하게 보정합니다.
논문에서 \(Q_{\mathrm{prod}}\)의 output은 다음 세 가지입니다.
(idx, qjl, gamma)- idx: \(b-1\) bit-width MSE quantizer의 centroid index*
- qjl: residual에 대한 sign vector
- gamma: residual norm \(\|r\|_2\)
전체 bit budget은 coordinate당 \(b\) bit로 볼 수 있습니다. \(b-1\) bit는 MSE quantizer index에 쓰고, 1 bit는 residual QJL sign에 씁니다. (다만 실제 구현에서는 residual norm \(\gamma\) 같은 scalar metadata도 저장해야 합니다.)
논문은 \(Q_{\mathrm{prod}}\)에 대해 다음 bound를 보입니다. 마찬가지로 증명은 논문에 나와있고, 이 글에서는 생략합니다.
\[D_{\mathrm{prod}}(Q_{\mathrm{prod}})\le\frac{\sqrt{3}\pi^2\|y\|_2^2}{d}\cdot 4^{-b}\]
작은 bit-width에서는 다음 값을 제공합니다.
| bit-width (b) | inner product distortion |
|---|---|
| 1 | 약 (1.57/d) |
| 2 | 약 (0.56/d) |
| 3 | 약 (0.18/d) |
| 4 | 약 (0.047/d) |
dimension이 커질수록 inner product distortion이 줄어들므로 고차원 embedding에서 TurboQuant가 잘 맞습니다.
Lower bound의 의미
TurboQuant 논문은 upper bound만 보이지 않습니다. 어떤 vector quantizer도 넘기 어려운 lower bound도 함께 제시합니다.
MSE에 대해서는 어떤 randomized quantizer라도 hard input(그 quantizer가 잘 처리하기 어려운 입력 vector)에서는 다음보다 좋은 expected distortion을 보장할 수 없다고 말합니다.
\[D_{\mathrm{mse}}\ge4^{-b}\]
inner product distortion에 대해서도 다음 lower bound를 보입니다.
\[D_{\mathrm{prod}}\ge\frac{\|y\|_2^2}{d}\cdot 4^{-b}\]
증명에는 Shannon lower bound와 Yao's minimax principle이 사용됩니다.
Shannon lower bound는 정보 이론에서 나온 결과입니다. 주어진 bit budget으로 lossy compression을 할 때, 아무리 좋은 encoding을 써도 distortion을 일정 수준 이하로 낮출 수 없다는 하한을 제공합니다.
Yao's minimax principle은 randomized algorithm의 worst-case 성능을 분석할 때 자주 쓰입니다. worst-case input에 대한 randomized algorithm의 한계를 보기 위해 hard input distribution에 대한 deterministic algorithm의 한계를 보는 방식입니다. 이 부분의 세부 증명은 논문 본문에서도 짧게만 다루고 있으므로 생략하겠습니다.
TurboQuant의 distortion rate는 lower bound와 같은 \(4^{-b}\) 형태입니다. 즉 bit-width에 따른 감소 rate는 information-theoretically optimal합니다. 차이는 constant factor입니다. 논문은 MSE distortion이 lower bound 대비 최대 약 2.7배 이내라고 설명합니다. 작은 bit-width에서는 이 차이가 더 줄어듭니다.
효율적인 구현과 online quantization
TurboQuant가 실용적인 이유는 quantization 과정이 단순하기 때문입니다.
MSE quantizer 기준으로 보면 필요한 작업은 다음입니다.
- random rotation matrix \(\Pi\)를 곱합니다.
- 각 coordinate에 scalar quantizer를 적용합니다.
- centroid index를 저장합니다.
이 과정에는 데이터셋 전체에 대한 KMeans training이 없습니다. codebook은 입력 데이터에 맞춰 학습하는 것이 아니라, random rotation 이후 coordinate가 따르는 이론적 분포 \(f_X\) (beta distribution)에 대해 미리 계산합니다.
따라서 vector가 하나 들어오면 바로 quantize할 수 있습니다.
new vector x arrives
│
▼
normalize or store norm
│
▼
random rotation Πx
│
▼
coordinate-wise scalar quantization
│
▼
store compact code이 점이 PQ와 크게 다릅니다. PQ는 데이터 분포에 맞는 sub-codebook을 학습해야 합니다. 이 때문에 데이터가 계속 들어오거나 분포가 바뀌는 상황에서는 codebook update 문제가 생깁니다.
TurboQuant는 quantizer가 데이터셋에 의존하지 않기 때문에 이러한 부담이 없습니다.
물론 random rotation을 곱하는 비용이 존재합니다. 다만 이 연산은 matrix-vector multiplication이고, coordinate-wise quantization도 단순한 비교 연산입니다. 논문이 accelerator-friendly하다고 주장하는 이유가 여기에 있습니다. GPU나 accelerator는 이런 matrix-vector multiplication과 coordinate별 연산을 병렬로 처리하는 데 강합니다.
검색 시점의 거리 계산도 data vector를 매번 dequantize해서 원래 \(d\)차원 float vector로 복원한 뒤 계산하는 방식으로 이해하면 안 됩니다. 실제 구현에서는 PQ와 비슷하게 query별 lookup table(LUT)을 만들 수 있습니다.
예를 들어 data vector \(x\)가 MSE TurboQuant로 quantize되어 있고, coordinate \(j\)의 code가 centroid index \(\mathrm{idx}_j\)를 저장한다고 하겠습니다. Query \(q\)가 들어오면 먼저 같은 rotation을 적용합니다.
\[q' = \Pi q\]
그러면 dequantized data vector와 query의 inner product는 다음처럼 쓸 수 있습니다.
$$\left\langle q, \tilde{x}\right\rangle = \left\langle q', \tilde{y}\right\rangle$$
coordinate별로 쓰면 다음과 같습니다.
$$\left\langle q', \tilde{y}\right\rangle = q'(1)c(\mathrm{idx}(1)) + \cdots + q'(d)c(\mathrm{idx}(d))$$
여기서 \(q'(j)\)는 rotated query \(q'\)의 \(j\)번째 coordinate입니다. \(\mathrm{idx}(j)\)는 data vector의 \(j\)번째 coordinate에 저장된 centroid index이고, \(c(\mathrm{idx}(j))\)는 그 index가 가리키는 centroid 값입니다.
따라서 query가 들어올 때 coordinate와 centroid별 값을 미리 계산해 LUT에 저장할 수 있습니다.
\[\mathrm{LUT}[j][k] = q'_j c_k\]
이후 data code 하나의 score는 다음처럼 lookup과 sum으로 계산됩니다.
\[\mathrm{score}(q, x)=\sum_{j=1}^{d}\mathrm{LUT}[j][\mathrm{idx}_j]\]
즉 data vector를 float vector로 복원하지 않습니다. Data side에는 centroid index code만 저장하고, query side에서 만든 LUT를 이용해 code를 훑으면서 값을 더합니다.
Inner product용 \(Q_{\mathrm{prod}}\)에서는 여기에 residual QJL term이 하나 더 붙습니다. Query에 대해 \(S q\) 또는 같은 의미의 query-side projection을 미리 계산해두고, data side에 저장된 sign vector와 dot product를 계산한 뒤 residual norm \(\gamma\)로 scale합니다. 이 부분도 원본 residual vector를 복원해서 계산하는 것이 아니라, sign code와 query-side precomputation을 이용해 계산합니다.
이 구조는 IVF처럼 많은 후보 code를 한 번에 scan하는 경우와 잘 맞습니다. Query마다 만든 LUT 비용을 수백~수천 개 후보에 나눠서 amortize할 수 있기 때문입니다. 반면 HNSW는 애초에 방문 후보 수를 줄이는 방식이므로, LUT를 사용할 수는 있어도 batch scan 최적화의 이득은 상대적으로 작을 수 있습니다.
실험 결과
논문은 먼저 이론적 distortion bound가 실제 실험에서도 잘 맞는지 확인한 뒤, downstream task로 KV cache quantization과 nearest neighbor search를 평가합니다.
첫 번째는 estimator 검증입니다. TurboQuant는 MSE용 \(Q_{\mathrm{mse}}\)와 inner product용 \(Q_{\mathrm{prod}}\)를 따로 측정했습니다.
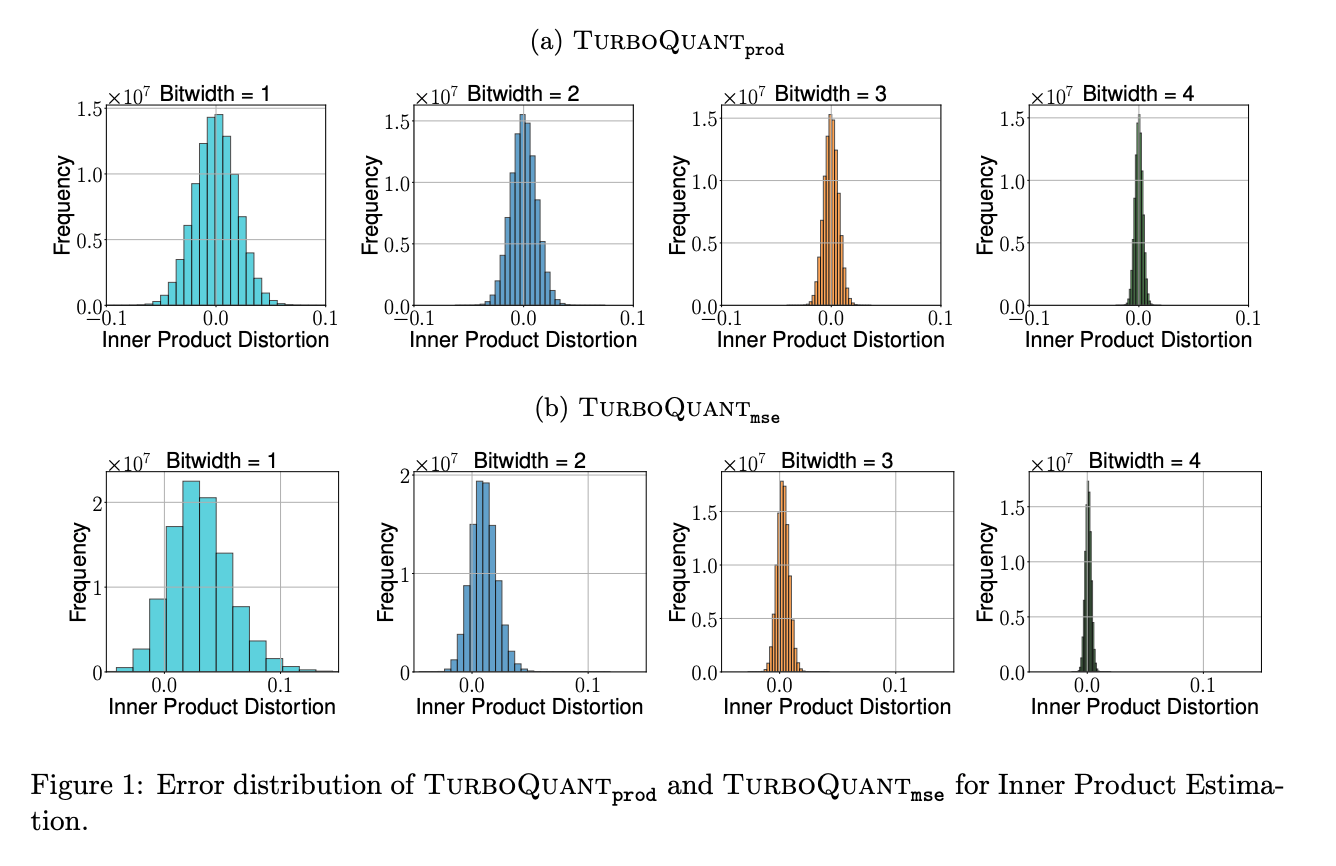
Figure 1에서 \(Q_{\mathrm{prod}}\)는 inner product error가 0을 중심으로 분포합니다. 반면 \(Q_{\mathrm{mse}}\)는 낮은 bit-width에서 bias가 보이고, bit-width가 커질수록 bias가 줄어듭니다.
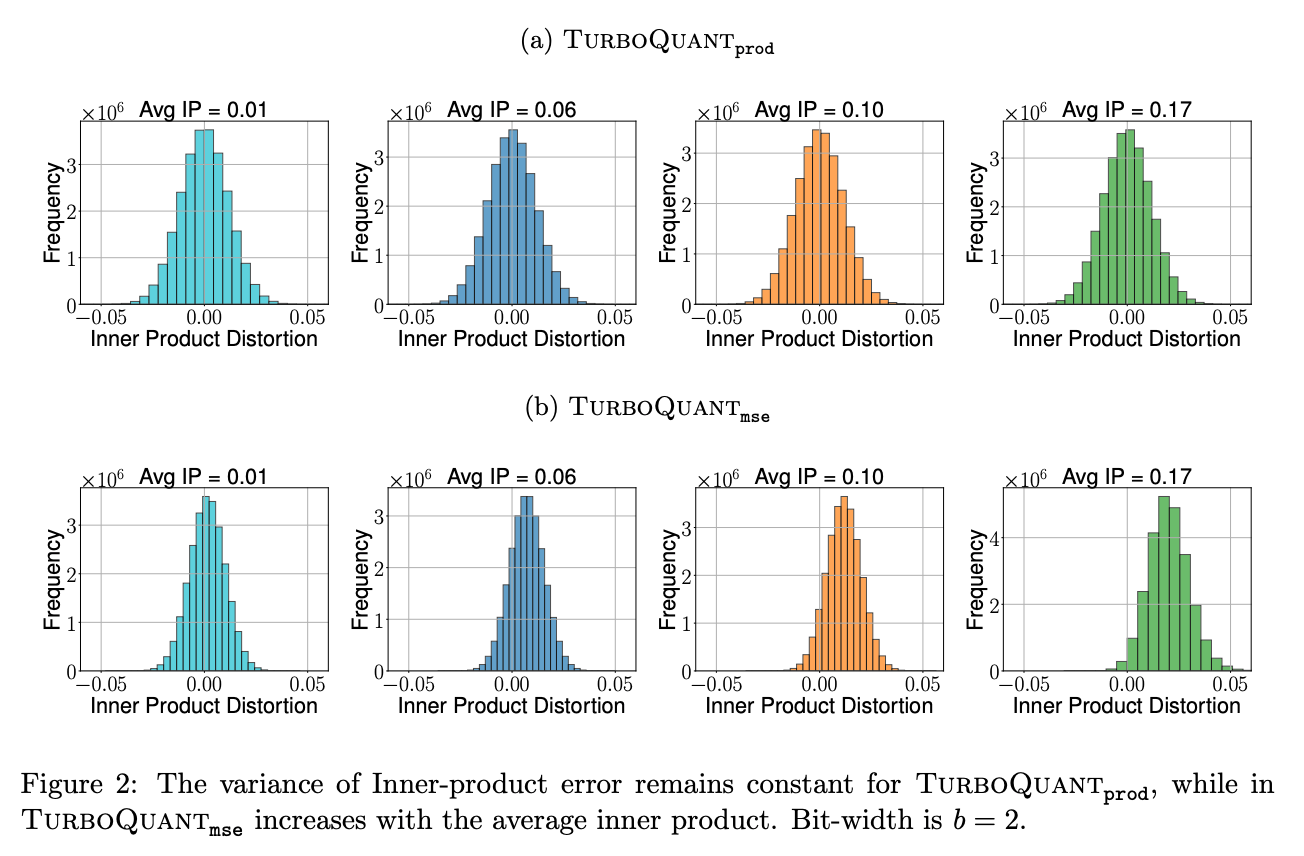
Figure 2는 \(Q_{\mathrm{prod}}\)의 variance가 평균 inner product 크기에 크게 의존하지 않는 반면, \(Q_{\mathrm{mse}}\)의 bias는 평균 inner product가 커질수록 커지는 모습을 보여줍니다.
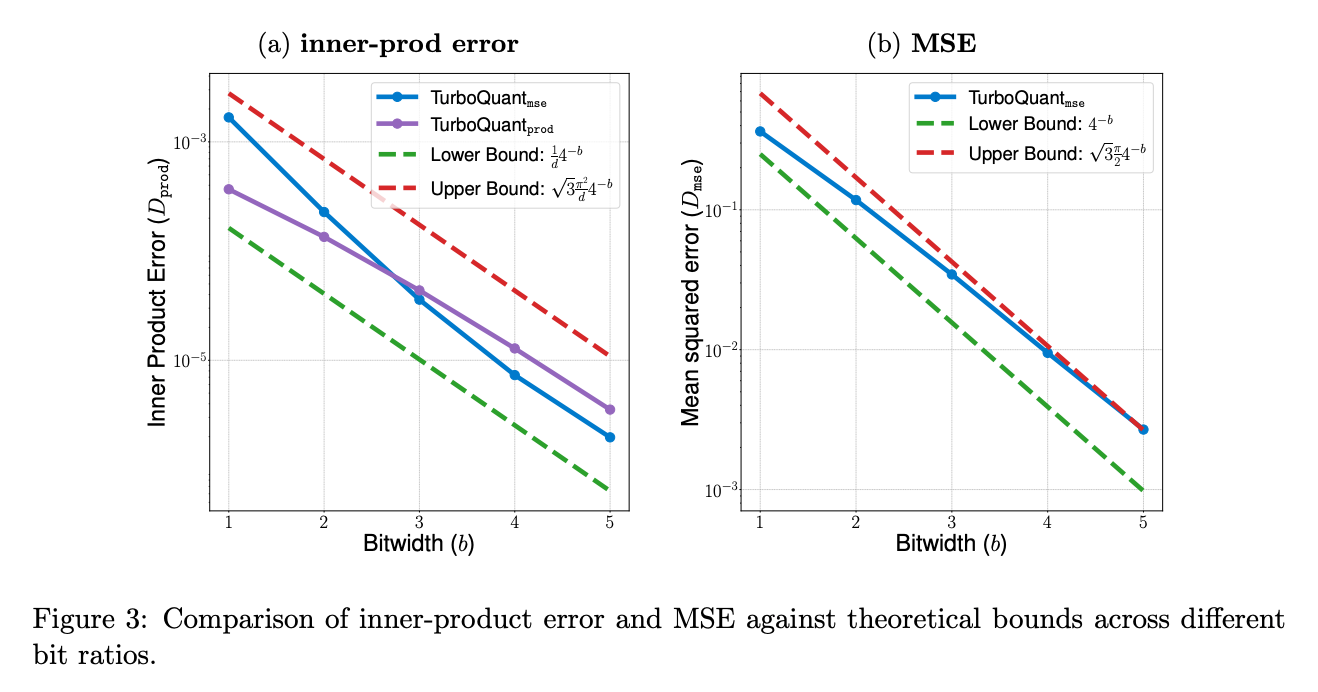
Figure 3에서는 bit-width가 증가할수록 inner product error와 MSE가 이론적 bound와 비슷한 rate로 감소합니다. 논문이 주장하는 \(4^{-b}\) distortion rate가 실험에서도 어느 정도 맞는지 확인합니다.
두 번째는 KV cache quantization입니다. KV cache는 generation 중에 key/value vector가 계속 생기기 때문에 online quantization이 특히 잘 맞는 영역입니다.
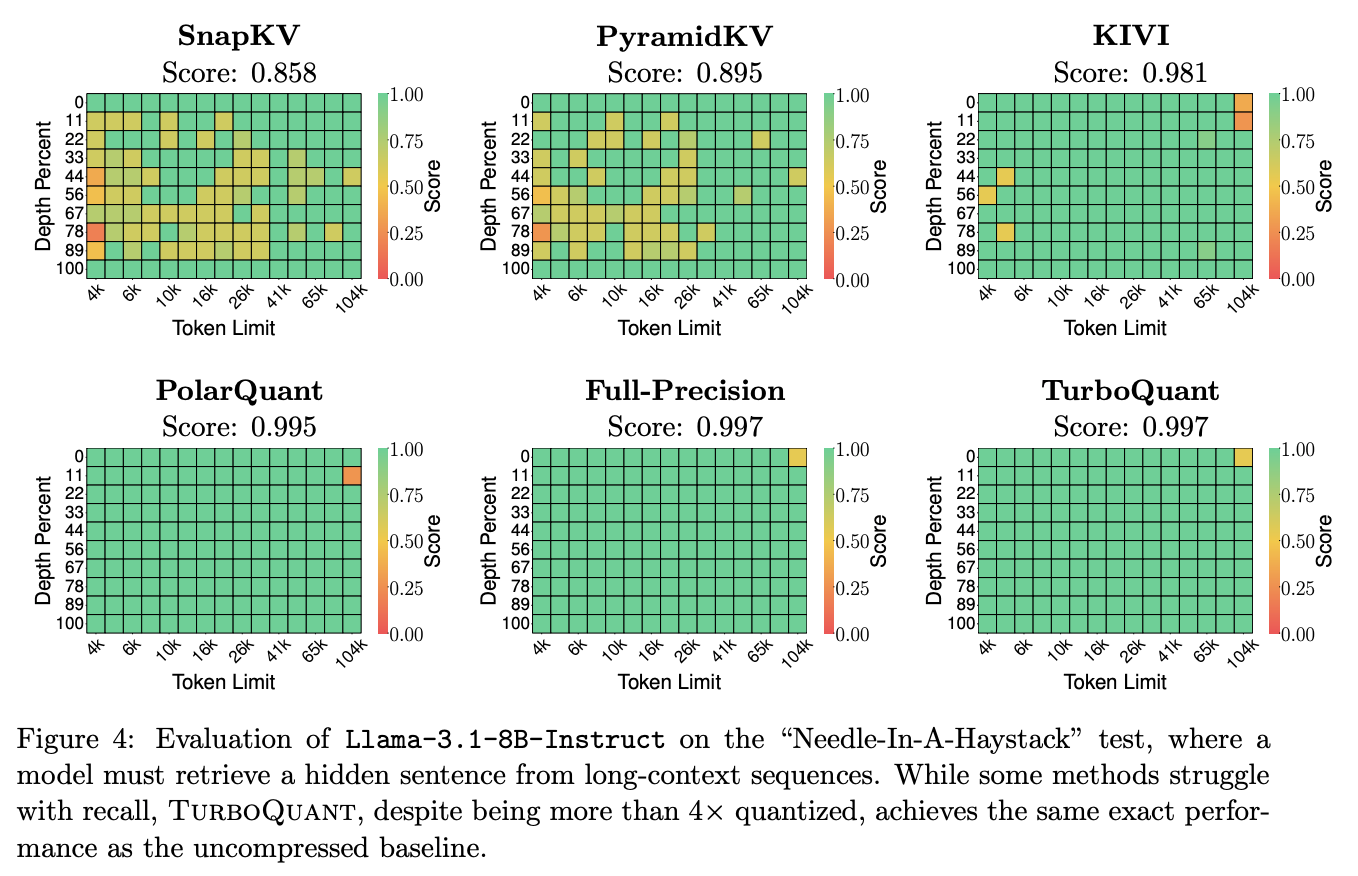
Figure 4에서 TurboQuant는 4배 이상 quantized된 상태에서도 full-precision baseline과 같은 Needle-In-A-Haystack score를 보입니다.
세 번째는 nearest neighbor search입니다. 평가 방식은 1@k recall입니다. true top inner product result가 approximate top-k 결과 안에 들어오는지를 봅니다.
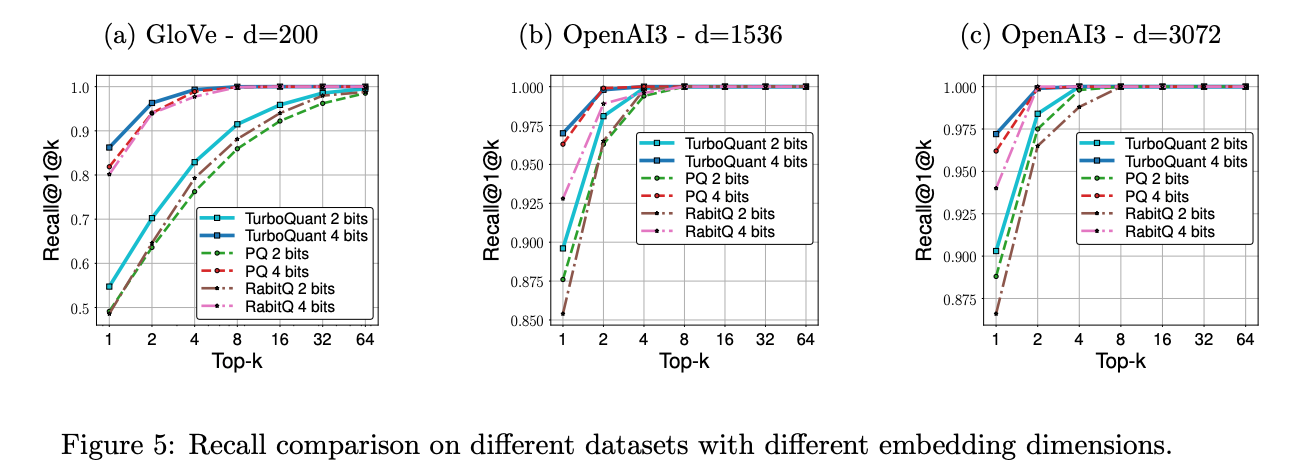
Figure 5에서 TurboQuant는 PQ와 RaBitQ보다 높은 recall을 보입니다.
quantization time 차이도 큽니다. 4-bit quantization 기준 table은 다음과 같습니다.
| 방법 | (d=200) | (d=1536) | (d=3072) |
|---|---|---|---|
| Product Quantization | 37.04s | 239.75s | 494.42s |
| RaBitQ | 597.25s | 2267.59s | 3957.19s |
| TurboQuant | 0.0007s | 0.0013s | 0.0021s |
이 수치는 TurboQuant의 online 특성을 잘 보여줍니다.
나의 생각
개인적으로 이 논문에서 가장 흥미로웠던 것은 vector quantization을 다시 scalar quantization 문제로 바꾼 것입니다.
일반적으로 고차원 vector quantization은 어렵습니다. vector 사이의 거리와 inner product 관계를 보존해야 하고, coordinate 간 상관관계도 신경 써야 합니다. PQ는 이 문제를 sub-vector로 쪼개고, 각 sub-space에서 KMeans codebook을 학습하는 방식으로 해결합니다.
TurboQuant는 random rotation으로 vector들을 sphere 위의 random point처럼 만들고, coordinate별 scalar quantization을 수행합니다.
RaBitQ 글에서도 randomness가 중요한 역할을 했습니다. RaBitQ는 random codebook을 통해 estimator의 error를 분석 가능한 형태로 만들었습니다. TurboQuant는 random rotation 후 각 coordinate가 Beta distribution을 따르게 만들고, 각 coordinate를 독립적으로 quantize하는 방식으로 분석할 수 있게 만듭니다. 두 논문 모두 randomness를 이론적 보장을 위한 도구로 사용합니다.
실제 vector DB 관점에서 보면 TurboQuant의 장점은 online입니다. 데이터가 계속 들어오는 시스템에서는 quantizer training이 부담입니다. 특히 embedding model이 바뀌거나, tenant마다 데이터 분포가 다르거나, cold-start dataset이 작은 경우에는 data-dependent codebook이 안정적으로 동작할지 알 수가 없습니다.
다만 실제 적용시 몇 가지 확인할 점이 있습니다.
첫째, query마다 드는 고정 비용입니다. TurboQuant는 query에 random rotation을 적용하고 LUT를 만들어야 합니다. 따라서 한 query에서 충분히 많은 candidate를 scan해야 이 비용을 잘 나눠 부담할 수 있습니다. 이러한 점에 있어서 HNSW 그래프 베이스 알고리즘에 잘 맞을지는 실제로 테스트를 해봐야 할 것 같습니다(이 지점은 rabitq와도 비슷한 것 같네요)
둘째, inner product용 \(Q_{\mathrm{prod}}\)는 residual norm 같은 metadata를 저장합니다. 실제 운영할 때는 이러한 vector당 추가 scalar, random matrix, LUT 생성 등의 비용을 고려해야합니다.
마무리
TurboQuant는 online vector quantization을 목표로 하는 논문입니다. 데이터셋에 맞는 codebook을 학습하지 않고, random rotation을 통해 각 coordinate가 Beta distribution을 따르도록 만든 뒤, 각 coordinate를 독립적으로 quantize합니다.
MSE에 대해서는 \(Q_{\mathrm{mse}}\)를, inner product에 대해서는 residual QJL을 결합한 \(Q_{\mathrm{prod}}\)를 제안합니다. 특히 \(Q_{\mathrm{prod}}\)는 unbiased inner product estimator를 제공하고, distortion은 \(4^{-b}\) rate로 줄어듭니다.
첫 번째 글에서 다룬 RaBitQ가 “이론적 error bound를 가진 빠른 quantization”이라면, TurboQuant는 “online으로 바로 적용 가능한 near-optimal quantization”입니다. 두 방법이 실제 vector search 시스템에서는 어떤 trade-off가 있는지는 세 번째 글에서 비교해보겠습니다.
Reference
- TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
- RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search
- QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead
- Product Quantization for Nearest Neighbor Search
- Shannon Lower Bound