
[구글 시리즈] #2. Bigtable: A Distributed Storage System for Structured Data (2006)
![[구글 시리즈] #2. Bigtable: A Distributed Storage System for Structured Data (2006)](https://images.unsplash.com/photo-1521389385985-0fa3ff457f9b?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDZ8fHRhYmxlc3xlbnwwfHx8fDE3MjY2NTE1NDN8MA&ixlib=rb-4.0.3&q=80&w=2000)
현재 검색 시장뿐만 아니라 다양한 분야를 장악한 구글은 불과 1998년에 설립되었습니다. 구글은 매우 빠른 속도로 성장했고, 이를 위한 인프라 시스템들을 구축했습니다. 구글의 인프라 시스템은 다른 회사 및 개발자에게 많은 영향을 끼쳤습니다. 구글 시리즈는 이러한 논문들 중 일부를 뽑아 소개를 하고자 합니다.
- The Google File System (2003)
- BigTable: A Distributed Storage System for Structured Data (2006)
- The Chubby lock service for loosely-coupled distributed systems (2006)
- Dapper, a Large-Scale Distributed Systems Tracing Infrastructure (2010) (예정)
- Large-scale cluster management at {Google} with {Borg} (2015) (예정)
1. 개요
Bigtable은 구글에서 사용하는 wide-column key-value NoSQL 데이터베이스입니다. 처음 논문이 발표되었을 당시 구글 내부에서만 사용하는 데이터베이스였으나 2015년부터 Google Cloud에서 사용할 수 있어 많은 개발자에게 친숙한 데이터베이스이기도 합니다.
Bigtable은 구글을 포함한 많은 회사들의 데이터들을 서빙하고 있습니다. 구글만 하더라도 Google Analytics, 웹 색인, Google Maps, Google Earth, YouTube 등이 Bigtable을 사용합니다. 2022년 기준 Bigtable은 10 Exabytes 이상의 데이터를 다루고 있고 초당 50억개의 요청을 받아내고 있습니다.
Bigtable은 페타데이터 단위의 데이터를 수천개의 commodity 서버들을 사용해 다루었습니다(2006년에!). 또한 다양한 서비스에 적용이 가능하면서도 scalability, 높은 성능 및 가용성까지 이뤘습니다.
Bigtable은 분산 Wide column 데이터베이스로서 Apache Cassandra에도 영향을 끼치기도 하였습니다.
Bigtable은 GFS와 Chubby Lock Service를 사용하여 구축되었습니다. GFS는 이전 글에서 다루었고 다음 글에서 Chubby Lock Service를 다룰 것이니 Bigtable을 좀 더 깊게 이해하고 싶다면 해당 글들도 같이 보시는 것을 추천합니다.
2. Data Model
Bigtable은 sparse, distributed, persistent, multidimensional sorted map 입니다.
Bigtable은 row key와 column key 그리고 timestamp로 색인이 됩니다. 저장되는 value는 byte 배열입니다.


Bigtable을 사용하는 Webtable을 예시로 들어보겠습니다. Webtable에서는 URL을 row key로, column key로 웹 페이지의 다양한 값들을 사용하고 value로는 웹 페이지의 내용을 저장합니다. fetch할 때 timestamp도 같이 저장이 됩니다.
(1) Rows
- Row key는 최대 64KB 임의의 string이 가능합니다.
- Bigtable은 하나의 row key가 가리키는 data에 대한 모든 read, write가 atomic한 것을 보장합니다. 이때 몇 개의 column을 다루는 지는 상관 없습니다.
- Bigtable은 row key로 사전식 정렬합니다.
- Tablet: Bigtable은 동적으로 row key를 범위로 잡아 파티션하는데, 그 단위를 말합니다. 분산 및 로드밸런싱의 단위가 되며 이 때문에 짧은 row range를 다루는 것이 효율적입니다.
Webtable의 경우 row key를 url을 역순으로 잡아 locality를 활용하였습니다(Fig 1). 같은 도메인 내 페이지들이 근처에 저장하기 때문에 같은 호스트 및 도메인 분석시 효율적으로 수행할 수 있습니다.
(2) Column Families
Column key들은 Column families라 불리는 set으로 묶입니다.
- Column families는 access control의 기본 단위입니다.
- Column family 내 저장된 데이터들은 보통 같은 타입입니다. 같은 Column family내 데이터를 압축해 저장하기 때문에 효율적으로 저장할 수 있습니다.
- Column key의 형식은 “family:qualifier”입니다. Fig 1의 경우 Column family는 “anchor”이고 qualifier는 referring site 이름을 나타냅니다.
(3) Timestamps
Bigtable의 각 셀은 같은 데이터에 대한 여러 버전을 저장할 수 있고, 이 버전은 timestamp로 인덱싱됩니다.
- Timestamp는 64bit 정수입니다.
- Timestamp는 Bigtable 혹은 클라이언트 어플리케이션으로부터 할당받습니다. 어플리케이션이 할당할 때는 Timestamp가 유일함을 보장해야 합니다.
- 버전의 최대 개수 혹은 버전의 저장 기간을 설정할 수 있습니다.
3. Bigtable 구현
Bigtable 구현은 3개의 주요 컴포넌트로 구성되어 있습니다.
- 클라이언트 라이브러리
- 하나의 master 서버
- 여러 개의 tablet 서버
master는 tablet을 tablet 서버에 할당합니다. 또한 tablet 서버의 추가/만료 발견 및 관리, tablet 서버 로드 밸런싱, GFS 내 파일 garbage collection 등을 합니다.
tablet 서버는 tablet set을 관리합니다. 보통 tablet 서버당 10~1000개의 tablet을 가집니다. tablet 서버는 tablet에 대한 read/write 요청을 관리합니다. tablet이 자라 너무 커지면 두 개로 나누기도 합니다.
Bigtable도 다른 single master 분산 스토리지 시스템처럼 클라이언트가 master를 통하지 않고 직접 tablet 서버와 데이터 read/write를 수행합니다. 클라이언트는 tablet 위치 정보를 master에 의존하지 않기 때문에 master와 요청을 주고받을 일이 별로 없습니다.
Bigtable 클러스터는 table을 저장합니다. table은 tablet들의 집합을 저장합니다. tablet은 row range와 관련된 데이터를 저장합니다. 각 테이블은 처음에 하나의 tablet으로 구성되지만 table이 커지며 여러 tablet으로 나뉩니다.
Blocks
Bigtable은 로그 및 데이터 파일을 GFS에 저장합니다.
Bigtable의 데이터는 SSTable 파일 포맷으로 저장됩니다. SSTable은 persistent, ordered immutable map이며 key와 value는 임의의 바이트 string입니다.
SSTable은 block 배열을 가지고 있습니다. Block index는 SSTable의 끝에 저장이 되는데, index는 메모리로 로드됩니다. 그래서 인메모리 index 내 binary search를 수행해 적절한 block을 먼저 찾고 디스크로부터 block을 읽을 수 있습니다.
Chubby
Bigtable은 고가용성 분산 lock 서비스인 Chubby에 의존하고 있습니다. Chubby는 디렉토리와 작은 파일들로 이루어진 namespace를 제공합니다. 이 각 디렉토리나 파일은 lock으로 사용할 수 있고, 파일로의 read/write는 atomic합니다.
Chubby 클라이언트는 Chubby service에 대한 세션을 유지합니다. 클라이언트의 세션은 session lease를 제 때 갱신하지 못하면 만료됩니다. 세션이 만료되면 lock과 open handle을 잃습니다.
Tablet location
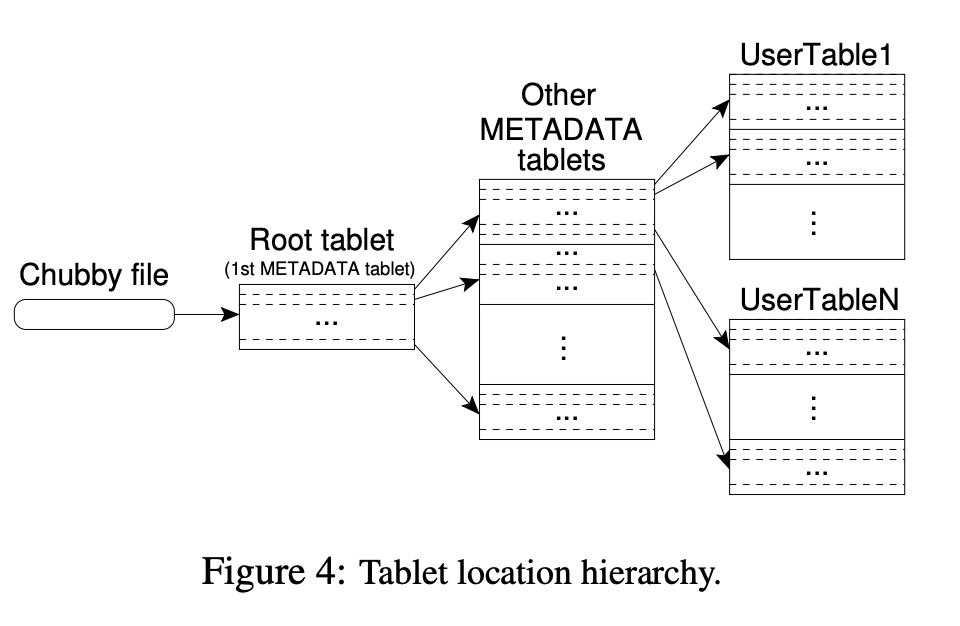
tablet 위치 정보는 3 계층을 가진 B+ tree로 저장됩니다.
Chubby는 첫번째 레벨의 파일을 저장하고 있고, 이 파일은 root tablet의 위치를 저장합니다. Root tablet은 METADATA table 내 저장된 모든 tablet 위치를 가지고 있습니다. METADATA tablet은 user tablet 집합의 위치를 저장합니다.
METADATA table은 (1) tablet의 table identifier와 end row를 인코딩한 row key, (2) tablet 위치를 저장합니다.
클라이언트 라이브러리는 tablet 위치를 캐싱합니다. 모든 tablet 위치는 메모리에 저장되어 있어 GFS 접근이 필요 없습니다.
Tablet Assignment
각 Tablet은 하나의 tablet 서버에 할당됩니다. master는 살아있는 tablet 서버들과 tablet 서버에 할당된 tablet 등을 트래킹합니다. master는 할당되지 못한 tablet을 여유 있는 tablet 서버에 배정하는 역할을 합니다.
Chubby를 활용한 tablet 서버 관리
Bigtable은 tablet 서버들을 트래킹하기 위해 Chubby를 사용합니다. tablet 서버가 시작하면 특정 chubby 디렉토리에 유일한 이름을 가진 파일을 생성하고 exclusive lock을 획득합니다. master는 이 디렉토리를 모니터링하여 tablet server를 찾습니다. Chubby 세션을 잃는 등의 이유로 tablet 서버가 lock을 잃으면 tablet 서빙을 멈춥니다. 만약 파일이 존재하지 않으면 tablet 서버는 서빙할 수 없고 스스로를 죽입니다.
tablet 서버가 멈추면 lock을 풀기 때문에 마스터는 이를 감지하고 tablet 서버가 가진 tablet들을 빠르게 재할당할 수 있습니다. master는 감지하기 위해 각 tablet 서버들에게 lock의 상태를 주기적으로 물어봅니다. 만약 tablet 서버가 lock을 잃었다고 응답하거나 master가 서버에게 도달할 수 없다면 master는 서버의 파일에 exclusive lock을 얻는 것을 시도합니다. 만약 master가 lock을 얻는다면 Chubby는 살아있다는 것입니다. 이 경우 tablet 서버가 죽었거나 tablet 서버가 Chubby에 도달하는데 문제가 있다고 할 수 있습니다. 그래서 master는 그 파일을 삭제함으로써 해당 tablet 서버가 서빙하지 못하게 만듭니다. 파일을 삭제시키면 master는 이전에 할당된 모든 tablet을 할당되지 않은 tablets 셋으로 옮깁니다.
master와 chubby 내 네트워크 문제가 생길 수도 있습니다. 이 때문에 master는 자신의 chubby 세션이 만료되면 자기 자신을 죽입니다. 다행히 master 실패는 tablet 할당에 영향을 미치지 않습니다.
master가 tablet 할당을 아는 방법
master는 현재 tablet 할당을 알기 위해 시작할 때 다음 작업을 순서대로 진행합니다.
(1) master는 Chubby 내 unique master lock을 획득하여 master가 동시에 뜨는 것을 막습니다
(2) master는 Chubby 내 서버 디렉토리를 스캔해 살아있는 서버들을 찾습니다.
(3) master는 모든 살아있는 tablet들과 통신하여 어떤 서버에 어떤 tablet들이 할당되었는지 확인합니다.
(4) master는 METADATA table을 스캔하여 tablets set을 확인합니다. 이때 할당되지 않은 tablet을 만나면 master는 table을 unassigned tablet set에 추가합니다.
Master는 table에 대한 모든 변경을 트래킹합니다. 이중 tablet을 쪼개는 것은 특별하게 다뤄집니다. tablet 서버는 METADATA table 내 새로운 tablet 정보를 기록하여 쪼개는 것을 커밋합니다. 쪼개는 것이 커밋되면 master에 알립니다.
Tablet Serving
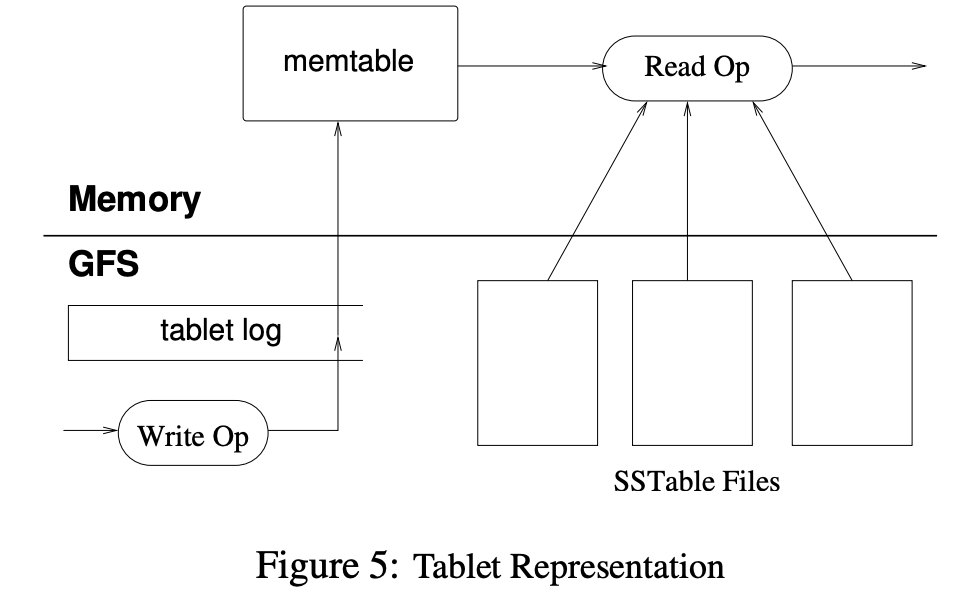
tablet의 영구 상태는 GFS 내에 Fig 5처럼 저장됩니다.
Update는 commit 로그로 커밋됩니다. Update는 메모리에 memtable이라 불리는 정렬된 버퍼로 저장됩니다. 오래된 update들은 SSTable로 저장됩니다.
tablet을 복구할 때 tablet 서버는 METADATA table에서 메타 데이터를 읽습니다. 이 메타 데이터는 tablet과 redo points 셋을 담는 SSTable 리스트를 가지고 있습니다(redo points는 tablet의 데이터를 포함하고 있는 commit 로그). 서버는 SSTable의 indices를 메모리로 읽고 redo point로 커밋된 모든 업데이트를 적용해 memtable을 재구축합니다.
읽기 연산은 SSTable sequence + memtable의 merged view에서 수행합니다. SSTable과 memtable은 사전식으로 데이터가 정렬되어 있어 merged view를 효율적으로 수행할 수 있습니다.
쓰기 연산은 throughput을 증가시키기 위해 group commit을 활용합니다.
Compaction
Write operation이 수행되면 memtable의 크기가 증가합니다. memtable 크기가 일정 이상 도달하면 기존 memtable은 얼려지고(frozen) 새 memtable이 생성됩니다. 그리고 얼려진 memtable은 SSTable로 변경되어 GFS에 쓰여집니다.
Bigtable에서 compaction은 major compaction과 minor compaction으로 나뉩니다. compaction 중에도 읽기와 쓰기는 수행 가능합니다.
minor compaction은 SSTable들을 합쳐 새로운 SSTable을 생성하는 것을 말합니다. tablet 서버의 메모리 사용량 및 서버가 죽은 이후 복구시 commit 로그 읽기를 줄이기 위해 수행합니다. background에서 주기적으로 minor compaction이 수행되며, minor compaction시 몇 개의 SSTable들과 memtable을 읽고 새 SSTable에 씁니다. compaction이 끝나면 사용된 SSTable과 memtable은 버려집니다.
major compaction은 모든 SSTable을 하나의 SSTable로 다시 쓰는 작업입니다. major compaction이 아닌 동작에서 생성된 SSTable은 deletion entry가 있습니다. Deletion entry는 이전 SSTable에 살아있는 데이터를 삭제하는 역할을 합니다. major compaction에서 생성된 SStable은 삭제 정보 및 삭제된 데이터가 없습니다.
4. Refinement
높은 성능, 가용성, 신뢰성을 달성하기 위해 적용한 refinement를 소개합니다.
Compression
클라이언트는 한 locality group에 대한 SSTable들을 압축할지 말지 결정할 수 있습니다. 압축 포맷은 two-pass custom 압축 scheme을 사용합니다.
first pass는 Bentley, McIlroy scheme을 사용합니다. 이 scheme은 긴 common 문자열을 large window에 걸쳐 압축합니다. Second pass는 빠른 압축 알고리즘을 사용하며 16kb window 내에서 반복을 찾습니다.
Bigtable은 압축율보다 압축 속도를 중요시했음에도 two pass 압축 scheme은 잘 작동했습니다. 예를 들어 Webtable의 경우 많은 양의 문서들을 압축된 locality group에 저장했는데, 압축률 90%를 달성했습니다(10 to 1). 이는 많이 사용하는 Gzip를 HTML에 사용했을 때보다 성능이 좋은 것입니다(3 to 1 혹은 4 to 1). 같은 호스트의 페이지들이 가까이 있기 때문에 Bently-McIlroy 알고리즘이 같은 호스트의 페이지들을 공유된 보일러플레이트로 인식할 수 있었기 때문입니다. webtable 외에도 많은 어플리케이션이 비슷한 효과를 보았고, 압축 효과는 같은 값에 대한 여러 버전을 저장하면 더 좋아졌습니다.
Commit-log implementation
각 tablet에 대한 commit log를 분리된 로그 파일에 저장하면 GFS에 너무 많은 파일이 쓰여질 것입니다. GFS 구현을 생각해 보면 이는 수많은 disk seek을 유발합니다. 이 뿐만이 아니라 group의 크기를 줄여서 group commit 최적화의 효율성을 떨어뜨립니다. 그래서 Bigtable은 mutation을 tablet 서버당 하나의 commit 로그에 append를 하게 하여 같은 파일에 다른 tablet의 mutation들을 섞었습니다.
하나의 로그만 사용하면 성능에 이점이 있으나 복구가 복잡해집니다. tablet 서버가 죽으면 서버 내 tablet들은 다른 tablet 서버로 이동을 해야합니다. tablet 상태를 복구하기 위해 새 tablet 서버는 해당 tablet에 대한 mutation을 재적용해야합니다. 그러나 tablet들에 대한 로그들이 하나의 로그 파일에 쓰여져 있기에 모든 tablet 서버가 해당 파일을 중복해서 읽는 문제가 생깁니다.
그래서 로그를 중복해서 읽는 것을 막기 위해 먼저 commit log을 <table, row name, log seqeunce number> 순서로 key 정렬을 합니다. 정렬된 output에서 특정 tablet에 대한 모든 mutation은 모두 연속적이기에 하나의 disk seek으로 순차적인 읽기를 할 수 있습니다. 정렬을 병렬화하기 위해 로그 파일을 64MB segment로 나누고 각 segment를 병렬적으로 다른 tablet server에서 정렬합니다. 이 정렬 프로세스는 master에 의해 수행되며 tablet server들이 복구를 위해 하나의 log file을 필요로 할 때 수행됩니다.
GFS로 commoit log를 쓰는 것은 성능 이슈가 있을 때가 있습니다(GFS 서버가 write crash가 발생하거나 network 혼잡이 일어나거나). GFS latency spike를 막기 위해 각 tablet 서버는 실제로 두 개의 로그 쓰기 thread를 가지고 있습니다. 각 쓰기 thread는 자신만의 로그 파일을 가지고 하나의 thread만 작동합니다. 만약 active 로그 파일 성능이 나오지 않으면 다른 thread로 교체해 사용합니다.
Exploiting immutability
SSTable은 immutable합니다. Bigtable은 SSTable이 immutable하기 때문에 구조가 많이 단순해졌습니다.
SSTable과 달리 memtable은 read와 write를 허용하여 mutable합니다. read 하는 동안 contention을 줄이기 위해 각 memtable row는 copy-on-write를 하여 read와 write를 병렬로 수행할 수 있도록 하였습니다.
SSTable이 immutable하기에 데이터 삭제 문제는 SSTable의 garbage collection 문제로 변환됩니다. 각 Tablet의 SStable들은 METADATA 테이블에 등록되어 있습니다. master는 필요 없는 SSTable을 mark-and-sweep garbage collection합니다.
5. 마무리
여타 분산시스템과 다르게 Bigtable은 레플리카 관리를 직접 하지 않습니다. 그 이유는 GFS를 사용하기 때문에 GFS에 쓰기가 완전히 커밋이 되면, 가용성이 보장되기 때문입니다. Master가 죽었을 때 생기는 split brain 문제나 tablet 서버들의 관리 문제는 Chubby에 의존하여 해결하였습니다. 덕분에 Bigtable은 복잡한 분산 시스템 문제에서 벗어나 서빙 문제에 집중할 수 있었습니다.
Bigtable은 빠른 응답속도를 제공하기 위해 tablet 위치와 memtable들을 메모리 위에서 서빙하였습니다. 대부분의 검색 쿼리는 disk(GFS)에 접근하지 않을 것이며, 서버가 죽고 memtable을 복구할 때만 GFS에서 SSTable을 꺼내 읽을 것입니다.
다음 글에서는 Bigtable의 master 및 tablet server 들을 관리하기 위해 사용된 Chubby를 다뤄보겠습니다.
6. Reference
Bigtable: A Distributed Storage System for Structured Data (2006)