
[논문 리뷰] REFRAG: RAG 최적화를 위한 인코딩/디코딩
![[논문 리뷰] REFRAG: RAG 최적화를 위한 인코딩/디코딩](https://images.unsplash.com/photo-1722936598143-40ea5da94dfd?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDJ8fGVuY29kZXJ8ZW58MHx8fHwxNzY2MjM3NDE0fDA&ixlib=rb-4.1.0&q=80&w=2000)
이 글은 논문 REFRAG: Rethinking RAG based Decoding 을 리뷰합니다.
RAG는 서비스에 LLM을 적용할 때 가장 먼저 검토하는 방법 중 하나입니다. 모델 파인튜닝 없이도 도메인 지식을 활용할 수 있다는 것이 RAG의 핵심 장점이죠.
하지만 활용할 지식이 많아질수록 입력으로 더 긴 컨텍스트를 넣어야 하고, 이는 높은 레이턴시와 메모리 소비를 발생시킵니다. 실제 서비스 환경에서는 이러한 오버헤드가 큰 걸림돌이 됩니다.
이번에 소개할 논문 REFRAG는 Meta에서 발표한 것으로, RAG 컨텍스트를 압축하여 계산 및 메모리 오버헤드를 줄이는 방법을 소개합니다. Perplexity 손실 없이 TTFT(Time To First Token) 최대 30배 개선했으며, 이는 이전 최신 기술 대비해도 3배 향상된 결과입니다.
다만 REFRAG는 별도의 encoder 및 decoder(decoder only Foundation model) 학습이 필요합니다. LLM 아키텍처를 변경하거나 새로운 decoder 매개 변수를 추가할 필요는 없지만, 학습 과정이 필요하다는 점에서 즉시 서비스에 적용하기는 어려울 수 있습니다.
그럼에도 이 논문을 소개하는 이유는 두 가지입니다. 먼저 RAG의 문제점과 그 해결 방법을 제시하는 흐름이 논리정연하여 RAG에 익숙하지 않은 분들에게 좋은 학습자료가 될 수 있습니다. 둘째로 산업계가 이제 RAG를 최적화를 위한 전용 모델 학습으로 나아가고 있다는 트렌드를 보여줍니다. 불과 2024년까지만 해도 RAG를 막 도입하고 있었는데, 벌써 이런 최적화 기법들이 나오는 것을 보면 놀랍습니다.
Decoder Only Model의 추론(inference) 과정에 익숙하지 않은 분들을 위해서 모델이 인풋으로 받는 토큰을 어떻게 처리하는지 먼저 살펴보고 이후에 논문의 내용으로 들어가보겠습니다.
LLM 모델의 TTFT가 컨텍스트 길이의 제곱에 비례하여 증가하는 이유
RAG의 성능 문제를 이해하려면 먼저 LLM이 어떻게 첫 토큰을 생성하는지 알아야 합니다.
Decoder-only Transformer 구조
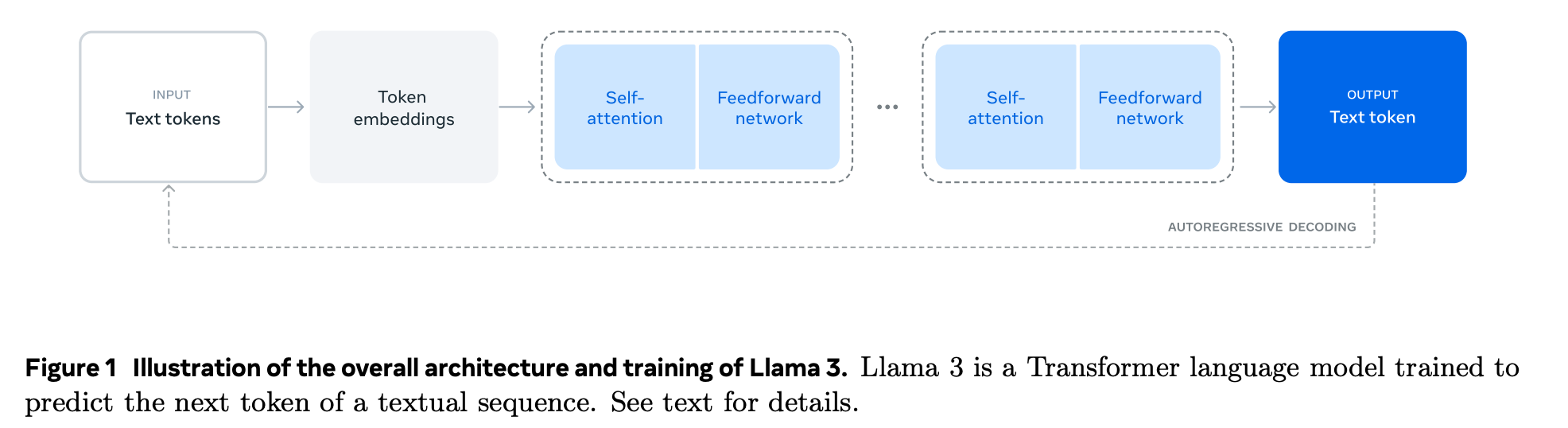
대부분의 현대 LLM(LLaMA, GPT 등)은 Decoder only Transformer 구조를 사용합니다. 이 구조는 입력 토큰 시퀀스를 받아 여러 층의 Transformer 블록을 통과시켜 처리하고 토큰을 생성합니다.
입력 토큰 시퀀스는 다음과 같이 구성됩니다:
- 사용자 질의
- 시스템 프롬프트
- (RAG의 경우) 검색된(retreived) 토큰들
각 Transformer 블록은 일반적으로 다음 구성 요소들로 이루어집니다:
- Masked Self-Attention
- Feed-Forward Network (FFN)
- Residual Connection 및 Normalization
Autoregressive 생성 방식
Decoder only llm은 “autoregressive”하다고 합니다. 다음 토큰을 생성할 때 이전 토큰을 기반으로 하기 때문에 순차적으로 하나의 토큰씩 생성할 수 있다는 의미입니다.
첫 번째 토큰을 생성하려면 모든 입력 토큰을 처리해야하는데, 이 과정을 prefill 단계라고 합니다. 전체 입력 시퀀스에 대하여 모든 transformer 블록의 연산이 완료되어야 하므로, 첫 번째 토큰이 출력되기까지 비교적 오래 걸립니다.
첫번째 토큰이 출력되는 시간을 TTFT(Time To First Token)이라고 합니다.
첫 토큰 생성 이후에는 prefill 단계에서 계산했던 Key Value 값들을 저장한 KV 캐시를 활용하므로 이후 토큰 생성은 상대적으로 빠릅니다. (자세한 내용은 이전에 vLLM을 다룬 글을 참고해주세요)
Self Attention의 O(N^2) 복잡도
prefill 단계에서 병목은 Transformer 블록 내 self attention 연산입니다.
입력 토큰 수가 N이고, hidden dimenstion을 d라고 해봅시다.
- Query(Q)와 Key(K)는 각각 (N × d) 차원
- Attention은 Q × K^T (K의 transpose)로 계산
- 행렬 곱셈의 계산 복잡도는 O(N² × d)
즉, Self-Attention 비용은 입력 토큰 개수의 제곱에 비례합니다.
따라서 입력으로 많은 토큰이 들어올수록 self attention 비용이 커지고 TTFT도 이에 따라 증가하게 됩니다.
REFRAG: 컨텍스트 압축으로 TTFT를 줄이기
이제 긴 컨텍스트가 TTFT를 증가시키는 이유를 이해하셨을 것입니다. RAG에서는 이 문제가 더 두드러지는데, Retrieval passage가 사용자의 쿼리에 비해 훨씬 크기 때문입니다.
REFRAG 논문에서는 RAG에서 TTFT에 악영향을 끼치는 문제들을 몇 가지 더 제시합니다.
- 불필요한 토큰 할당: RAG는 sparse한 정보를 담아 대부분의 passage가 불필요합니다.
- 낭비되는 인코딩: RAG의 검색 과정에서 이미 컨텍스트 청크들을 전처리합니다. 또한 벡터화와 reranking 과정에서 각 청크의 인코딩과 쿼리와의 상관관계 정보가 이미 계산되어 있습니다. 그런데 이 정보들이 디코딩 과정에서 쓰이지 않고 있습니다.
- 비효율적인 sparsed attention: 디코딩 중 대부분의 컨텍스트 청크는 관련이 없습니다. 결과적으로 청크 간 cross attention이 대부분 0이 되고, 이는 비효율적입니다.
REFRAG는 검색된 passage를 그대로 쓰는 대신, 압축된 청크 임베딩을 디코더에 넣는 방법을 입력하는 방법을 제시합니다.
- 검색 과정에서 이미 계산된 청크 임베딩을 재사용해 불필요한 연산을 없앨 수 있습니다.
- 디코더의 입력 길이를 줄입니다.
- attention 연산 복잡도를 컨택스트 내 토큰 수(N)의 제곱이 아닌 청크 수의 제곱에 비례하도록 줄일 수 있습니다.
REFRAG Model Architecture
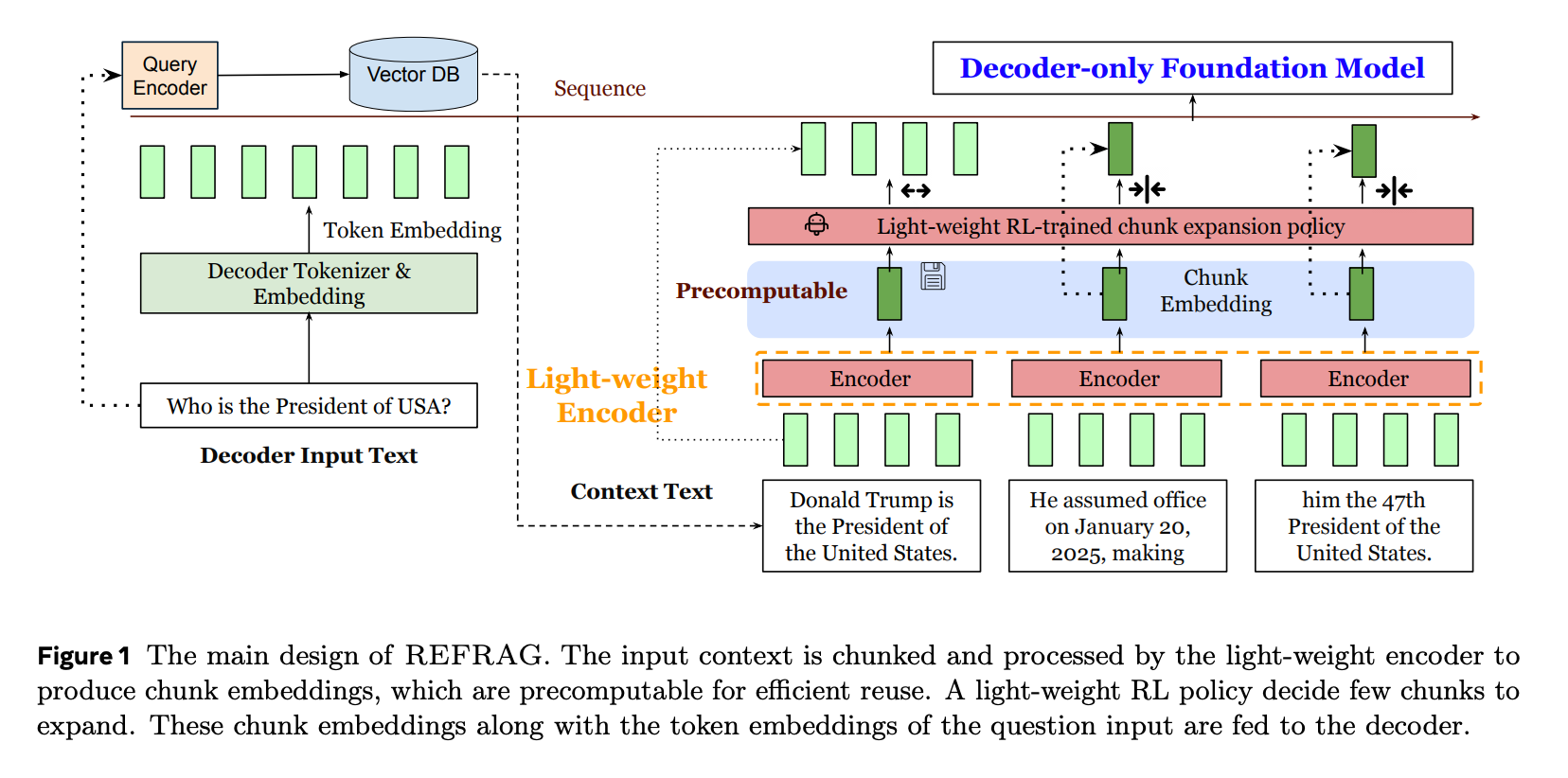
REFRAG의 구조를 수식과 함께 살펴보겠습니다.
입력 구성
- T: 인풋 토큰 개수
- q: 메인 인풋 토큰(쿼리 토큰)
- s: context 토큰(RAG)
- T = q + s
청크 및 인코딩
컨텍스트 토큰(s개)은 L개의 청크로 분할됩니다. L = s/k (k는 각 청크의 크기)
인코더 모델은 모든 청크들을 처리하여 각각의 청크에 대해 임베딩을 생성합니다. 이 청크 임베딩은 projection layer를 거쳐 디코더 모델의 토큰 임베딩 차원에 맞게 변환됩니다.
디코더 입력 및 생성
변환된(projected) 청크 임베딩은 메인 입력 토큰(쿼리)과 함께 디코더 모델로 입력되어 답변을 생성합니다. 생성된 답변 y는 다음과 같이 표현할 수 있습니다:
y = M_dec({e₁, e₂, …, e_q, e₁_chunk, …, e_L_chunk})
- M_dec: 디코더 모델
- e_i: 토큰 x_i의 임베딩
- e_j_chunk: j번째 청크의 임베딩
RAG에서는 일반적으로 s >> q입니다. 즉, 컨텍스트 토큰이 쿼리 토큰보다 훨씬 많습니다.
- 기존 RAG에서 디코더 입력 길이: q + s
- REFRAG에서 디코더 입력 길이: q + L = q + s/k
컨텍스트가 전체 입력의 대부분을 차지하므로, 디코더로 들어가는 입력의 전체 양이 거의 k배 감소하게 됩니다.
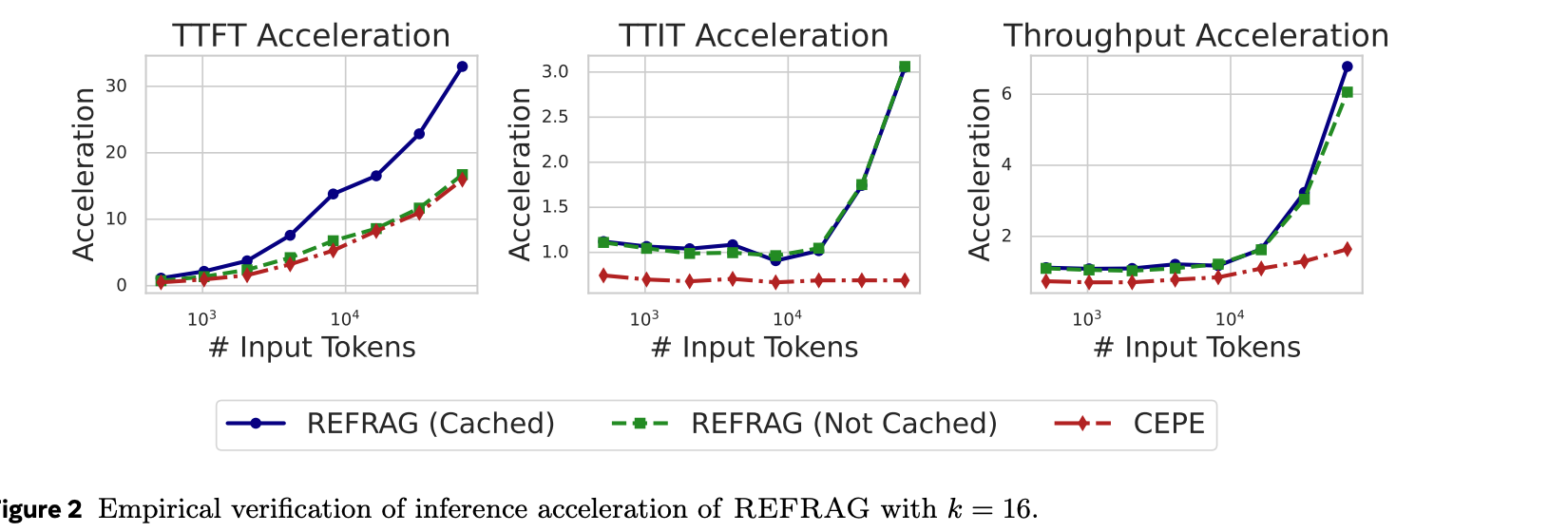
위 그래프는 k=16일 때 평가 그래프입니다.
REFRAG(cache)의 경우 청크 임베딩을 캐시한 것입니다.(논문에서는 자세히 나오지 않지만, 아마 Retrieval에서 사용한 청크 임베딩을 사용한 것으로 추측됩니다)
비교 대상인 CEPE는 REFRAG와 비슷한 특성을 가진 이전 SOTA model입니다.
TTFT, TTIT(subsequent token 생성 시간), throughput 모두 REFRAG가 CEPE에 비해 좋은 성능을 보임을 확인할 수 있습니다.
Methodology: 어떻게 학습시킬까?
REFRAG는 모델을 CPT(Continual Pre-Training)와 SFT(Supervised Fine-Tuning) 두 단계로 나누어 학습합니다.
학습 대상 모델은 컨텍스트를 압축할 인코더 모델과 그 컨텍스트를 사용할 디코더 모델(foundation model)입니다.
먼저 입력 T개의 토큰을 s + o로 나눕니다:
- s: 인코더에 입력될 컨텍스트 토큰
- o: 디코더가 예측할 출력 토큰
CPT 단계에서는 첫 s개 토큰을 인코더에 입력하고, 인코더 출력을 디코더에 전달하여 다음 o개 토큰을 예측하도록 학습합니다. 이를 통해 모델은 압축된 컨텍스트 정보를 활용해 다음 문단을 예측하는 능력을 얻습니다.
CPT 단계의 목표는 전체 컨텍스트를 사용하는 기존 디코더와 유사한 성능을 내도록 압축된 컨텍스트를 생성하는 것입니다.
SFT 단계에서는 RAG나 multi-turn conversation 같은 특정 다운스트림 태스크에 모델을 적용합니다.
CPT(Continual Pre-Training)
CPT는 세 가지 기법으로 구성됩니다.
- Reconstruction Task
Reconstruction task의 목적은 인코더와 projection layer를 디코더와 정렬입니다.
첫 s개 토큰을 인코더에 입력하고, 디코더는 원본 s개 토큰을 재구성(reconstruct)하는 것을 학습합니다. 이때 디코더 모델은 freeze하여 학습시키지 않고 인코더와 projection layer만 학습시킵니다.
학습을 통해 인코더는 k개 토큰 압축시 정보 손실을 최소화하고, projection layer는 청크 임베딩을 디코더 토큰 공간으로 효율적으로 매핑할 수 있게됩니다. 또한 모델이 학습 중 암기한 지식보다 컨텍스트 정보에 의존하도록 유도하는 효과도 있다고 합니다.
2. Curriculum Learning
1번 Reconstruction Task은 문제점이 있습니다. 청크 길이가 k일 때, 가능한 토큰 조합은 V^k(V는 vocabulary size)로 증가합니다. 이를 고정 길이 임베딩으로 표현하는 것은 어렵습니다. 이렇게 한 개의 청크를 재구축하는 것도 어려운데, s = k × L개 토큰(L개의 청크)을 한 번에 재구축하는 것은 더욱 어렵습니다.
논문에서는 디코더를 직접 pre-training하여 인코더 출력을 처리하도록 하는 것만으로는 perplexity가 개선되지 않는다고 말하며, 대안으로 Curriculum Learning을 적용했다고 합니다.
Circulation Learning은 태스크의 난이도를 점진적으로 증가시켜 모델이 단계적으로 능력을 습득하도록 하는 방법입니다.
처음에는 단일 청크 재구성 (1개 청크 임베딩 → k개 토큰 생성)으로 시작합니다. 학습을 충분히 하면 2개 청크 재구성 (2개 청크 임베딩 → 2k개 토큰 생성)을 학습하고, 점진적으로 L개까지 확장합니다.
3. Selective Compression
예측 정확도를 높이기 위하여 중요한 컨텍스트 청크를 골라 압축을 풀어 입력하는 방식입니다. RL(강화학습)을 사용하여 다음 paragraph의 perplexity를 negative reward로 설정해 어떤 청크를 원본 청크로 사용할지 학습합니다.
이를 위해 인코더와 디코더는 압축된 청크와 압축되지 않은 청크가 혼합된 입력을 처리할 수 있도록 학습됩니다.
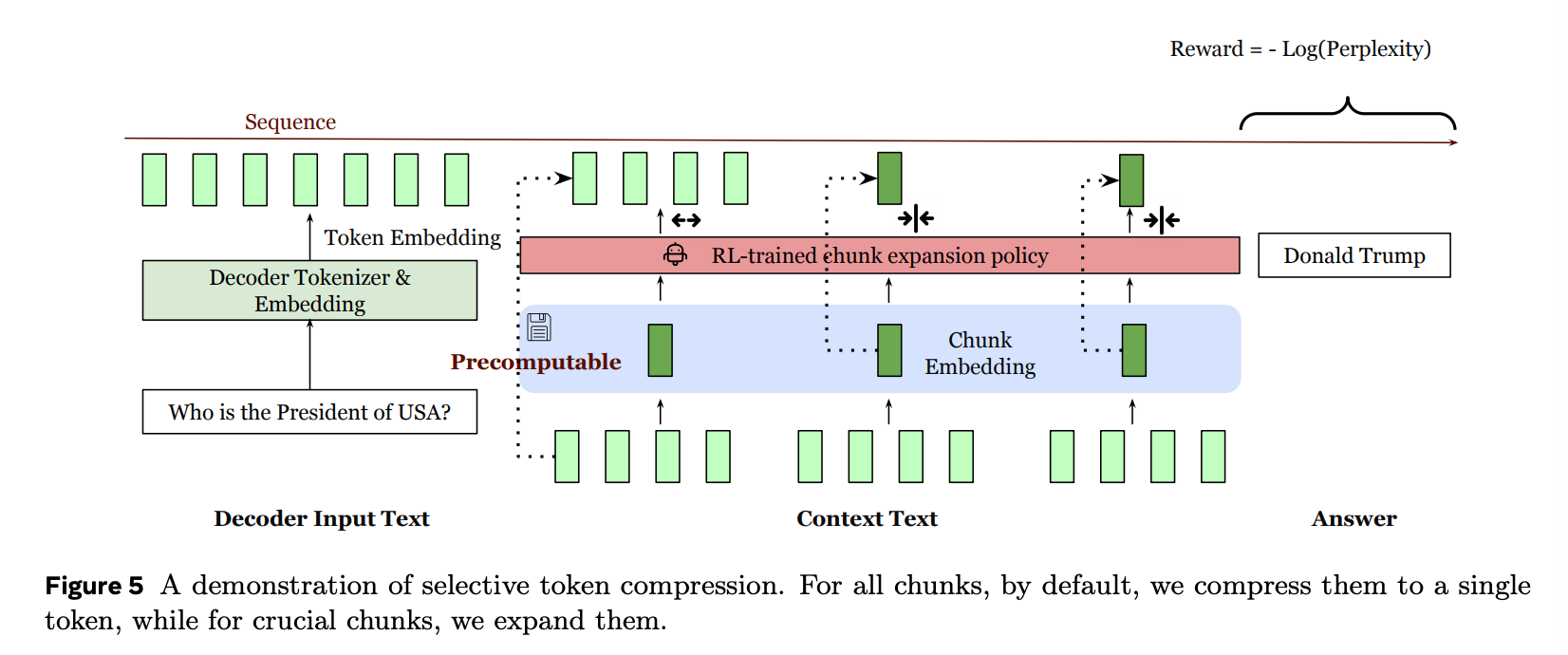
참고로 논문에서는 reconstruction stage와 다음 paragraph 예측에 사용하는 learning rate를 다르게 설정했다고 합니다.
reconstruction stage의 learning rate가 paragraph 예측에 비해 높은 편인데, reconstruction stage는 encoder 모델만 훈련하는 반면 paragraph 예측은 decoder 모델을 포함한 모든 파라미터를 훈련하기 때문에 그렇습니다.
평가
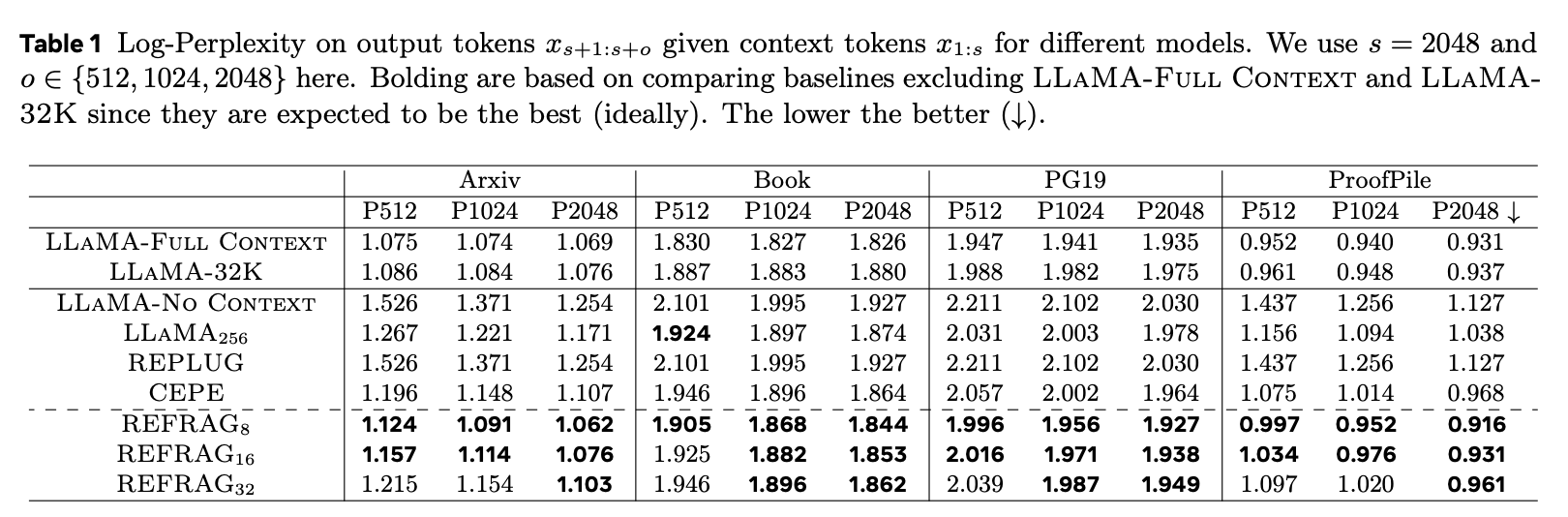
논문에서는 output 토큰에 대한 모델의 perplexity로 평가했습니다. perplexity가 낮을 수록 모델이 생성한 토큰에 대해 더 높은 확신이 있었다고 해석할 수 있습니다. 즉, 낮을 수록 더 좋은 수치입니다.
실험에서 T = 4096개의 토큰을 가진 각 데이터에 대하여 s = 2048 context 토큰, o = 2048 output 토큰으로 나누었습니다. 그리고 output 토큰들에 대한 모델의 perplexity를 측정하였습니다.
LLAMA-No Context는 output 토큰만을 input으로 가지고 s+1:s+o까지의 토큰에 대한 perplexity를 측정했습니다. 즉, 처음에는 아무 토큰도 없이 s+1번째의 토큰을 예측하고, s+1:s+t 토큰들을 보고 s+t+1번째의 토큰을 예측하면서 perplexity를 측정한 것입니다.
베이스라인으로 설정한 LLAMA-Full Context와 LLAMA-32K는 T개의 토큰을 모두 인풋으로 받아 s+1:s+o 토큰들을 평가했습니다. 즉 완전한 컨텍스트를 받은 상황에서 perplexity를 측정한 것입니다.
REFRAG는 k를 달리하여 측정하였습니다(8, 16, 32)
측정 결과를 보면 베이스라인을 제외하면 REFRAG의 perplexity가 상당히 낮은 편이라는 것을 알 수 있습니다.
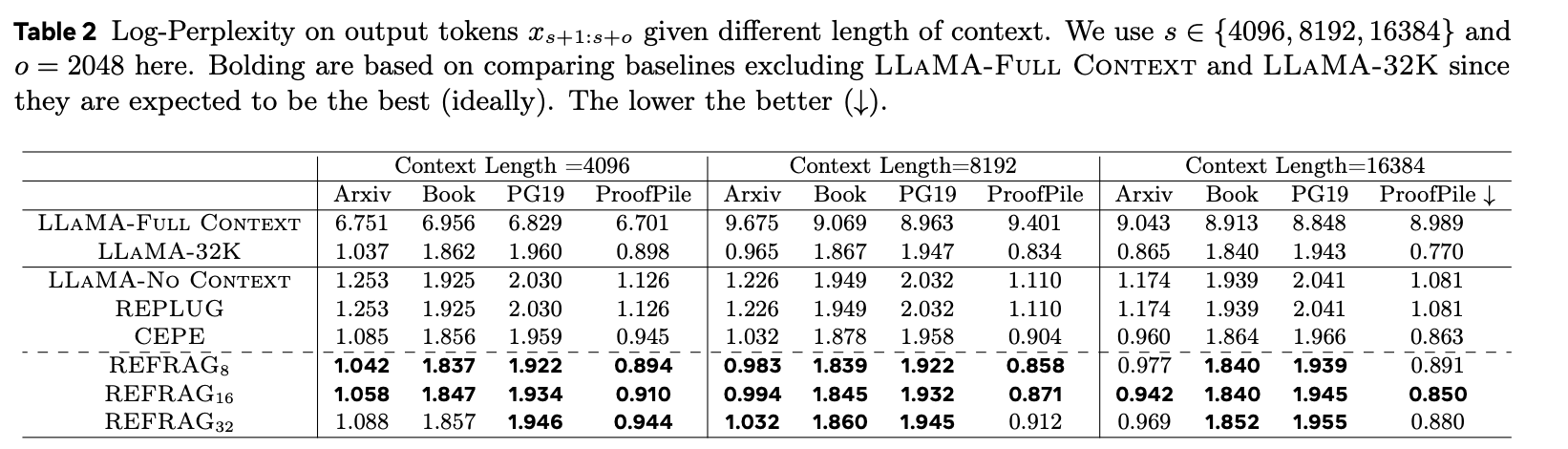
context length가 길 때에도 REFRAG는 좋은 성능을 보였습니다.
LLAMA-Full Context는 4k의 context window를 가지고 있어 long context에는 성능이 확 떨어지는 것을 관찰할 수 있습니다.
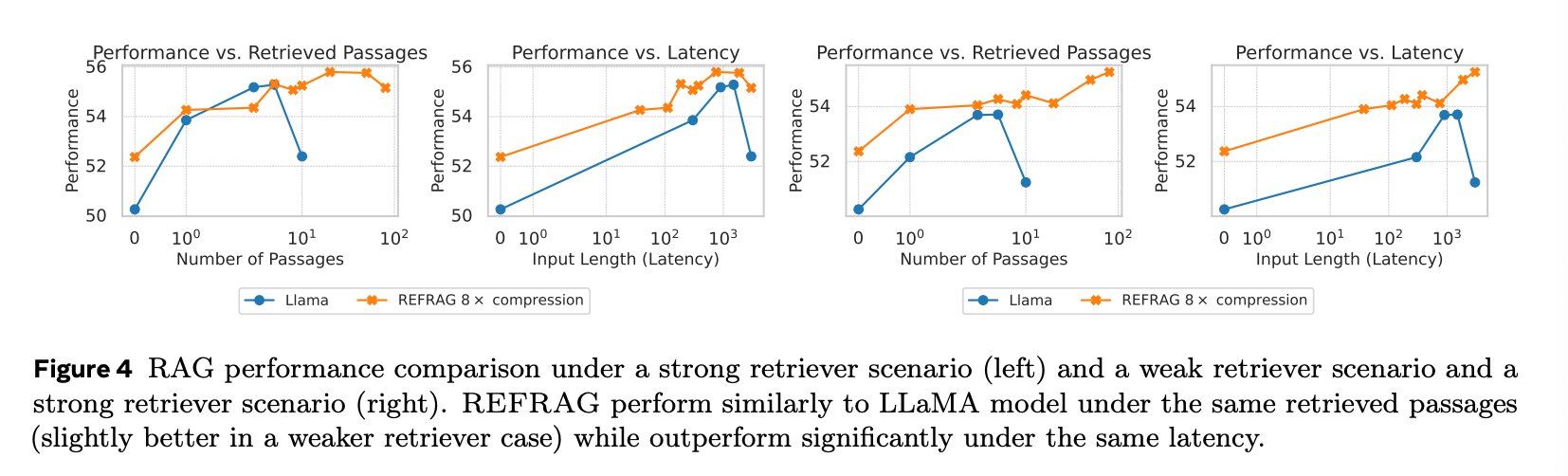
RAG에서 REFRAG의 효과는 더 빛을 발합니다.
위 Figure 4에서 좌측의 그래프는 strong retriever, 우측은 weak retriever 케이스입니다. Strong retriever은 질문에 가장 가까운 K개의 passage를 가져온 케이스이고(KNN) weak retreiver은 200개의 passage를 가져오고 그 중 K개를 랜덤으로 뽑아 사용합니다.
performance는 얼마나 잘 대답을 했냐를 평가하는 점수로 논문 내에서 여러 개의 RAG 작업을 수행한 후 이를 평균낸 지표입니다.
REFRAG를 썼을 때 동일 레이턴시 대비 performance가 좋은 것을 확인할 수 있습니다.
LLM 내부에 REFRAG 인코더를 내재화하기 어려운 이유
이 논문을 읽으면서 자연스럽게 드는 의문이 있습니다:
"LLM 아키텍처 내부에 REFRAG 같은 경량 인코더를 두어 Self-Attention 전에 컨텍스트를 압축하면 어떨까? 그러면 모든 LLM 사용자가 이 혜택을 볼 수 있지 않을까?”
REFRAG가 추가한 것은 컨텍스트를 나누어 압축하는 인코더인 것이고, 이를 LLM 아키텍처에 내재화했으면 모든 LLM을 쓰는 사람이 이 혜택을 볼 수 있었을 테니까요.
하지만 self attention의 의미를 잘 생각해보면 이런 인코더를 아키텍처 내에 추가하는 것이 의미가 없음을 알 수 있습니다.
self attention 전 각 토큰은 독립적인 임베딩 벡터이며 다른 토큰과의 관계 정보가 없습니다. self attention을 해야 토큰 간 의미를 알 수 있게 되는 것이죠. 그 전까지는 각 토큰이 무슨 의미인지, 어떤 토큰들끼리 묶여야 하는지 알 수 없습니다.
REFRAG의 인코더는 RAG가 지닌 특성 때문에 사용할 수 있는 것입니다.
RAG에서 검색된 각 passage는 독립적인 문서 단위로 이미 분리되어 있습니다. 어디서 나누어야 할지 명확합니다. 각 passage는 독립적으로 인코딩되고 서로 다른 passage 간에는 attention을 계산하지 않습니다. RAG에서 가져오는 passage들은 독립적인 문서이기에 직접적인 연결이 약하여 독립적으로 압축해도 의미의 손상이 일어나지 않는 것입니다.
하지만 일반적인 LLM은 입력으로 받는 토큰들이 의미적으로 나누어져 있는지, 한 뭉치인지 알 수 없습니다. self attention 전까지 의미를 전혀 알 수 없기 때문에 나누어서 인코더에 넣는 행위가 불가합니다.
즉 REFRAG의 압축 방식은 RAG의 구조적 특성(명확히 구분된 독립적 passage들)을 활용한 도메인 특화 최적화입니다. 이것이 범용 LLM 아키텍처에 내재화될 수 없는 이유이며, 동시에 RAG에 특화된 최적화가 필요한 이유이기도 합니다.