
[벡터 압축 시리즈 1] [논문 리뷰] RaBitQ: 이론적 오차 보장을 가지다
![[벡터 압축 시리즈 1] [논문 리뷰] RaBitQ: 이론적 오차 보장을 가지다](https://images.unsplash.com/photo-1703437873366-b7a9e54dab56?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDN8fHJhYml0fGVufDB8fHx8MTc4MjAzMTcwNHww&ixlib=rb-4.1.0&q=80&w=2000)
이 글은 SIGMOD 2024 논문인 RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search 를 리뷰합니다.
이 글은 벡터 압축 시리즈의 첫 번째 글입니다. 시리즈는 총 세 편으로 구성할 예정입니다.
- RaBitQ: 이론적 오차 보장을 가지다
- TurboQuant: online vector quantization
- RaBitQ와 TurboQuant 비교
이번 글에서는 RaBitQ 자체를 이해하는 데 집중합니다. TurboQuant와의 비교는 세 번째 글에서 따로 다룰 예정이므로, 여기서는 RaBitQ가 어떤 문제를 풀고 어떤 방식으로 distance estimation을 수행하는지에 초점을 맞추겠습니다.
벡터 검색에서 ANN(Approximate Nearest Neighbor)을 구현할 때 가장 먼저 떠올리는 인덱스는 HNSW 같은 graph 기반 인덱스입니다. HNSW는 실제 서비스에서도 널리 쓰이는 방법이지만, 벡터 검색 시스템의 설계 공간이 graph index 하나로 끝나는 것은 아닙니다. 벡터를 메모리에 어떻게 올릴지, 후보군의 거리를 어떻게 빠르게 계산할지 등의 고민이 여전히 존재합니다.
이러한 문제들을 고민하다 보면 벡터의 크기를 줄이는 방법을 고려하게됩니다. 벡터의 크기를 줄이면 색인 크기가 줄어들어 더 많은 벡터를 가진 색인을 운영할 수 있고, 벡터 간 거리 계산에 메모리 대역폭이 병목인 경우 검색 속도를 향상시킬 수 있습니다.
이 지점에서 자주 등장하는 방법이 Product Quantization(PQ)입니다. PQ는 고차원 벡터를 짧은 code로 압축하고, query와 data vector 사이의 거리를 빠르게 근사합니다. 특히 PQ는 IVF처럼 inverted list 안의 후보들을 순차적으로 scan하는 구조와 잘 맞습니다. Query마다 lookup table을 만들고, list 안의 PQ code들을 batch/SIMD로 처리하기 좋기 때문입니다.
HNSW 같은 graph 기반 인덱스에 PQ를 결합하는 구현도 존재하지만, 보통 PQ와 IVF를 조합해서 많이 사용합니다.
IVF는 쿼리가 들어오면 여러 개의 inverted list 중 가까운 inverted list를 선택하고, 그 list 내의 수백~수천 개의 벡터들을 sequential scan하는 방식입니다. PQ를 적용했다면 code들이 한 list에 모여있어 메모리가 연속적으로 배치되어 있을 것이고, 이를 SIMD로 scan하기 좋습니다.
반면 graph base ANN은 도착한 노드의 neighbor들을 가져와서 거리를 계산합니다. 여기서 두 문제가 발생합니다.
(1) neighbor들의 메모리가 연속적이지 않아 벡터를 가져오는 비용이 크고(random access)
(2) SIMD를 적용할 때 neighbor들을 단위로 계산하므로 batch 크기가 IVF에 비해 작습니다.
(1)은 PQ와 상관없는 단점이지만 (2)번이 PQ가 graph based ANN에서 덜 효과가 나오는 주요 이유입니다.
하지만 PQ 계열 방법에는 아쉬운 점이 있습니다. 빠르고 실용적이지만, 근사 거리의 오차가 얼마나 되는지 이론적으로 보장하기 어렵습니다.
RaBitQ는 이 문제를 해결하기 위해 제안된 quantization 방법입니다. codebook을 더 잘 학습시키는 것이 아니라, 랜덤하게 회전시킨 bi-valued vector codebook을 사용합니다. 여기서 bi-valued codebook은 각 coordinate(차원)가 두 가지 값 중 하나만 가질 수 있는 vector들로 이루어진 codebook을 의미합니다. RaBitQ에서는 이 구조 덕분에 거리 추정에 대한 unbiased estimator와 error bound를 얻을 수 있었습니다.
[요약]
- RaBitQ는 \(D\)차원 벡터를 \(D\)-bit string으로 양자화하는 방법입니다.
- PQ와 달리 거리 추정 estimator가 unbiased이며, \(O(1/\sqrt{D})\) 수준의 이론적 error bound를 제공합니다.
- data vector는 bit string으로 저장하고, query vector는 4-bit unsigned integer로 양자화하여 inner product를 빠르게 계산할 수 있습니다.
- IVF와 결합할 때 error bound를 이용해 re-ranking 대상을 정할 수 있어, PQ처럼 re-ranking 후보 개수를 데이터셋마다 튜닝할 필요가 줄어듭니다.
- 실험에서는 RaBitQ가 PQ/OPQ보다 짧은 code를 쓰면서도 더 좋은 accuracy-efficiency trade-off를 보였습니다.
[목차]
- Quantization과 PQ의 한계
- RaBitQ의 핵심 아이디
- RaBitQ의 거리 추정 방법
- 효율적인 구현
- ANN search에서의 활용
- 실험 결과
- 나의 생각
Quantization과 PQ의 한계
앞에서 이야기했듯이 quantization의 목표는 원본 float vector를 짧은 code로 바꾸고, 이 code만으로 query와의 거리를 빠르게 근사하는 것입니다.
Product Quantization(PQ)은 이 목적에 가장 널리 쓰인 방법 중 하나입니다. PQ는 벡터를 \(M\)개의 sub-vector로 나누고, 각 sub-vector를 sub-codebook의 centroid 중 하나로 매핑합니다.
original vector
[x1, x2, ..., xD]
split
[sub-vector 1] [sub-vector 2] ... [sub-vector M]
quantize
[code 1] [code 2] ... [code M]query가 들어오면 각 sub-codebook에 대해 lookup table을 만들고, data vector의 code를 이용해 table lookup만으로 거리를 근사합니다. 이 구조는 빠르고 IVF처럼 많은 code를 scan하는 상황에서는 SIMD 최적화와도 잘 맞습니다.
다만 RaBitQ가 문제 삼는 지점은 “근사 거리와 실제 거리의 오차가 작을 것이라고 보증할 수 있는가?”입니다. PQ가 이론적 error bound를 주기 어려운 이유는 크게 두 가지입니다.
첫째, PQ의 codebook은 보통 KMeans 같은 heuristic optimization으로 학습됩니다. 각 sub-vector 공간에서 centroid를 잘 찾는 것이 목표이지만, 이 과정은 데이터 분포와 학습 결과에 강하게 의존합니다. 따라서 어떤 data vector가 자신의 quantized vector와 얼마나 멀어질지, 그 오차가 query 방향에서 어떻게 나타날지를 bound하기 어렵습니다.
둘째, PQ의 distance estimation은 quantized vector를 원래 data vector처럼 취급합니다. 즉 원래 계산하고 싶은 값은 query \(q\)와 원본 vector \(o\) 사이의 거리인데, 실제로는 \(o\) 대신 quantized vector \(\bar{o}\)를 사용해 거리를 근사합니다. 직관적으로는 자연스럽지만, \(\bar{o}\)가 \(o\)를 어떤 방향으로 얼마나 왜곡했는지에 따라 query와의 거리 오차가 달라집니다. 이 estimator가 unbiased라는 보장도 없고, 모든 data/query pair에 대해 오차가 일정 범위 안에 들어온다는 보장도 없습니다.
논문에서는 MSong 데이터셋에서 PQ 계열 방법이 크게 실패하는 예시를 보여줍니다. PQ Fast Scan을 사용했을 때 평균 relative error가 50%를 넘고, re-ranking을 적용해도 recall이 60%를 넘지 못합니다.
RabitQ의 핵심 아이디어
PQ는 데이터 분포에 맞는 codebook을 학습합니다. 반면 RaBitQ는 randomized codebook을 만듭니다. 랜덤을 사용해 데이터 분포에 독립적인 codebook을 만들어 기존에 존재하는 수학 분석 툴들을 사용할 수 있게 되었고, 이를 통해 오차의 theoretical bound를 유도하였습니다.
RaBitQ가 원하는 것은 다음 두 가지입니다.
- 거리 추정값이 unbiased일 것
- 거리 추정 오차에 대한 theoretical bound가 있을 것
이를 위해 RaBitQ는 세 단계를 사용합니다.
- raw vector를 unit vector로 normalization합니다.
- bi-valued vector들을 random orthogonal matrix로 회전시켜 codebook을 만듭니다.
- quantized vector와 query 사이의 inner product를 보정하여 원래 vector와 query 사이의 inner product를 추정합니다.
Normalization
RaBitQ는 먼저 raw data vector를 centroid 기준으로 unit vector로 바꿉니다. 논문 설명의 가장 단순한 형태에서는 전체 데이터셋의 centroid 하나를 \(c\)로 둡니다. 이 centroid는 보통 data vector들의 평균으로 생각하면 됩니다.
data vector를 \(o_r\), query vector를 \(q_r\), centroid를 \(c\)라고 하면 다음과 같이 normalization합니다.
\[o = \frac{o_r - c}{\|o_r - c\|}\]
\[q = \frac{q_r - c}{\|q_r - c\|}\]
이렇게 하면 raw vector 사이의 squared distance는 다음과 같이 표현할 수 있습니다.
\[\begin{aligned}\|o_r - q_r\|^2&= \|(o_r - c) - (q_r - c)\|^2 \\&= \|o_r - c\|^2 + \|q_r - c\|^2- 2\|o_r - c\|\|q_r - c\|\langle o, q\rangle\end{aligned}\]
여기서 \(\|o_r - c\|\)는 index phase에 미리 계산할 수 있고, \(\|q_r - c\|\)는 query phase에서 한 번 계산하면 됩니다.
결국 문제는 normalized vector 사이의 inner product \(\langle o, q\rangle\)를 어떻게 잘 추정할 것인가로 바뀝니다.
centroid 개수는 RaBitQ 자체의 고정값이라기보다는 index나 구현에서 정하는 hyper-parameter입니다. 논문 실험에서는 million-scale dataset에 대해 Faiss 권장 설정을 따라 IVF cluster 수를 4,096개로 둡니다. 반면 어떤 구현에서는 normalization 또는 coarse grouping 용도로 KMeans centroid를 16개처럼 더 작게 둘 수도 있습니다.
요약하면 RabitQ는 비교하려는 data vector와 query vector를 같은 centroid 기준으로 unit vector로 바꾼 뒤 그 위에서 inner product를 추정합니다.
Randomized Bi-Valued Codebook
RaBitQ의 codebook은 다음과 같은 bi-valued vector들의 집합에서 시작합니다.
\[C = \left\{-\frac{1}{\sqrt{D}}, +\frac{1}{\sqrt{D}}\right\}^D\]
각 coordinate가 \(-1/\sqrt{D}\) 또는 \(+1/\sqrt{D}\) 중 하나인 \(D\)차원 vector입니다. 가능한 조합이 \(2^D\)개이므로 매우 큰 codebook입니다.
이 codebook은 unit hypersphere 위의 hypercube vertices로 볼 수 있습니다. 여기에 random orthogonal matrix \(P\)를 곱해 codebook 전체를 랜덤하게 회전시킵니다.
\[C_{\mathrm{rand}} = \{Px \mid x \in C\}\]
orthogonal matrix는 회전 변환이므로 vector의 길이를 바꾸지 않습니다. 따라서 codebook vector들은 여전히 unit vector입니다. 동시에 random rotation 덕분에 codebook이 특정 방향에 치우치는 문제가 완화됩니다.
data vector \(o\)를 quantize할 때는 \(C_{\mathrm{rand}}\)에서 가장 가까운 vector를 찾으면 됩니다. 그런데 \(2^D\)개를 모두 비교할 수는 없습니다. RaBitQ는 orthogonal transformation이 inner product를 보존한다는 점을 이용합니다.
\(Px\) (codebook으로 quantized된 o)와 \(o\)의 inner product를 최대화하는 것은 \(x\) (회전 행렬 사용 전 codebook으로 quantized된 o)와 \(P^{-1}o\)의 inner product를 최대화하는 것과 같습니다.
\[\arg\max_{x \in C}\langle o, Px\rangle=\arg\max_{x \in C}\langle P^{-1}o, x\rangle\]
따라서 \(P^{-1}o\)의 각 coordinate 부호만 보면 됩니다.
\[P^{-1}o = [+, -, +, +, \ldots]\]
quantization code = 1011...이렇게 data vector 하나가 \(D\)-bit string으로 표현됩니다 (\(x\)). 회전행렬이 적용된 codebook으로 양자화된 data vector는 저 string에 P를 적용한 벡터입니다.
RaBitQ의 거리 추정 방법
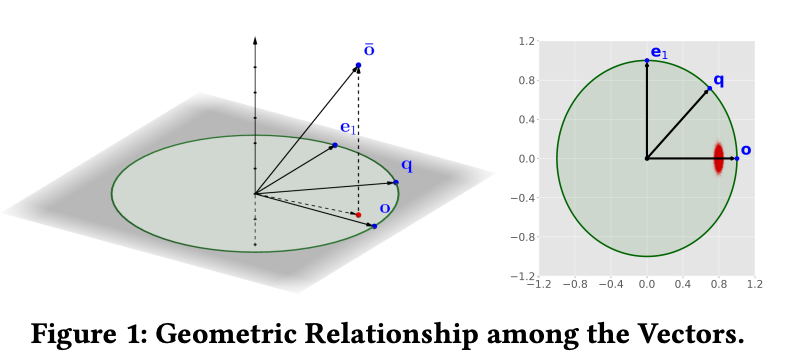
RaBitQ에서 가장 중요한 부분은 estimator입니다.
normalized data vector를 \(o\), normalized query vector를 \(q\), 그리고 RaBitQ codebook에서 선택된 quantized data vector를 \(\bar{o}\)라고 하겠습니다. 목표는 \(\langle o, q\rangle\)를 추정하는 것입니다. 앞에서 본 것처럼 raw vector 사이의 squared distance는 결국 normalized vector 사이의 inner product로 환원되기 때문입니다.
PQ처럼 단순히 \(\langle \bar{o}, q\rangle\)를 \(\langle o, q\rangle\)의 추정값으로 쓰면 biased estimator가 됩니다. RaBitQ는 \(\bar{o}\)와 \(q\)의 inner product를 그대로 쓰지 않고, 다음 값을 estimator로 사용합니다.
\[\langle o, q\rangle \approx \frac{\langle \bar{o}, q\rangle}{\langle \bar{o}, o\rangle}\]
여기서 \(\langle \bar{o}, o\rangle\)는 data vector와 그 quantized vector 사이의 inner product입니다. data vector마다 index phase에 미리 계산해둘 수 있습니다.
왜 \(\langle \bar{o}, o\rangle\)로 나누는 것이 필요할까요? 논문은 \(\bar{o}\), \(o\), \(q\)의 기하학적 관계를 먼저 봅니다. \(\langle \bar{o}, q\rangle\)에 영향을 주는 것은 \(\bar{o}\) 전체가 아니라, \(o\)와 \(q\)가 span하는 2차원 subspace 위의 projection입니다. 이 subspace 밖에 있는 \(\bar{o}\)의 성분은 \(q\)와 직교하므로 \(\langle \bar{o}, q\rangle\)에 영향을 주지 않습니다.
일반적인 경우에는 \(q\)를 \(o\) 방향 성분과 그에 수직인 성분으로 나눕니다. 논문에서는 \(o\)에 수직이고 norm이 1인 vector를 \(e_1\)로 둡니다.
\[e_1=\frac{q - \langle q, o\rangle o}{\|q - \langle q, o\rangle o\|}\]
그러면 \(q\)는 다음처럼 분해됩니다.
\[q=\langle o, q\rangle o+\sqrt{1 - \langle o, q\rangle^2}\, e_1\]
여기에 \(\bar{o}\)와의 inner product를 취하면 다음 관계가 나옵니다.
\[\langle \bar{o}, q\rangle=\langle \bar{o}, o\rangle \langle o, q\rangle+\langle \bar{o}, e_1\rangle\sqrt{1 - \langle o, q\rangle^2}\]
첫 번째 항은 우리가 원하는 \(\langle o, q\rangle\)에 \(\langle \bar{o}, o\rangle\)가 곱해진 형태입니다. 두 번째 항은 \(q\)의 \(o\) 수직 방향 성분 때문에 생기는 항입니다.
양변을 \(\langle \bar{o}, o\rangle\)로 나누면 다음과 같습니다.
\[\frac{\langle \bar{o}, q\rangle}{\langle \bar{o}, o\rangle}=\langle o, q\rangle+\sqrt{1 - \langle o, q\rangle^2}\cdot\frac{\langle \bar{o}, e_1\rangle}{\langle \bar{o}, o\rangle}\]
따라서 RaBitQ estimator의 error term은 명시적으로 다음과 같이 드러납니다.
\[\sqrt{1 - \langle o, q\rangle^2}\cdot\frac{\langle \bar{o}, e_1\rangle}{\langle \bar{o}, o\rangle}\]
여기서 \(\langle \bar{o}, o\rangle\)는 index phase에 미리 계산할 수 있습니다. \(\langle \bar{o}, q\rangle\)도 query phase에서 빠르게 계산할 수 있습니다. 반면 \(\langle \bar{o}, e_1\rangle\)는 직접 계산하기 어렵습니다. \(e_1\)이 \(o\)와 \(q\) 모두에 의존하기 때문에, 이를 정확히 계산하려면 query phase에서 원본 \(o\)에 접근해야 합니다.
RaBitQ는 이 항을 직접 계산하지 않고, random codebook의 성질로 분석합니다. \(\bar{o}\)는 random orthogonal matrix \(P\)에 의해 만들어진 randomized codebook에서 선택된 vector입니다. 논문 본문에서는 이 randomization 때문에 다음 성질이 성립한다고 설명합니다. (아래 내용에 대한 증명은 별도의 technical report를 통해 설명하고 있고, 이 글에서는 생략하도록 하겠습니다)
- \(\langle \bar{o}, o\rangle\)는 대략 0.8 근처에 집중됩니다.
- \(\langle \bar{o}, e_1\rangle\)의 expectation은 0입니다.
- 두 값은 high probability로 expectation에서 크게 벗어나지 않습니다.
즉 \(\langle \bar{o}, e_1\rangle\) 항은 평균적으로 0이고, concentration에 의해 크기도 제한됩니다. 그래서 \(\langle \bar{o}, q\rangle / \langle \bar{o}, o\rangle\)를 \(\langle o, q\rangle\)의 estimator로 사용할 수 있습니다.
RabitQ는 이를 이용해 estimator가 unbiased임을 보입니다.
\[\mathbb{E}\left[\frac{\langle \bar{o}, q\rangle}{\langle \bar{o}, o\rangle}\right]=\langle o, q\rangle\]
또한 다음과 같은 probabilistic error bound를 제공합니다.
\[\Pr\left[\left|\frac{\langle \bar{o}, q\rangle}{\langle \bar{o}, o\rangle}- \langle o, q\rangle\right|>\sqrt{\frac{1 - \langle \bar{o}, o\rangle^2}{\langle \bar{o}, o\rangle^2}}\cdot\frac{\epsilon_0}{\sqrt{D - 1}}\right]\le2e^{-c_0\epsilon_0^2}\]
\(\epsilon_0\)는 failure probability를 조절하는 parameter이고, \(c_0\)는 상수입니다. \(\langle \bar{o}, o\rangle\)가 0.8 근처에 집중된다는 점을 감안하면, 위 bound는 간단히 다음처럼 볼 수 있습니다.
\[\frac{\langle \bar{o}, q\rangle}{\langle \bar{o}, o\rangle}- \langle o, q\rangle=O\left(\frac{1}{\sqrt{D}}\right)\quad \text{with high probability}\]
이 bound가 중요한 이유는 두 가지입니다.
첫째, 데이터 분포에 의존하지 않는 additive bound입니다. PQ처럼 특정 데이터셋에서만 잘 동작한다고 기대하는 것이 아니라 estimator 자체가 보장합니다.
둘째, \(D\)-bit code를 사용할 때 asymptotically optimal한 수준의 bound입니다. 선행 논문에 따르면 \(D\)차원 vector를 \(D\)-bit short code로 표현하는 경우, constant failure probability 하에서 (실패 확률을 상수 수준으로 허용할 때 - 여기서는 epsilon 값을 이용해 조정했죠) \(O(1/\sqrt{D})\)보다 더 좋은 bound를 보장할 수 없습니다.
효율적인 구현
이론적 보장만 있고 느리다면 실용성이 떨어집니다. RaBitQ의 장점은 이 estimator를 빠르게 계산할 수 있다는 점입니다.
data vector의 quantization code는 \(D\)-bit string입니다. query vector는 \(P^{-1}q\)로 변환한 뒤, 각 coordinate를 \(B_q\)-bit unsigned integer로 scalar quantization합니다. 논문에서는 \(B_q = 4\)면 충분하다고 보입니다.
여기서 data side의 bit 수와 query side의 \(B_q\)는 구분해서 봐야 합니다.
Data side에서 RaBitQ의 기본 code는 \(D\)-bit입니다. 즉 \(D\)차원 vector라면 각 차원마다 sign 하나를 저장하므로, 원래 차원 기준으로 보면 1 bit per dimension입니다. 반면 \(B_q\)는 data code length가 아니라 query side의 정밀도를 뜻합니다.
Query는 매번 들어오므로 disk나 index에 저장할 필요가 없습니다. 하지만 \(\langle \bar{o}, q\rangle\)를 빠르게 계산하려면 query도 bit 연산에 맞는 형태로 바꿔야 합니다. 그래서 \(q' = P^{-1}q\)의 각 coordinate를 \(B_q\)-bit unsigned integer로 quantize합니다. 논문 기본값인 \(B_q = 4\)는 query coordinate 하나를 0부터 15까지의 정수로 표현한다는 뜻입니다.
예를 들어 \(D=128\)이라고 해보겠습니다. \(B_q=4\)이면 data side는 128-bit code를 저장하고, query side는 128개의 coordinate를 각각 4-bit 정수로 표현합니다. 여기서 \(B_q\)를 8로 늘려도 data side는 여전히 128-bit code입니다. 달라지는 것은 query coordinate가 0부터 255까지의 8-bit 정수로 표현된다는 점입니다.
D = 128, B_q = 4
data code: 128 bits
query code: 128 coordinates x 4 bits
D = 128, B_q = 8
data code: 128 bits
query code: 128 coordinates x 8 bits따라서 data side bit budget을 늘리고 싶다면 \(B_q\)를 키우는 것이 아니라, 앞에서 설명한 padding처럼 data code length 자체를 늘려야 합니다.
이제 필요한 것은 bit string인 data code와 \(B_q\)-bit integer vector인 query code 사이의 inner product입니다. 논문 기본값인 \(B_q = 4\)를 기준으로 보면, query code는 4-bit integer vector가 됩니다.
4-bit integer는 bit plane으로 나눌 수 있습니다.
query code
4-bit integer vector
bit plane decomposition
bit 0 plane
bit 1 plane
bit 2 plane
bit 3 plane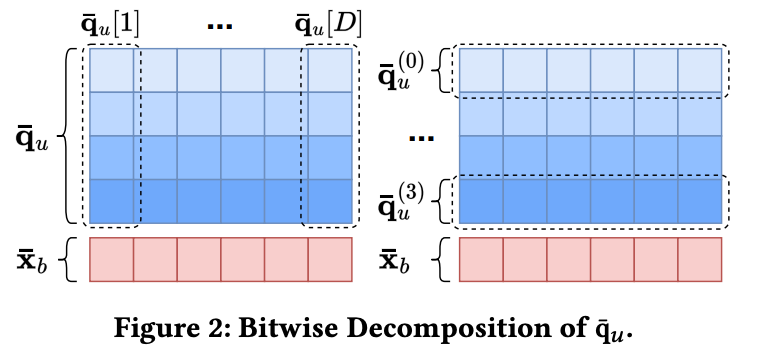
\(B_q\)-bit integer vector인 \(q_u\)를 \(B_q\)개의 binary vector로 분해한 뒤, 각 binary vector와 data bit string \(x_b\)를 `bitwise-and`합니다. 둘 다 0/1 vector이므로, `AND` 결과에서 1의 개수를 세면 해당 bit plane에서 \(x_b\)와 겹치는 위치의 개수를 얻을 수 있습니다.
\[\operatorname{popcount}\left(\texttt{data\_bits}\mathbin{\&}\texttt{query\_bit\_plane}\right)\]
예를 들어 \(x_b=[1,0,1,0]\), \(q_u=[9,2,6,5]\)라면 직접 계산한 dot product는 다음과 같습니다.
\[\langle x_b, q_u\rangle = 1\cdot9 + 0\cdot2 + 1\cdot6 + 0\cdot5 = 15\]
같은 값을 bit plane 방식으로도 얻을 수 있습니다. \(q_u\)의 각 integer를 binary bit plane으로 나누고, 각 plane에서 `AND + popcount`를 수행한 뒤 \(2^j\) 가중치를 곱해 더합니다.
\[\langle x_b, q_u\rangle=\sum_{j=0}^{B_q-1}2^j \cdot\operatorname{popcount}\left(x_b \mathbin{\&} q_u^{(j)}\right)\]
즉 bitwise 구현은 integer dot product를 bit 단위로 분해해서 같은 값을 더 빠르게 계산하는 방식입니다.
이 연산은 대부분의 CPU에서 매우 빠르게 지원됩니다. 논문에서는 이 방식을 RaBitQ-single 구현으로 설명합니다. RaBitQ-single은 query 하나와 data code 하나 사이의 approximate distance를 계산하는 방식입니다. Data code를 하나씩 평가해야 하는 상황에서는 이 구현이 자연스럽습니다. 논문에서는 같은 accuracy에 도달할 때 RaBitQ single-code 구현이 PQ/OPQ보다 평균 3배 빠르다고 보고합니다.
반대로 한 query에 대해 여러 data code를 한 번에 평가할 수 있다면 RaBitQ-batch를 사용할 수 있습니다. Batch mode에서는 여러 data code를 packed layout으로 모아두고, 각 code를 4-bit chunk 단위로 나눕니다.
D-bit RaBitQ code
-> [4 bits] [4 bits] [4 bits] ...각 4-bit chunk는 가능한 pattern이 16개뿐입니다. 따라서 query가 들어오면 각 chunk 위치마다 16개 pattern에 대한 lookup table을 만들 수 있습니다. 이후 packed data codes에 대해 SIMD shuffle을 사용해 lookup과 accumulation을 빠르게 수행합니다. 이 구조는 PQ Fast Scan이 4-bit PQ code를 SIMD register 안의 lookup table로 처리하는 방식과 거의 같은 형태입니다.
실제로 RaBitQ-batch를 쓸 수 있으려면 “한 query에 대해 한 번에 평가할 data code들이 충분히 모여 있어야” 합니다. 대표적인 경우가 IVF입니다. IVF에서는 query가 가까운 cluster 몇 개를 고른 뒤, 그 cluster의 inverted list 안에 있는 vector들을 쭉 scan합니다. 이때 list 안의 data code들은 batch로 묶기 쉽기 때문에 RaBitQ-batch를 적용하기 좋습니다.
반대로 HNSW 같은 graph-based index에서는 search가 greedy하게 진행됩니다. 현재 node의 neighbor를 보고, 그 결과에 따라 다음에 방문할 node가 runtime에 결정됩니다. 이런 경우에는 미리 큰 batch를 만들기 어렵고, data code를 하나씩 평가하는 일이 많습니다. 이때는 RaBitQ-single의 빠른 `AND + popcount` 구현이 더 자연스럽습니다.
정리하면 다음과 같습니다.
- IVF처럼 후보가 inverted list 단위로 모이는 경우: RaBitQ-batch가 잘 맞습니다.
- brute-force reranking 전 후보 pool을 한 번에 scan하는 경우: RaBitQ-batch를 쓰기 좋습니다.
- HNSW/graph search처럼 다음 후보가 탐색 중에 동적으로 결정되는 경우: RaBitQ-single이 더 쓰기 쉽습니다.
- batch를 쓰려면 data code layout을 SIMD 친화적으로 packing해두는 전처리가 필요합니다.
이 점은 실제 시스템에서 중요한데, RaBitQ가 단순히 이론적인 방법에 그치지 않고, IVF 같은 list-scan 기반 구조에서 throughput을 높일 수 있기 때문입니다. 반대로 graph 기반 인덱스와 결합할 때는 batch를 만들기 어려운 문제가 있어, 논문에서도 graph-based method와의 결합은 future work로 남겨둡니다.
참고: Data code length를 늘리는 padding
위의 single/batch 구현 설명은 \(D\)-bit code가 이미 정해져 있다고 보고, 그 code를 빠르게 계산하는 방법에 관한 이야기였습니다. 이와 별도로, 실험이나 실제 압축 설정에서는 원래 차원 기준으로 4 bit per dimension, 8 bit per dimension처럼 더 큰 bit budget을 쓰고 싶을 수 있습니다.
RaBitQ에서 data side bit budget을 늘리는 방법은 \(B_q\)를 키우는 것이 아닙니다. Raw vector 뒤에 0을 padding해서 더 높은 차원 \(D'\)로 만든 뒤, 그 \(D'\)차원 vector에 대해 RaBitQ code를 생성합니다.
예를 들어 원래 vector가 4차원이라고 해보겠습니다.
\[o = [x_1, x_2, x_3, x_4]\]
기본 RaBitQ는 4-bit code를 만듭니다. 만약 원래 차원 기준으로 2 bit per dimension에 해당하는 bit budget을 쓰고 싶다면, 0을 붙여 8차원 vector처럼 만듭니다.
\[o' = [x_1, x_2, x_3, x_4, 0, 0, 0, 0]\]
그리고 \(D'=8\)차원에서 RaBitQ를 적용하면 8-bit code가 나옵니다. 이 방식은 coordinate 하나를 4개 level이나 16개 level로 quantize하는 일반적인 2-bit/4-bit scalar quantization과는 다릅니다. RaBitQ는 padding 이후에도 각 coordinate를 여전히 두 값 중 하나로만 표현합니다. 대신 더 높은 차원에서 더 많은 sign bit를 관찰하는 방식입니다.
이 구분은 성능 실험을 읽을 때 중요합니다. RaBitQ에서도 padding으로 code length를 늘리면 distance estimation error bound가 \(O(1/\sqrt{D'})\) 형태로 좋아질 수 있습니다. 다만 이 논문에서 padding 자체가 recall을 얼마나 올리는지를 별도 ablation으로 직접 보여주지는 않습니다.
ANN search에서의 활용
논문에서는 RaBitQ를 IVF index와 결합합니다.
IVF는 먼저 data vector들을 KMeans로 여러 cluster에 나눕니다. query가 들어오면 query와 가까운 cluster 몇 개를 probe하고, 그 안에 있는 vector들만 후보로 봅니다.
참고로 IVF는 단독으로 모든 것을 해결하는 알고리즘이라기보다는, 검색 공간을 먼저 줄이는 coarse search 구조에 가깝습니다. IVF 기반 ANN 방법들은 보통 inverted list 안에서 어떤 방식으로 후보 거리를 계산하느냐에 따라 나뉩니다.
- IVF-Flat: IVF로 bucket을 줄인 뒤, bucket 안에서는 원본 vector와 exact distance를 계산합니다.
- IVF-PQ: bucket 안의 vector를 PQ code로 압축하고, PQ 기반 approximate distance를 계산합니다.
- IVF-OPQ: PQ 전에 rotation을 적용해 quantization error를 줄인 뒤 IVF-PQ처럼 검색합니다.
- IVF-SQ: PQ 대신 scalar quantization으로 각 dimension 값을 줄여 저장하고 approximate distance를 계산합니다.
- IVF-PQ Fast Scan: 4-bit PQ code와 SIMD shuffle을 활용해 IVF-PQ의 distance scan을 빠르게 만듭니다.
- IVF-RaBitQ: bucket 안의 vector를 RaBitQ code로 표현하고, error bound를 이용해 re-ranking 후보를 결정합니다.
이전에 HNSW와 SPANN을 다룰 때도 봤듯이, ANN 시스템은 보통 coarse search와 fine search가 분리되어 있습니다. 먼저 전체 공간에서 볼 만한 후보 영역을 줄이고, 그 안에서 더 정확한 거리 계산이나 re-ranking을 수행합니다.
RaBitQ를 IVF와 결합하면 흐름은 다음과 같습니다.
Index phase
1. KMeans로 IVF cluster 생성
2. cluster centroid 기준으로 data vector normalization
3. RaBitQ code 생성
4. norm(o_r - c), dot(o_bar, o) 등 precompute
Query phase
1. query와 가까운 IVF cluster 선택
2. 각 cluster 기준으로 query normalization
3. RaBitQ code로 approximate distance 계산
4. 필요한 후보만 원본 vector로 exact distance re-ranking여기서 흥미로운 부분은 re-ranking입니다.
PQ/OPQ는 보통 estimated distance가 작은 상위 N개 후보를 re-ranking합니다. 문제는 이 N을 데이터셋마다 튜닝해야 한다는 점입니다. 어떤 데이터셋에서는 1,000개면 충분하지만, 어떤 데이터셋에서는 더 많이 봐야 합니다.
RaBitQ는 error bound가 있기 때문에 re-ranking 대상을 좀 더 정밀하게 고를 수 있습니다. 어떤 후보 vector의 estimated distance와 error bound를 이용하면, 이 후보의 실제 distance가 가질 수 있는 lower bound를 계산할 수 있습니다. 만약 이 lower bound가 현재 best exact distance보다 크다면, 이 후보는 nearest neighbor가 될 수 없습니다. 따라서 re-ranking하지 않고 버릴 수 있습니다.
반대로 lower bound가 현재 best보다 작거나 같다면, 실제로 더 가까울 가능성이 있으므로 원본 vector로 exact distance를 계산합니다.
실험 결과
논문에서는 여섯 개의 public real-world dataset을 사용해 RabitQ의 성능을 측정합니다.
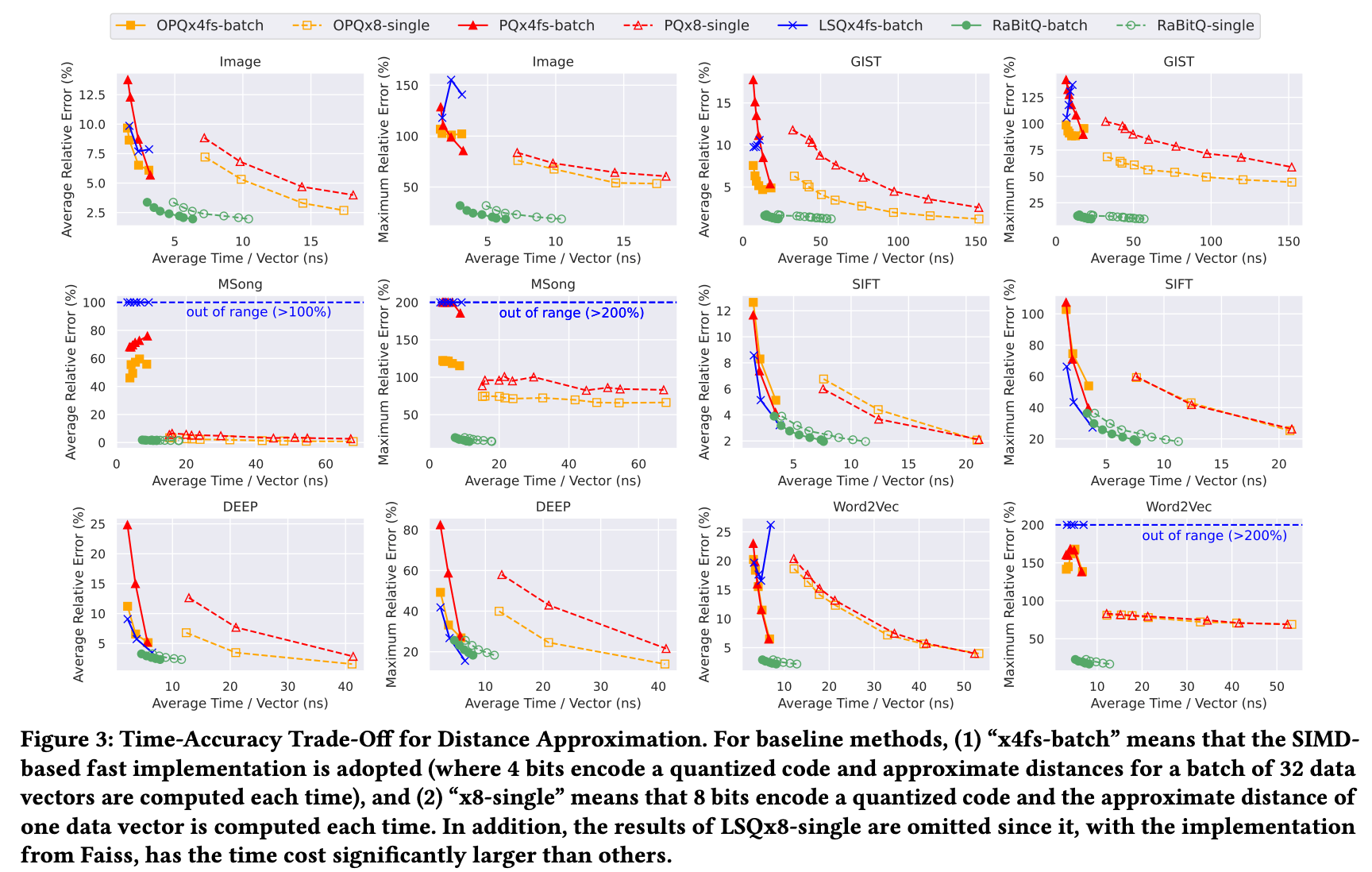
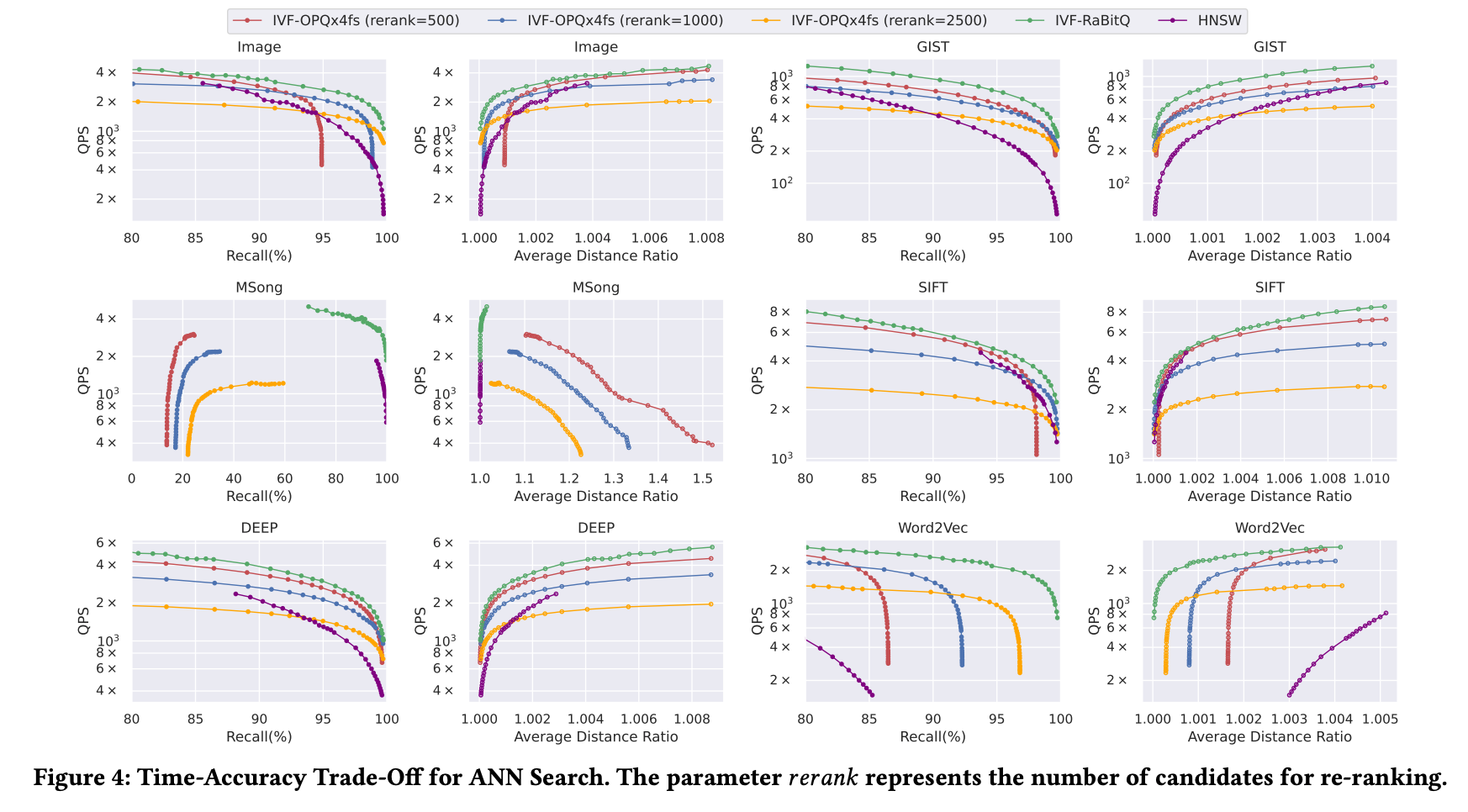
실험 결과의 핵심은 다음과 같습니다.
첫째, RaBitQ는 기본 설정에서 PQ/OPQ보다 짧은 code를 사용합니다. RaBitQ는 대략 \(D\)-bit code를 사용하고, PQ/OPQ는 기본적으로 \(2D\)-bit code를 사용합니다. 그런데도 RaBitQ가 모든 테스트 데이터셋에서 더 좋은 accuracy를 보였습니다.
둘째, 같은 accuracy를 달성할 때 RaBitQ가 PQ/OPQ보다 빠릅니다. 특히 single vector distance estimation에서는 bitwise operation 덕분에 평균 3배 빠른 결과를 보였습니다.
셋째, PQ/OPQ는 일부 데이터셋에서 매우 불안정했습니다. 특히 MSong에서는 PQx4fs와 OPQx4fs의 정확도가 크게 무너졌고, ANN search에서도 OPQ는 re-ranking을 적용해도 좋지 않은 recall을 보였습니다. 반면 RaBitQ는 모든 데이터셋에서 안정적으로 동작했습니다.
넷째, maximum relative error 관점에서도 RaBitQ가 안정적입니다. SIFT와 DEEP을 제외하면 PQx4fs와 OPQx4fs의 maximum relative error가 약 100% 수준까지 올라갔지만, RaBitQ는 테스트한 모든 데이터셋에서 maximum relative error가 40% 이하였습니다.
다섯째, indexing time도 나쁘지 않습니다. GIST 데이터셋에서 RaBitQ는 117초, PQ는 105초, OPQ는 291초가 걸렸습니다. LSQ는 24시간 내에 끝나지 않았습니다.
마지막으로 논문은 이론 분석이 실제 결과와 잘 맞는지도 검증합니다. \(\epsilon_0 = 1.9\) 근처에서 거의 완벽한 recall을 보였고, query scalar quantization parameter인 \(B_q\)는 4 정도면 error가 빠르게 수렴했습니다. 또한 RaBitQ의 distance estimator가 unbiased라는 점도 실험적으로 확인했습니다.
나의 생각
개인적으로 이 논문에서 가장 인상적이었던 점은 “학습된 codebook 대신 랜덤 codebook을 사용한다”는 아이디어입니다.
보통 quantization에서는 데이터셋에 더 잘 맞는 codebook을 학습하려고 합니다. 그런데 RaBitQ는 반대로 randomness를 넣어 codebook을 분석 가능한 형태로 만들고, 그 위에서 estimator를 설계했습니다.
실제 서비스에서는 평균 성능만큼이나 worst-case나 tail behavior가 중요합니다. RaBitQ는 랜덤성을 도입해 error bound를 유도해 불확실성을 줄였습니다.
또한 re-ranking 후보 개수를 하이퍼 파라미터로 두지 않고, bound를 이용해 결정하는 부분도 좋았습니다. vector DB를 운영 시 데이터셋마다 embedding 분포와 쿼리 패턴이 다릅니다. re-ranking 후보를 선택하는 방식은 실제로 서비스를 운영해보면서 튜닝하는 수고가 들어가야합니다. RaBitQ의 방식은 이 부담을 줄여줄 수 있습니다.
다만 실제 적용을 생각하면 몇 가지 확인해야 할 점이 있습니다.
첫째, centroid를 고르는 작업이 존재하여 online quantization 작업은 아닙니다. 논문의 additive error bound는 데이터 분포에 의존하지 않지만, relative error 관점에서는 normalization이 잘 되어야 하고 이는 centroid를 얼마나 잘 고르냐에 의존할 수 있습니다. centroid를 몇 개 선택할지, 데이터 입력 분포가 변했을 때 이전에 정했던 centroid를 언제 초기화할지 등 vector DB 운영을 한다면 여전히 고민거리는 남아 있습니다. 참고로 다음 글에서 다룰 TruboQuant는 이 지점을 해결했습니다.
둘째, 논문에서는 IVF와의 결합을 중심으로 다룹니다. HNSW 같은 graph-based index와 결합하는 것은 future work로 남겨두었습니다. graph search에서는 후보를 runtime에 하나씩 따라가며 평가하기 때문에 batch SIMD 최적화를 적용하기 어렵습니다. RaBitQ의 single-code distance estimation이 빠르다는 점은 도움이 되지만, 전체 graph search 알고리즘과 어떻게 잘 맞출지는 별도의 연구가 필요해 보입니다.
그럼에도 RaBitQ는 충분히 흥미로운 논문입니다. 특히 빠른 vector quantization과 이론적 error bound를 동시에 가져가려는 시도가 마음에 들었습니다.
마무리
RaBitQ는 \(D\)차원 vector를 \(D\)-bit string으로 압축하면서도, 거리 추정에 대한 unbiased estimator와 \(O(1/\sqrt{D})\) error bound를 제공합니다. 또한 bitwise operation과 SIMD 기반 구현을 모두 지원해 실제 ANN search에서도 효율적으로 사용할 수 있습니다.
논문을 읽으면서 가장 크게 느낀 점은, randomized algorithm이 단순히 “운에 맡기는 방법”이 아니라는 것입니다. 오히려 적절한 randomness는 구조를 단순하게 만들고, 그 구조 덕분에 강한 이론적 보장을 얻을 수 있습니다.
벡터 검색 시스템을 만들거나 운영한다면, RaBitQ는 PQ의 대안으로 한 번 살펴볼 만한 논문입니다. 특히 데이터셋마다 PQ의 성능 편차가 크거나, re-ranking parameter 튜닝이 부담스러운 상황이라면 더 흥미롭게 볼 수 있을 것 같습니다.
Reference
- RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search
- RaBitQ GitHub
- Product Quantization for Nearest Neighbor Search
- Cache Locality is Not Enough: High-Performance Nearest Neighbor Search with Product Quantization Fast Scan
- Faiss
- HNSW: Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs