
[구글 시리즈] #1. The Google File System(2003)
![[구글 시리즈] #1. The Google File System(2003)](https://images.unsplash.com/photo-1473654729523-203e25dfda10?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fGNodW5rfGVufDB8fHx8MTcyNTcyODcxN3ww&ixlib=rb-4.0.3&q=80&w=2000)
현재 검색 시장뿐만 아니라 다양한 분야를 장악한 구글은 불과 1998년에 설립되었습니다. 구글은 매우 빠른 속도로 성장했고, 이를 위한 인프라 시스템들을 구축했습니다. 구글의 인프라 시스템은 다른 회사 및 개발자에게 많은 영향을 끼쳤습니다. 구글 시리즈는 이러한 논문들 중 일부를 뽑아 소개를 하고자 합니다.
- The Google File System (2003)
- BigTable: A Distributed Storage System for Structured Data (2006)
- The Chubby lock service for loosely-coupled distributed systems (2006)
- Dapper, a Large-Scale Distributed Systems Tracing Infrastructure (2010) (예정)
- Large-scale cluster management at {Google} with {Borg} (2015) (예정)
1. 개요
구글 시리즈에서 제일 첫번째로 다룰 시스템은 Google File System, GFS입니다.
GFS는 구글의 데이터 처리를 만족시키기 위해 디자인된 파일 시스템입니다. GFS는 (1) 고가의 장비가 아닌 일반적인 장비 수백, 수천개로 구성되고 (2) 장비 에러가 일상적으로 발생해도 이상이 없으며 (3) 수 GB 넘는 파일들이 많았음에도 좋은 성능을 보였습니다.
이 논문이 발표된 시기가 2003년임을 고려해보면 정말 대단한 규모입니다.
GFS는 Hadoop의 탄생에도 기여를 하였습니다. Hadoop의 분산 파일 시스템(HDFS)은 GFS의 영향을 받았습니다. 또한 하둡의 기반이 된 MapReduce 패러다임은 2004년 구글의 MapReduce 논문에서 발표된 것으로 GFS를 활용해 MapReduce를 실험하였습니다.
GFS가 발표되었을 당시 분산 시스템에 대한 연구는 많이 이루어져 있었으나 실제 산업에는 적용이 미미했었습니다. GFS는 이러한 기술들을 적용해 (1) 실제 서비스에 사용될 수 있는 성능 (2) 글로벌 단위 (3) 샤딩 가능 (4) Automatic failure recovery가 가능한 첫 구현체입니다.
다만 GFS도 여러 한계가 있었습니다. GFS는 하나의 데이터센터에서 사용되는 것으로 설계되어 있어 구글은 각 데이터센터마다 GFS 클러스터를 두어야 했습니다. 또한 throughput에 중점을 두어 낮은 latency를 요구하는 어플리케이션에는 적합하지 않았습니다.
2. Design
2.1 가정
GFS는 구글의 데이터 처리를 위해 설계되어 다음 조건들을 만족하는 설계를 가지고 있습니다.
(1) 구성 요소의 장애는 예외 상황이 아니라 일상적입니다.
자체적으로 모니터링이 되어야 하며 장애 감지, 자동 복구 등이 되어야 합니다. 파일시스템은 수백, 수천개의 스토리지 머신으로 구성되어 있고 수백, 수천개의 클라이언트에 의해 접근됩니다. 거의 매일 장애가 난다고 가정해도 무리가 없습니다.
(2) 시스템은 수백만개의 파일들을 가지고 있고, 한 파일은 100MB 이상의 크기를 가집니다
수 GB 파일들은 흔하며 큰 파일들이 효율적으로 다뤄져야 합니다. 작은 파일들은 지원되지만 최적화를 할 필요는 없습니다
(3) Read Workload는 두 가지로 나뉩니다.
Large streaming reads: 각각의 operation이 수백 KB를 읽고 1MB 이상을 읽기도 한다. 같은 클라이언트는 연속적인 operation을 통해 파일 내 순차적인 읽기를 하기도 합니다.
Small random reads: 임의의 오프셋에 대해 수 KB를 읽습니다. 성능이 중요한 어플리케이션들은 이런 작은 read들을 배치 및 정렬하여 오프셋을 순차적으로 전진하도록 만들기도 합니다.
(4) Write Workload
매우 크고 연속적인 Write가 주를 이룹니다. 대부분 Append이며 한번 써지면 파일들은 거의 수정되지 않습니다. 파일 내 임의의 offset에 대한 small write는 지원되나 효율적이지 않아도 됩니다.
(5) 시스템은 여러 클라이언트가 병렬적으로 한 파일에 대해 append 할 수 있도록 잘 정의된 semantics를 지원해야 합니다.
파일들은 producer-consumer queue로 사용되거나 many-way merging으로도 쓰입니다. 수백 개의 프로듀서가 파일에 병렬적으로 append 할 수 있어야 합니다.
오버헤드를 최대한 적게 하면서 atomicity를 유지하는 것이 필수적입니다. 파일은 나중에 읽혀질 수도 있고 consumer가 동시에 파일을 읽을 수도 있습니다.
(6) latency보다 bandwidth가 더 중요합니다. 타겟 어플리케이션은 bulk 데이터 처리입니다.
2.2 Architecture
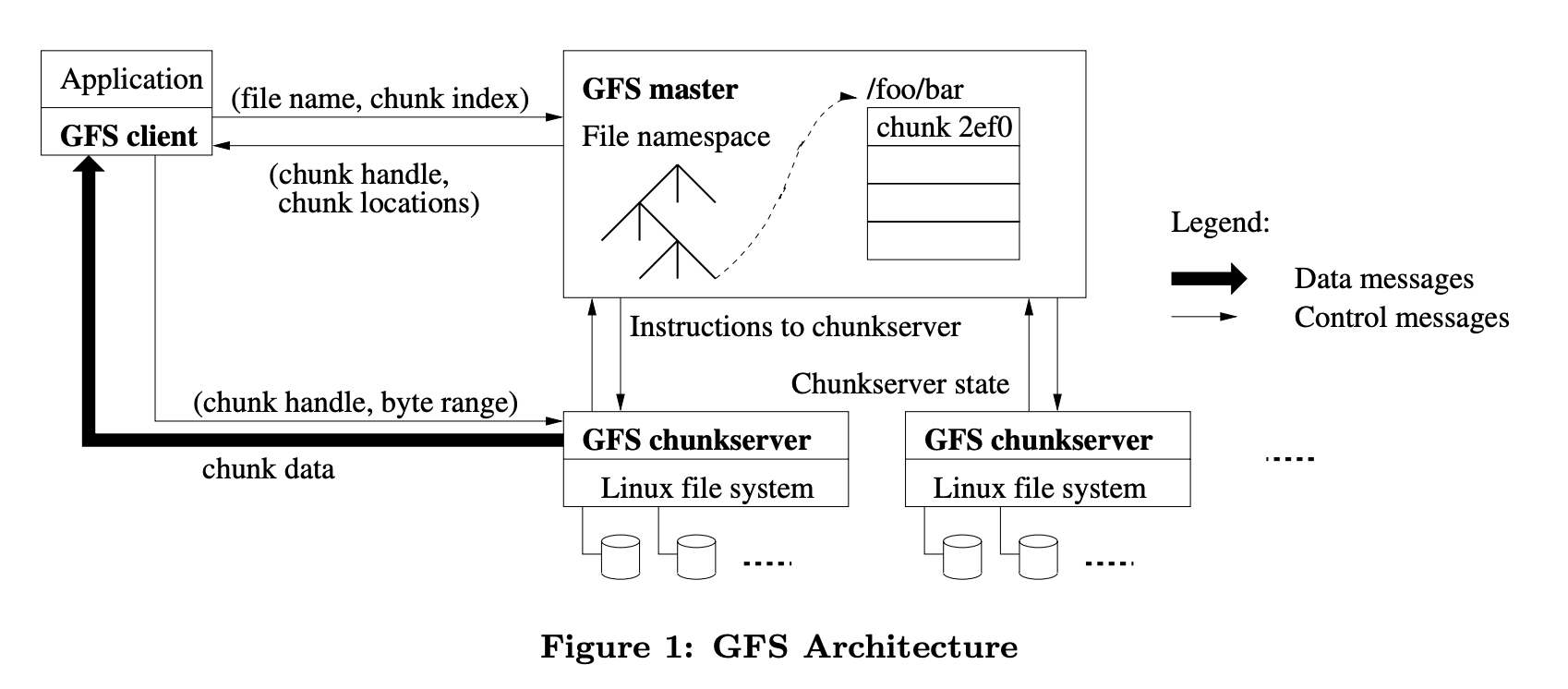
GFS는 한 개의 master와 여러 개의 chunkserver들로 구성되어 있습니다. 각각의 서버들은 유저 레벨 서버 프로세스를 실행하고 있는 일반적인 상업용 리눅스 머신들입니다.
파일들은 고정된 크기의 chunk로 나누어집니다. 각 chunk는 immutable하고 글로벌하게 유일한 64bit chunk handle을 가집니다. 이 chunk handle은 chunk 생성시 master로부터 할당받습니다.
Master를 하나만 가지는 것은 chunk 처리(chunk 배정, replication 복사 등) 복잡성을 줄이기 위해서입니다. 대신 병목을 줄이기 위해 클라이언트는 master 서버와는 metadata를 교환하고 chunkserver에서 직접 데이터를 받아옵니다.
Chunkserver는 chunk를 로컬 디스크에 리눅스 파일로 저장하고 chunk handle는 이 위치를 저장합니다. 각 chunk는 여러 chunkserver에 복사되어 있고, 기본 값으로 3개가 세팅되어 있습니다.
Master는 모든 파일 시스템 메타데이터를 가지고 있습니다. 메타데이터는 chunk에 관한 정보 등을 포함합니다. Master는 chunkserver와 주기적으로 HeartBeat를 보내 메타데이터를 업데이트합니다. 메타데이터는 뒤에서 좀 더 자세하게 말씀드리겠습니다.
클라이언트와 chunkserver 둘 다 파일 데이터를 캐시하지 않습니다. 단순화를 위해 cache coherence 이슈의 여지를 제거한 것입니다. 또한 chunkserver는 리눅스 파일 시스템을 사용하기 때문에 이미 리눅스 buffer cache가 해줘서 따로 필요 없기도 합니다. 단, 클라이언트는 일부 메타데이터를 캐싱합니다.
2.3 Chunk Size
Chunk 크기는 64MB로 일반적인 파일 시스템 블록 크기보다 큽니다.
큰 chunk 크기의 장점은 다음과 같습니다.
(1) 클라이언트와 master간 통신 횟수를 줄일 수 있습니다.
read와 write가 같은 chunk에 이루어질 경우 master에 한번만 질의하면 됩니다.
구글 대부분의 어플리케이션이 큰 파일들을 순차적으로 읽고 쓰기 때문에 매우 중요합니다. 심지어 small random reads에서도 클라이언트는 수 TB working set에 대하여 모든 chunk location을 편하게 캐싱할 수 있습니다.
(2) Chunk 크기가 크면 클라이언트가 한 chunk에 대해 많은 operation을 수행할 확률이 높아지며, 이는 하나의 persistent TCP connection을 유지해 네트워크 오버헤드를 줄일 수 있습니다.
master가 저장하는 메타데이터 크기를 줄여 마스터가 모든 메타데이터를 메모리에 저장할 수 있습니다.
다만 당연하게도 단점도 존재합니다.
작은 파일들은 하나의 chunk를 쓰기 때문에 많은 클라이언트들이 같은 파일에 접근할 때 해당 chunk를 가진 서버가 hotspot이 될 수 있습니다.
실제로는 많은 어플리케이션이 여러 개의 chunk로 되어 있는 파일을 순차적으로 읽어 큰 문제가 되지 않았습니다.
다만 hotspot 문제는 batch-queue system에서 일어났습니다. executable이 GFS에 하나의 chunk 파일로 write되고 수 백개의 머신이 이를 접근한 것이죠. 이러한 executable에 한하여 high replication factor를 두어 대응했다고 합니다.
2.4 Metadata
master는 모든 메타데이터를 메모리에 저장합니다. 그리고 메타데이터는 3가지로 나뉩니다.
- 파일과 chunk namespace
- 파일과 chunk 간 mapping
- 각 chunk 레플리카의 위치
Non-Volatile
namespace와 파일과 chunk간 mapping은 operation log에 persistent하게 저장됩니다. operation log는 마스터의 로컬 디스크와 remote 머신에 레플리카로 저장됩니다. log를 사용하면 master 상태를 consistency 문제 없이 단순하고 신뢰성있게 업데이트 할 수 있습니다.
Volatile
master는 chunk location information을 log에 저장하지 않지만master가 뜨거나 chunkserver가 join할 때 chunkserver로부터 가져옵니다. 또한 주기적으로 chunkserver에게 heartbeat를 보내 업데이트합니다.
처음에는 chunk location information을 persistent하게 가져가려 했으나 이렇게 구현하는 것이 훨씬 단순하다는 것을 깨달았다고 합니다. 주기적으로 업데이트 하는 방식은 master와 chunkserver간 sync 문제를 단순하게 만듭니다.
sync가 깨지는 경우는 chunkserver가 클러스터에 합류/나가거나 이름을 바꾸거나, 실패하거나, 재시작하는 등 많은 경우가 있습니다. 또한 chunkserver가 자신이 어떤 chunk를 가지고 있는지 제대로 인식하지 못할 때도 sync 문제가 생깁니다. chunkserver가 디스크 불능 등으로 에러가 발생해 chunk를 사라지게 만들거나 operator가 chunkserver의 이름을 변경하는 등이 있습니다.
Operation Log
Operation Log는 메타데이터 변경에 대한 historical record를 포함합니다. 그리고 logical time을 정하여 concurrent operation에 대한 순서를 정의하는 역할도 수행합니다. master는 여러 remote 머신에 operation log를 복사합니다.
master는 파일 시스템 상태를 operation log를 replay하면서 복구합니다. 로컬 디스크에서 checkpoint를 로딩하고 그 뒤의 record만 replay하여 startup 시간을 최소화합니다.
checkpoint는 compact B-tree와 비슷한 형태이며 바로 memory에 올릴 수 있고 추가적인 파싱 없이 namespace lookup에 쓸 수 있습니다. 오래된 checkpoint와 로그 파일들은 삭제되지만 최악의 상황을 대비해 몇 개는 유지합니다. checkpoint 만드는 중 발생한 실패는 데이터 정확도에 영향을 미치지 않는데, 복구 코드가 감지하고 미완성된 checkpoint를 스킵하기 때문입니다.
3. Consistency 모델
GFS는 relaxed consistency를 가집니다.
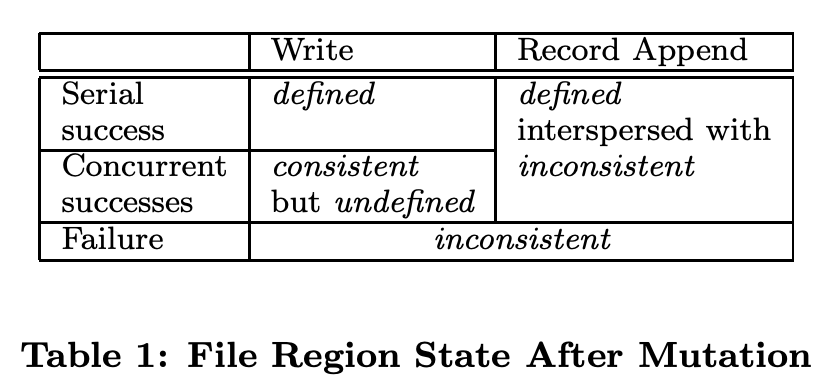
Mutation 이후 파일 Region의 상태는 mutation의 타입, 성공 여부, 병렬 여부에 따라 달라집니다. 상태는 consistent와 defined로 정의됩니다.
Consistent: 모든 클라이언트가 어떤 replica를 읽는지에 관계 없이 항상 같은 상태를 볼 수 있다.
Defined: 파일 데이터 변경 이후 (1) consistent하고 (2) 클라이언트가 변경이 반영된 것을 볼 수 있다.
위 그림에서 concurrent success는 undefined but consistent라고 나와있는데, 이는 모든 클라이언트가 같은 데이터를 보지만 어떤 mutation은 반영이 안되었을 수 있음을 뜻합니다.
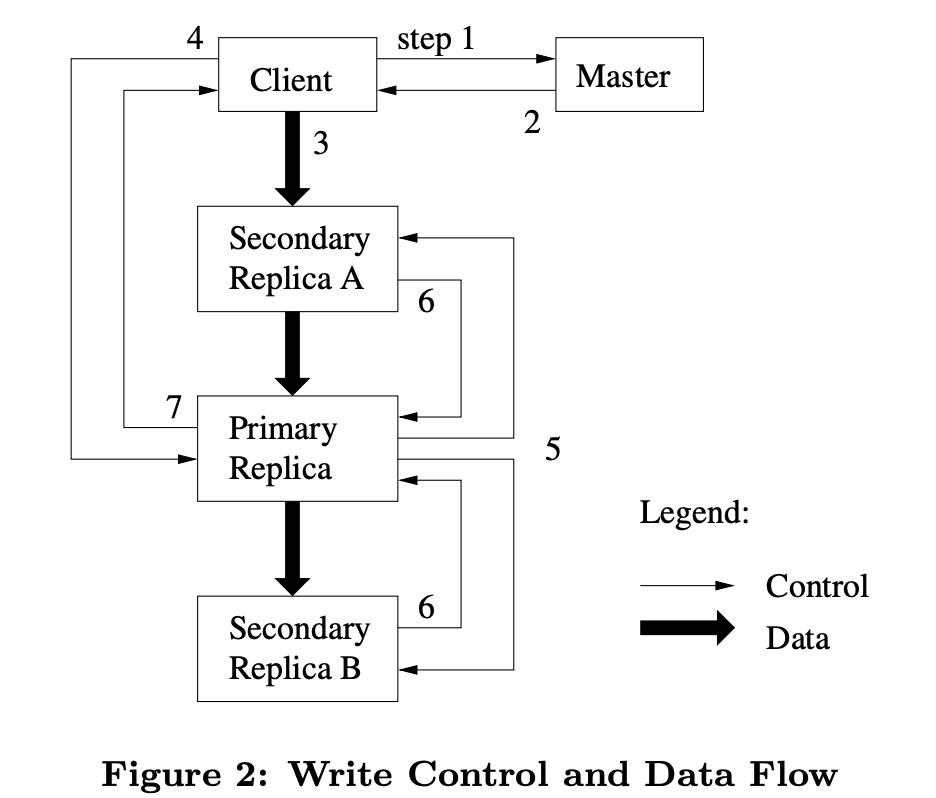
변경은 각 chunk의 replica에서 이루어집니다. replica간 consistent mutation order을 유지하기 위해 lease를 사용합니다. master는 replica 중 하나에게 chunk lease를 부여하는데, chunk lease를 부여받은 replica를 primary라고 합니다. primary는 chunk에 대한 mutation의 순서들 중 하나를 선택하고, 모든 replica들은 이 순서를 따라야 합니다.
lease 메커니즘은 master의 관리 오버헤드를 줄이기 위해 설계되었습니다. lease는 60초의 타임아웃이 존재하지만, chunk가 수정되는 동안 primary는 master에게 timeout 확장을 요청할 수 있습니다. 이 확장 요청은 HeartBeat 메시지를 통해 교환됩니다.
master는 부여한 lease를 취소해야할 상황(ex 파일 이름이 변경되는 동안 mutation 방지)이거나 primary와 통신이 되지 않을 때도 타임아웃으로 새 lease를 다른 replica로 안전하게 전달할 수 있습니다.
Mutation이 반영되는 순서는 다음과 같습니다.
- 클라이언트는 master에게 chunk에 대한 현재 lease를 어떤 chunkserver가 가졌는지와 다른 replica들의 위치를 물어봅니다. 이때 아무도 lease를 가지고 있지 않다면 master는 replica를 하나를 골라 lease를 부여합니다.
- master는 primary와 secondary replica를 응답합니다. 클라이언트는 이 메타데이터를 caching함. 만약 primary가 응답하지 않거나 primary가 lease를 더 이상 가지고 있지 않다고 응답하면 master에 재요청합니다.
- 클라이언트는 모든 replica에 데이터를 push합니다. 이때 push하는 순서는 어떤 순서도 가능합니다. 각 chunkserver는 데이터를 사용되거나 만료될 때까지 내부 LRU buffer cache에 저장합니다. 이렇게 data flow를 control flow와 분리함으로서 어떤 replica가 primary인지 상관 없이 네트워크 토폴로지에 기반한 스케줄링을 통해 성능을 향상시켰습니다.
- 각 머신의 bandwidth를 극대화하기 위해 각 머신은 데이터를 가장 가까운 머신에 전달합니다. 구글의 네트워크 토폴로지에서 거리는 ip 주소를 통해 계산이 가능합니다.
- 모든 레플리카가 데이터를 받았다는 응답을 하면 클라이언트는 write 요청을 primary에게 보냅니다. 이 요청은 모든 레플리카에게 데이터가 이전에 전달됐다는 것을 의미하고, primary는 mutation에 연속적인 serial number를 할당합니다.
- primary는 write 요청을 모든 secondary replica에 전달합니다. 각 secondary replica는 mutation을 같은 serial number order로 적용합니다.
- secondary들은 primary에게 mutation을 적용했다고 응답합니다.
- primary는 클라이언트에게 결과를 응답합니다. 에러가 난 경우에는 클라이언트 요청이 실패했다고 간주되고 수정된 부분이 inconsistent 상태로 남습니다. 클라이언트는 이 실패한 mutation을 재시도하여 에러를 다룹니다. 즉, (3)부터 (7)까지 여러번 재시도합니다.
만약 write가 너무 커서 chunk 경계를 넘어가면 GFS 클라이언트는 여러 write operation으로 쪼갭니다. 이 operation들은 위 control flow를 따르지만 operation들 사이에 다른 클라이언트의 operatiob이 끼워질 수 있습니다. 그래서 replica들 간 상태가 같을 수 있지만 undefined 상태로 남을 수 있는 것입니다.
이 consistency 정책의 이해를 돕기 위해 예를 하나 들겠습니다.
- 3개 레플리카 가정 (A, B, C)
- 두 클라이언트(a, b)가 동시에 쓰는 상황
- a 클라이언트 쓰기 요청(1)이 A, B에만 제대로 들어감.
- b 클라이언트는 쓰기 요청(2)을 모든 레플리카(A, B, C)에 성공
- a 클라이언트는 실패하였으니 다시보내라는 응답을 받음
- a 클라이언트가 다시 쓰기 요청(1)을 A, B, C에 함
- 레플리카들은 전부 살아있지만 다른 순서를 가진 record들을 가진다. C의 경우 첫 요청을 못받아 해당 공간을 blank로 가지기 때문이다.
- 최악의 경우는 다시 보내라는 요청을 받을 클라이언트가 응답을 받기 전 죽어버리면 consistency가 영구히 깨질 수 있다.
위 상황에서 A와 B의 record는 (1, 2, 1), C는 (null, 2, 1) 입니다. 따라서 클라이언트는 Read를 할 때 중복 레코드를 다룰 수 있어야 합니다.
GFS는 Record I/O 관련 라이브러리를 제공하여 어플리케이션 및 다른 파일 인터페이스에서 이를 쉽게 다룰 수 있도록 하였습니다.
4. Feature
4.1 Atomic Record Appends
GFS는 Atomic하게 append를 수행하며 이를 record append라고 합니다.
Record append에서 클라이언트는 write할 때 offset을 포함하지 않고 데이터만 포함합니다. UNIX에서 O_APPEND 모드로 파일을 열면 race condition이 발생하지 않고 쓸 수 있는 것과 유사합니다.
Record append는 아까 본 control flow에서 primary에 로직을 추가하면 구현할 수 있습니다.
(1) 클라이언트가 모든 레플리카에 대해 데이터를 push하고 primary에게 요청을 보낸다.
(2) primary는 현재 chunk에 대한 record append가 최대 크기(64MB)를 넘는지 확인한다. 만약 그렇다면 chunk를 최대 크기로 padding하고 secondary에게도 똑같이 하도록 전달 후 클라이언트에게 다시 시도하라고 응답한다. record append는 최대 크기의 1/4까지로 제한해 fragmentation을 제한한다.
(3) 만약 record가 최대 크기 이내로 들어온다면(대다수의 케이스) primary는 데이터를 replica에 append하며 secondary에게도 같은 오프셋에 append하라고 전달한다.
record append가 하나의 replica에서라도 실패하면 클라이언트는 재시도해야하고 이 경우 위에서 본 것처럼 일부 레플리카는 중복된 내용을 가질 수 있습니다. 그래서 GFS는 모든 replica가 바이트 단위로 동일하다는 것을 보장하지 않습니다. 오직 데이터가 최소 한번 atomic하게 쓰여졌다는 것만을 보장합니다.
4.2 Snapshot
snapshot은 실행중인 mutation의 중단을 최소화하면서 파일 혹은 디렉토리 tree의 복사본을 만드는 것입니다. GFS는 copy-on-write을 사용해 Snapshot을 구현합니다.
master가 snapshot 요청을 받으면 snapshot 요청을 받은 파일 내 chunk에 대한 lease들을 취소시켜 해당 청크들에 대한 연이은 write가 lease holder를 찾기 위해 master로 요청하는 것을 강제합니다.
lease가 취소되거나 만료되면 master는 디스크에 operation을 기록하고 메모리 상태에도 적용합니다. 이 새로 만들어진 snapshot 파일은 source 파일과 같은 chunk를 가리킵니다.
snapshot 요청 완료 후 클라이언트가 해당 chunk에 대해 write 요청할 때 master에게 현재 lease holder가 누군지 물어봅니다. master는 해당 chunk의 reference count가 1보다 큼을 확인합니다. master는 새로운 chunk handle 선택하고, 각 chunk server들에게 해당 chunk의 복사본을 만들라고 요청합니다. 새로운 chunk handle은 이 복사본과 대응됩니다. master는 새 chunk handle을 클라이언트에게 돌려줌으로써 클라이언트는 snapshot된 chunk를 활용할 수 있습니다.
4.3 Namespace Management and Locking
GFS는 여러 master operation을 동시해 수행하기 위해 lock을 사용합니다.
각 master operation은 시작하기 전 set of locks를 갖습니다. 만약 경로 /d1/d2/…/dn/leaf를 포함하면 read-lock을 /d1, /d1/d2, /d1/d2/…/dn 에 대해 얻고 /d1/d2/…/dn/leaf에 대해서는 read, write lock을 둘 다 얻습니다. leaf는 파일일 수도 디렉토리일 수도 있습니다.
/home/user → /save/user로의 snapshot 생성 중 파일 /home/user/foo 생성을 막는 예시를 살펴봅시다.
- snapshot은 /home과 /save에 read lock, /home/user와 /save/user에 write lock을 겁니다.
- 파일 생성은 /home과 /home/user에 read lock, /home/user/foo에 write lock을 겁니다.
- 이 두 operation은 /home/user로의 lock을 얻기 위해 serialized 됩니다.
이 locking 방식의 장점은 같은 디렉토리에서 병렬 mutation이 가능하다는 것입니다. 예를 들어 같은 디렉토리에 여러 파일 생성이 병렬로 가능합니다. 디렉토리 이름에 read lock을 잡고 파일 이름에 write lock을 잡기 때문입니다.
lock은 deadlock을 막기 위해 consistent total order로 잡습니다.
4.4 Garbage Collection
파일이 삭제되면 GFS는 즉시 물리 스토리지를 reclaim하지 않습니다. lazy하게 파일과 chunk level에서 수행합니다.
Mechanism
어플리케이션에 의해 파일이 삭제되면 master는 다른 변경처럼 deletion을 로깅합니다. 이때 즉시 리소스를 reclaim하지 않고 파일의 이름이 삭제 타임스탬프를 포함한 숨겨진 이름으로 변경합니다.
master가 주기적으로 파일 시스템을 스캔할 때 이런 3일 넘게 경과된 숨겨진 파일들을 삭제합니다. 삭제 전까지 이 숨겨진 파일들은 새로운 이름으로 클라이언트에 의해 읽혀질 수 있고 다시 이름을 변경하여 삭제 취소될 수 있습니다. 숨겨진 파일이 완전히 삭제되었을 때 메모리에 메타데이터가 지워집니다.
chunk namespace를 주기적으로 스캔하는 것처럼 master는 어느 파일로부터도 닿을 수 없는 chunk를 판별하고 메타데이터를 지웁니다. master가 hearbeat를 보낼 때 각 chunkserver는 chunk의 subset을 보내는데, master는 이 중 더 이상 메타데이터에 존재하지 않는 chunk를 응답하여 chunkserver가 삭제하도록 합니다.
Discussion
garbage collection은 프로그래밍 언어에서는 어려운 문제지만 GFS는 master에 의해 file-chunk 매핑이 관리되기 때문에 쉽습니다. master가 모르는 replica는 그냥 garbage로 간주합니다.
즉시 삭제에 비해 가지는 장점
- 분산 시스템에서 컴포넌트 실패는 흔합니다. chunk 생성이 일부 server만 성공하면 이 성공한 replica들은 master가 모릅니다. 또한 replica 삭제 메시지도 중간에 유실될 수 있습니다. 모르는 replica에 대해 일관된 방법을 제공한다는 장점이 있습니다.
- master의 background 활동에 스토리지 reclamation이 합쳐질 수 있습니다. 주기적인 namespace 스캔 및 chunkserver와의 handshake가 해당됩니다. 그래서 batch로 이루어질 수 있고 비용이 절약됩니다. 또한 master가 여유있을 때 수행되어 master가 클라이언트 요청에 빠르게 대응 가능합니다다.
- 복구가 가능해 여러 사고를 막을 수 있습니다.
단점
스토리지가 여유가 없을 때 관리하기 어렵습니다. 예를 들어 어플리케이션이 반복적으로 임시 파일을 생성/삭제하는 경우 스토리지 재사용을 하지 못합니다. 이런 케이스는 다음의 방식으로 해결하였다고 합니다.
- 명시적으로 삭제요청이 다시 들어오면 스토리지 reclaimation하도록 함.
- 유저가 namespace마다 replication 및 reclamation 정책 적용할 수 있도록 허용합니다. 즉 어떤 디렉토리 트리에 대해서는 replication이 없게 한다던가, 삭제된 파일은 즉시 파일 시스템에서 삭제할 수 있게 정책을 만들 수 있습니다.
4.5 Stale Replica Detection
각 chunk는 master가 chunk version number를 유지해 stale replica를 탐지할 수 있습니다.
master가 chunk에 새 lease를 부여하면 chunk version number를 증가시키고 모든 replica에 이를 알립니다. 마스터와 replica들은 새 version number를 persistent state에 기록합니다.
master는 chunkserver가 재시작하거나 chunk를 chunkversion과 함께 보고할 때 해당 chunkserver가 가진 chunk가 stale함을 감지할 수 있습니다.
마스터는 stale replica를 garbage collection때 삭제합니다. 또한 삭제 전에도 client에게 응답할 때 stale replica는 포함하지 않고, 응답시 chunkversion을 포함해 operation 수행 전 항상 최신 데이터에 대해 수행할 수 있도록 보장합니다.
4.6 Data integrity
각 chunkserver는 저장한 데이터의 corruption을 감지하기 위해 checksum을 확인합니다.
chunk는 다시 64KB block으로 구성되고 각 block은 32bit checksum을 가집니다. checksum은 메모리에 보관되고 logging으로 영구 보관합니다.
chunkserver는 데이터를 응답할 때 checksum을 검증하여 corruption을 다른 머신으로 전파시키지 않습니다.
chunkserver는 여유 기간에 비활성화된 chunk를 스캔하며 내용을 검증합니다. 이를 통해 가끔 읽히는 chunk의 corruption을 감지할 수 있습니다.
5. Colossus: GFS를 대체한 시스템
Spanner paper(2012)에서 GFS는 Colossus로 대체되었다고 밝혔습니다(참고: spanner 관련 이전 글). 구글이 GFS를 더 이상 사용하지 않게된 이유는 무엇이었을까요?
구글이 GFS를 약 10년간 사용하는 동안 구글의 workload도 많은 변화가 있었습니다. GFS는 웹크롤링이나 색인 같은 배치 작업 어플리케이션에 적합하였으나 Gmail이나 유튜브 등 거의 real time으로 데이터를 서빙해야 하는 어플리케이션에는 적합하지 않았습니다.
이번 글에서 다루었듯이 GFS는 높은 bandwidth를 low latency보다 중시합니다. 그래서 GFS의 다음과 같은 특징들이 변화한 구글의 workload에서는 독이 되었습니다.
- 64MB chunk data
- 하나의 master로 인한 single point of failure 문제. batch oriented 어플리케이션에는 큰 문제가 아니지만 latency에 민감한 어플리케이션에는 용납이 되지 않습니다. 또한 메타데이터가 마스터의 메모리 크기를 넘지 못하므로 저장할 수 있는 파일 개수가 한정되는 문제도 있습니다.
- Operationa을 queue에 넣는 문제. 높은 throughput이 가능하지만 operation들이 queue에 보관되므로 latency가 느립니다.
이미 Google은 실시간 서비스에 사용하기 위해 분산 데이터베이스 BigTable을 구축하였고 2009년 기준 Bigtable이 더 많은 부하를 받고 있었습니다. 구글은 많은 한계가 있는 GFS를 보완하기 보다 새로운 시스템을 만드는 것이 낫다고 판단한 것이죠.
Colossus의 경우 따로 논문이 나와있지 않습니다. 다만 인터뷰 등을 통해 Colossus에 대한 몇 가지 힌트를 얻을 수 있습니다. 분산 master 및 chunk 데이터 크기 1MB를 사용해 더 많은 서비스에 적합해졌다고 합니다.
6. 마무리
구글이 폭발적으로 성장할 수 있게 도와주고, Hadoop의 reference가 된 GFS를 살펴보았습니다. 현재 제가 회사에서 만들고 있는 프로젝트에서도 여전히 사용되는 디자인을 볼 수 있어서 개인적으로 논문을 재밌게 읽을 수 있었습니다.
다음 글에서는 이번 글에서 잠깐 언급되었던 분산 데이터베이스 BigTable에 대해서 다뤄보겠습니다.