
[논문 리뷰] Efficient Memory Management for Large Language Model Serving with PagedAttention
![[논문 리뷰] Efficient Memory Management for Large Language Model Serving with PagedAttention](https://images.unsplash.com/photo-1533279443086-d1c19a186416?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDJ8fG1lbW9yeXxlbnwwfHx8fDE3MDkzMDUxMDN8MA&ixlib=rb-4.0.3&q=80&w=2000)
[요약]
- Efficient Memory Management for Large Language Model Serving with PagedAttention 은 vLLM의 기반이 된 논문이다.
- LLM 서빙에서 throughput을 향상시키려면 배치 처리를 해야한다. 배치 처리의 바틀넥은 KV 캐시가 차지하는 메모리 크기이며 이에 따라 최대 배치 크기가 결정된다.
- vLLM은 OS의 virtual memory처럼 KV 캐시가 저장되는 메모리를 block단위로 나누고 logical block과 physical block 개념을 도입해 낭비되던 메모리를 줄였다.
- vLLM을 사용하면 성능을 같은 레이턴시 대비 2배 이상의 throughput으로 향상시킬 수 있다.
LLM 서빙을 위해 많이 사용되는 프레임워크는 TGI와 vLLM이 있다. 두 프로젝트 모두 LLM을 쉽게 배포하고 효율적으로 서빙하는 것을 도와준다.
이번에 소개할 논문은 vLLM의 기반이 된 논문으로 Paged Attention이라는 효율적인 메모리 관리를 하는 기법을 소개한다. LLM은 트랜스포머 기반의 모델들이 다수이기에 key-value cache(KV cache) 메모리 관리를 하는 것이 굉장히 중요하다.
해당 논문은 vLLM을 사용하여 LLM 서빙시 같은 레이턴시 대비 throughput을 2~4배 증가시켰다고 한다. 과연 PagedAttention이 무엇이길래 이런 성능 개선을 낼 수 있었는지 알아보자.
LLM 인퍼런스에서 batching
LLM 인퍼런스는 메모리 바운드이다. 따라서 메모리에 올려놓은 모델 파라미터를 공유하는 batching이 성능 향상에 중요하다.
Naive batching/static batching
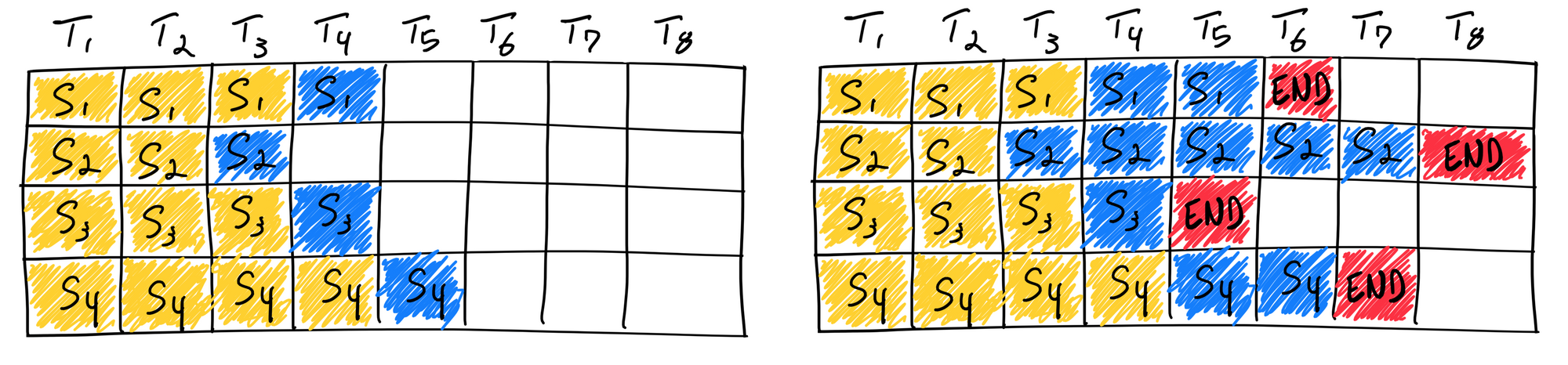
일반적으로 생각하는 방법으로 단순하게 여러 개의 요청을 한 batch에 묶어 올리는 것이다.
이 방법의 단점은 빨리 끝난 요청이 점유한 resource를 batch의 모든 요청이 완료될 때까지 쓸 수 없다는 것이다. 즉 GPU utilization이 떨어진다. 특히 생성된 output의 길이가 요청마다 차이가 클수록 심해진다.
Continuous batching
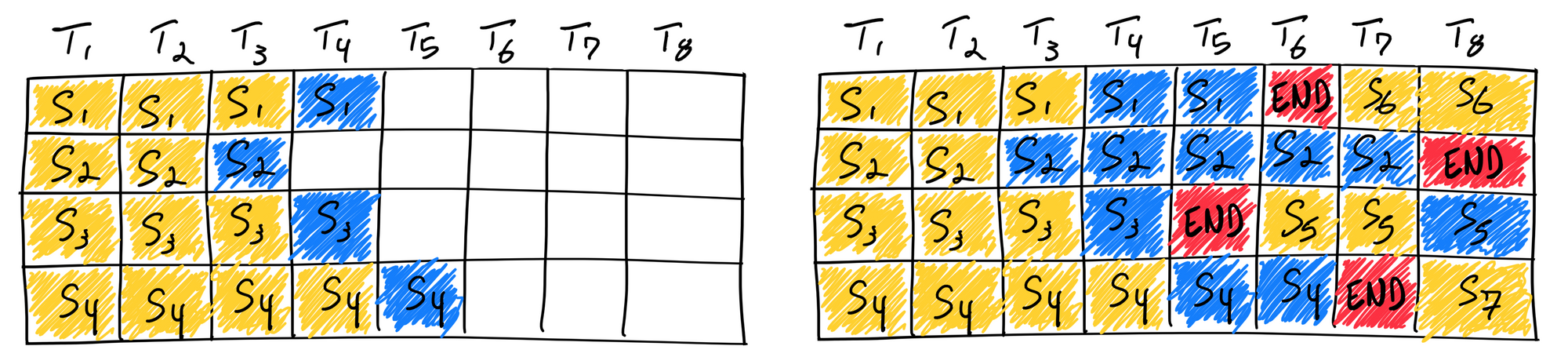
Orca 논문에서 하이퍼파라미터를 조절하여 iteration level로 스케줄링하는 배치 방법이 등장한다. 즉 빨리 끝난 요청은 곧바로 다음 요청을 받을 수 있게 된 것이다. 이로써 static batching보다 높은 GPU utilization을 가질 수 있게 된다.
Continuous batching을 도입하면서 이제 GPU utilization은 관심사가 아니게 되었다. 이제 throughput을 위해 batch에 담기는 요청의 개수를 늘리는 것이 중요해졌다. 이는 각 요청이 사용하는 메모리 크기에 의해 결정된다.
Transformer 모델에서 KV 캐시
Transformer 모델의 decoder는 토큰을 생성할 때 masked scaled dot-product attention 작업을 반복한다. 이때 각 생성 단계에서 이전 토큰들의 attention을 재계산하게 되는데, 이전에 계산한 값들을 다시 쓸 수 있다면 많은 자원을 아낄 수 있을 것이다.
KV cache는 이전에 계산한 Key와 Value 값을 캐싱하여 새로운 토큰에 대한 attention만 계산할 수 있도록 돕는다.
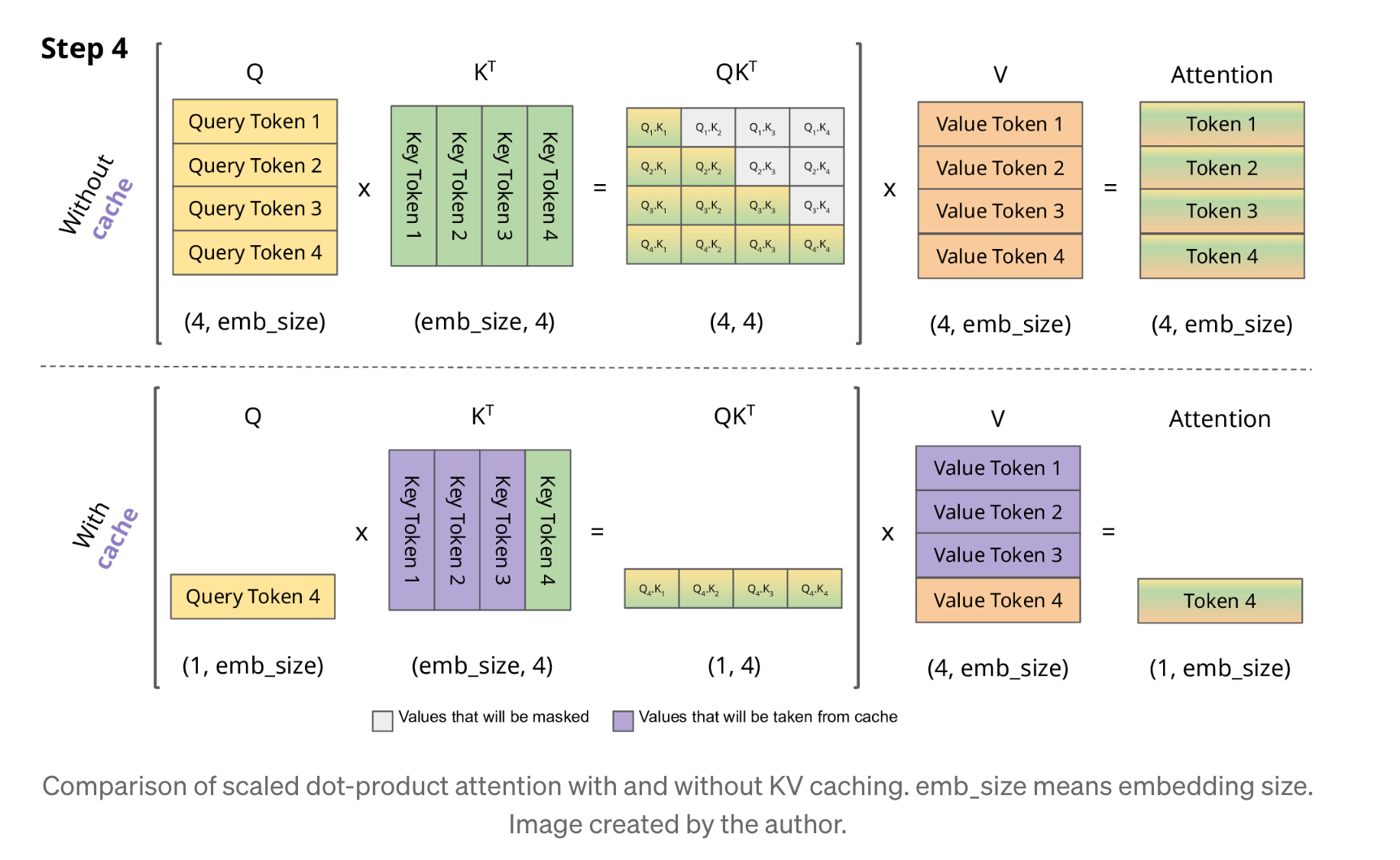
output 토큰을 생성할 때마다 이전 Attention을 다시 계산하게 된다. Attention 계산은 행렬곱이기 때문에 4번째 토큰의 Attention 값을 계산하면서 1,2,3번째 토큰의 Attention을 다시 계산하는 것이다.
하지만 4번째 iteration에서 필요한 값은 4번째 토큰의 Attention이기 때문에 실제로 필요한 것은 Query Token4, Key Token 1,2,3,4, Value Token 1,2,3이다. 만약 Key Token 1,2,3과 Value Token 1,2,3을 미리 저장해놓았으면 반복되는 계산을 크게 줄일 수 있다.
KV 캐시는 이러한 반복 계산되는 값을 미리 저장한다. 위 그림에서 KV 캐시는 보라색으로 표시된 Key Token 1,2,3과 Value Token 1,2,3을 저장한다.
각 인퍼런스 요청마다 프롬프트 토큰 및 output 토큰이 다르므로 KV캐시의 내용도 다를 것이기에 각각 메모리 할당이 필요하다.
KV 캐시 메모리 관리 문제
LLM 서빙시 높은 throughput을 만들려면 많은 요청을 배치로 한번에 처리하는 것이 필요하다. 하지만 각 요청마다 kv 캐시 메모리가 너무 크거나 동적으로 크기가 변동되는 것이 심하여 이를 잘 처리하는 것이 어렵다. 제대로 처리하지 못한다면 메모리가 단편화되거나 중복으로 낭비되어 사용하는 배치 크기가 제한된다.
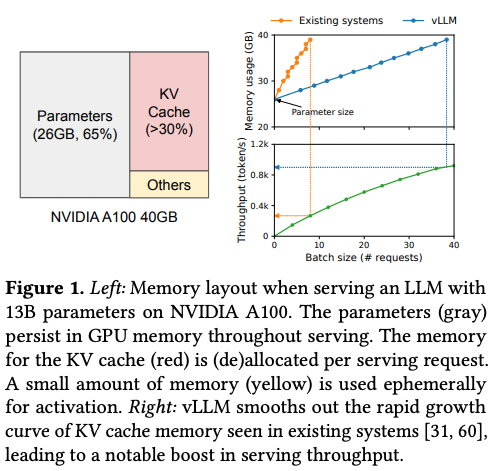
그림을 보면 13B 파라미터 LLM을 서빙하는 NVIDIA A100의 메모리 상태를 보여주고 있다. 65%를 차지하는 파라미터 영역은 모델 weight가 차지하며 서빙 중 항상 존재하는 영역이다. 30%의 영역은 kv 캐시가 차지하는 영역이다. 파라미터 영역의 메모리를 줄이는 것은 불가하기 때문에 kv 캐시가 차지하는 메모리를 어떻게 관리하냐가 최대 배치 크기를 결정한다.
vLLM 이전의 LLM 서빙 시스템은 kv 캐시 메모리를 연속적인 메모리 영역에 저장하였다. 하지만 kv 캐시 메모리는 동적으로 늘었다 줄어들기 때문에 이러한 저장 방식은 비효율을 초래하였다.
(1) internal, external memory fragmentation을 겪을 수 있다.
기존 프레임워크는 kv 캐시를 저장하기 위해 미리 요청의 최대 길이로 연속적인 메모리를 할당하였다. 하지만 실제 요청이 필요한 메모리 크기는 이보다 훨씬 짧기 때문에 이로 인해 internal memory fragmentation가 발생한다. 또한 미리 할당하는 것 자체가 비효율적인데, 요청 처리 중 사용하지 않는 메모리가 존재하더라도 다른 요청이 동시에 이를 사용하지 못하기 때문이다.
또한 각 요청마다 할당되는 크기가 달라 external memory fragmentation이 발생할 수 있다.
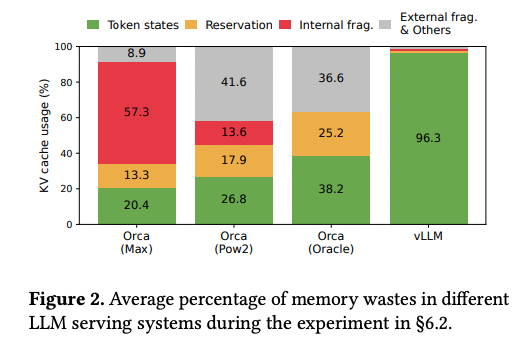
Figure 2를 보면 실제 KV 캐시 메모리 영역 중 사용되는 영역은 20.4 ~ 38.2%임을 확인할 수 있다.
(2) 메모리 공유를 하지 못한다.
LLM 서비스는 Parallel sampling이나 beam search 같은 병렬 디코딩 알고리즘을 사용한다. (Parallel sampling은 하나의 input 프롬프트가 여러 sequence들을 만들어 유저가 고를 수 있게 하는 방법, Beam search는 각 iteration마다 top k개의 후보군을 결정하는 방법)
이런 경우 요청들은 중복되는 KV 캐시를 가지고 있는데 현재 시스템에서는 각 요청이 분리되어 있는 연속적인 공간에 KV 캐시를 가지고 있기 때문에 공유가 불가능하다.
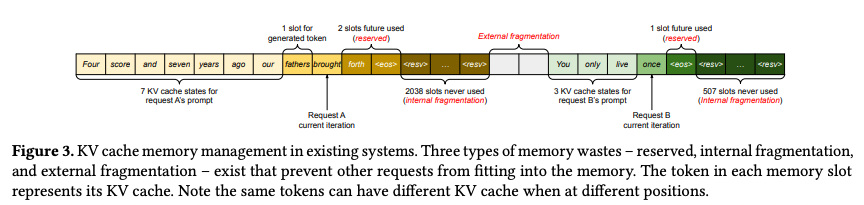
위 그림을 보면 기존 프레임워크에서 발생하는 3가지 유형의 메모리 낭비를 알 수 있다.
- reserved slots for future token
- internal fragmentation
- external fragmentation
vLLM 구조
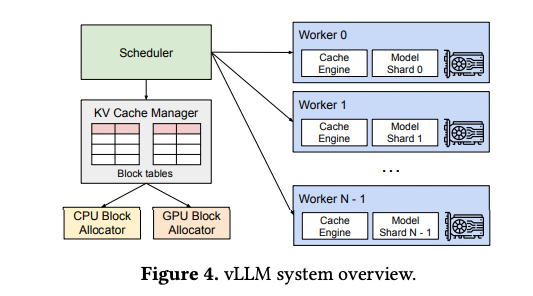
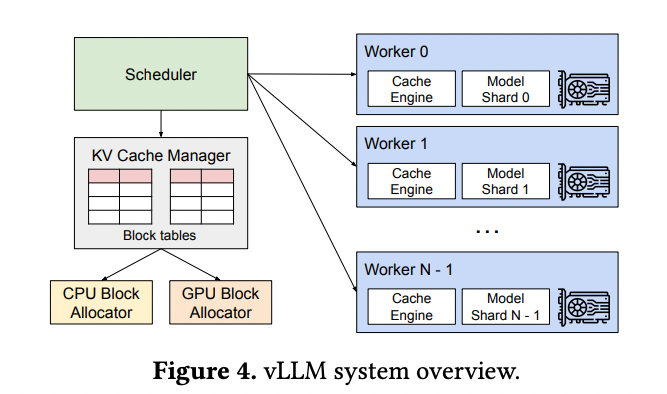
vLLM은 위와 같은 아키텍처를 제시한다.
- 분산 GPU worker들을 관리하는 centralized scheduler를 도입하였다
- KV Cache Manager는 KV cache를 PagedAttention으로 관리한다
PagedAttention
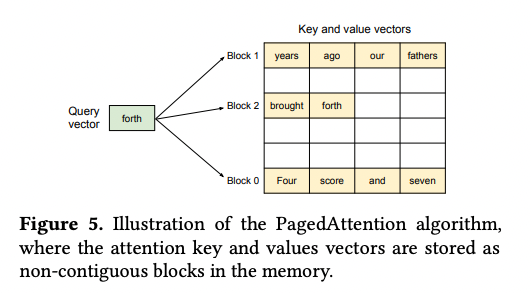
PagedAttention은 OS의 Paging 알고리즘에 영감을 받은 방법이다. OS는 메모리를 page 단위로 나누어 저장한다. PagedAttention은 이와 비슷하게 각 sequence의 KV 캐시를 KV 블록으로 나누고 비연속적인 메모리 공간에 Key Value를 저장한다.
위 그림을 보면 3개의 블록이 물리 메모리에 연속적으로 저장되어 있지 않은 것을 볼 수 있다.
KV Cache Manager
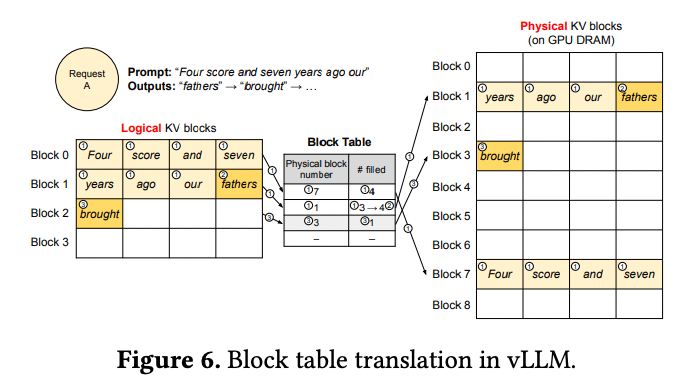
vLLM의 memory manager는 OS의 virtual memory에 비유할 수 있다.
OS는 메모리를 고정된 크기의 페이지들로 나누고 유저 프로그램의 logical page를 물리 page와 매핑한다. 연속된 logical page들은 비연속적인 물리 메모리 페이지들과 대응되고 유저 프로그램이 연속된 메모리에 접근하는 것처럼 보여준다. 또한 physical memroy가 미리 reserve될 필요 없다.
vLLM은 virtual memory 뒤에서 이러한 아이디어를 사용하여 LLM 서비스의 KV cache를 관리한다. KV block manager는 block table을 관리하여 각 요청의 logical block과 physical block을 매핑한다. 이를 통해 메모리 낭비 없이 vLLM이 KV cache memory의 크기가 동적으로 변경되는 것을 허용한다.
위 그림을 보면 vLLM은 첫 2개의 logical KV block을 분리된 2개의 physical KV block들로 매핑한다. 이후 decoding step에서 logical block이 다 차면 새로 생성한 KV 캐시를 새로운 logical block에 저장한다. vLLM은 새로운 physical block을 할당하고 이를 block table에 매핑한다.
vLLM의 decoding 사례
Parallel Sampling
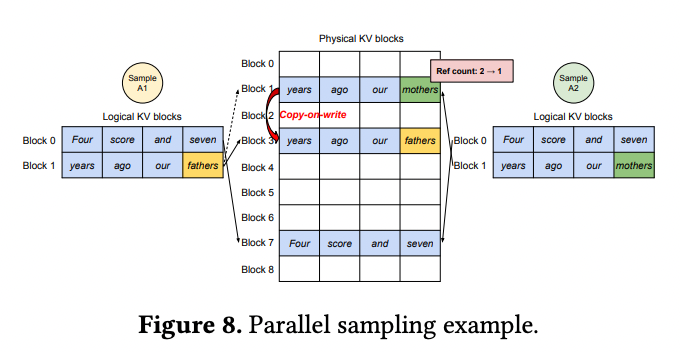
Parallel sampling은 한 요청이 같은 input 프롬프트를 공유하는 여러 샘플들을 포함한다.
Paraell sampling에서는 여러 아웃풋이 같은 프롬프트를 공유하기 때문에 prompt phase에서 한 카피의 프롬프트 상태만 저장하면 된다. 위 그림에서 두 sequence의 logical block들은 같은 physical block들로 매핑되어 있다. 각 physical block에 reference count를 도입하여 한 physical block에 몇 개의 logical block이 매핑되어 있는지 표시한다.
생성 phase에서 두 sequence가 생성하는 샘플이 다르다면 다른 저장 공간이 필요하다. 이때 vLLM은 copy on write를 메커니즘을 사용하는데, OS 가상 메모리가 프로세스를 fork하는 방식과 유사하다. 위 예에서는 마지막 logical block만 바뀌었기 때문에 vLLM이 block 7은 그대로 두고 block1을 block3로 copy-on-write하는 것을 확인할 수 있다.
Beam Search
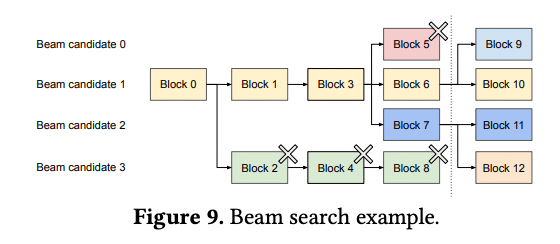
이전 LLM 서빙 시스템은 beam candidate간 kv cache copy를 자주 요구했다. 예를 들어 위 그림에서 점선 이후 candidate 3는 candidate 2의 대부분의 KV 캐시를 복사할 필요가 있었다.
vLLM은 대부분의 beam cnadidate 블록을 공유함으로써 이런 memory copy overhead를 줄였다.
Scheduling and Preemption
OS가 어떤 page를 evict해야할지 결정해야 했던 것처럼 vLLM도 비슷한 문제를 마주하였다.
(1) 어떤 블록이 evict되야 하는가?
(2) evict된 블록이 다시 필요하다면 어떻게 recover할 것인가?
일반적으로 eviction 정책은 미래에 어떤 블록이 접근되고 어떤 블록을 evict할 것인지 예측하는 휴리스틱을 사용한다.
vLLM은 시퀀스의 모든 블록이 함께 접근되야 하기에 all or nothing eviction 정책을 구현하였다. Beam Search처럼 한 요청에 여러 sequence가 있다면 sequence group으로서 gang schedule을 사용한다.
preempt로 인해 evict된 블록을 복구하는 방법은 Swapping 혹은 Recomputation을 사용한다.
(1) Swapping
evict된 block을 cpu 메모리에 복사해놓는다. vLLM은 CPU block allocator가 있기에 physical block을 CPU RAM에 swap하는 것이다.
어떤 sequence를 preempt하고 그 블록들을 evict할 때 vLLM은 preempt된 sequence들이 완료될때까지 새로운 요청들을 받는 것들을 멈춘다. 요청이 완료되면 preempt된 sequence들의 블록들을 다시 복구시킨다.
(2) Recomputation
단순히 preempt된 sequence가 다시 스케줄되었을 때 KV 캐시를 재계산하는 방식이다. 다만 재계산 latency는 원래의 latency보다 짧은데 decoding 단계에서 생성된 토큰들을 원본 유저 프롬프트에 붙여 모든 position의 KV 캐시를 단 한번의 phase iteration에서 생성할 수 있기 때문이다.
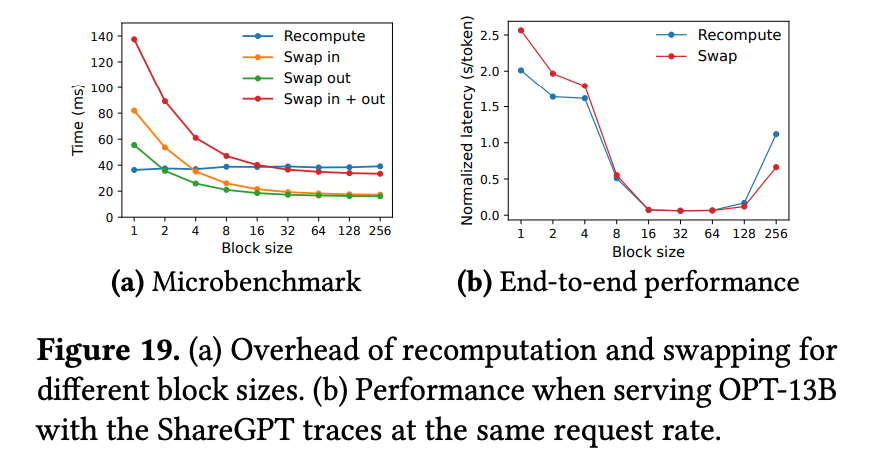
두 방법을 비교하면 Swapping이 블록 크기가 작을 때 더 큰 오버헤드를 동반한다. 작은 블록 크기는 CPU와 GPU 사이 더 많은 데이터 이동을 만들고 이는 PCIe bandwidth에 제한된다. 따라서 block size가 작으면 recomputation이 유리하고 크면 swap이 유리하다.
분산 실행
많은 LLM들은 한 GPU의 용량을 넘는 파라미터 크기를 가지고 있어 분산 GPU에 이들을 나누고 분산 실행할 필요가 있다.
vLLM은 Transformer에서 널리 사용되는 Megatron-LM style tensor model parallelism strategy에 효과적이다. 이 startegy는 SPMD(Single Program Multiple Data)와 연관되어 있다. 특히 multihead attention에서 각 SPMD는 attention head의 subset들을 처리한다.
모델 병렬 실행시 여전히 각 샤드가 같은 input token set을 처리하여 같은 KV cache가 필요한 상황이 자주 있어 중앙 스케줄러 내 하나의 KV Cache Manager를 공유하도록 하였다. 그래서 각 GPU Worker는 스케줄러로부터 받은 physical block으로부터 모델을 실행하고 해당하는 부분의 KV cache만 저장한다.
요약하면 Decoding iteration 시작마다 GPU worker는 스케줄러로부터 block table을 받기 때문에 따로 메모리 관리를 synchronize할 필요가 없다.
Evaluation
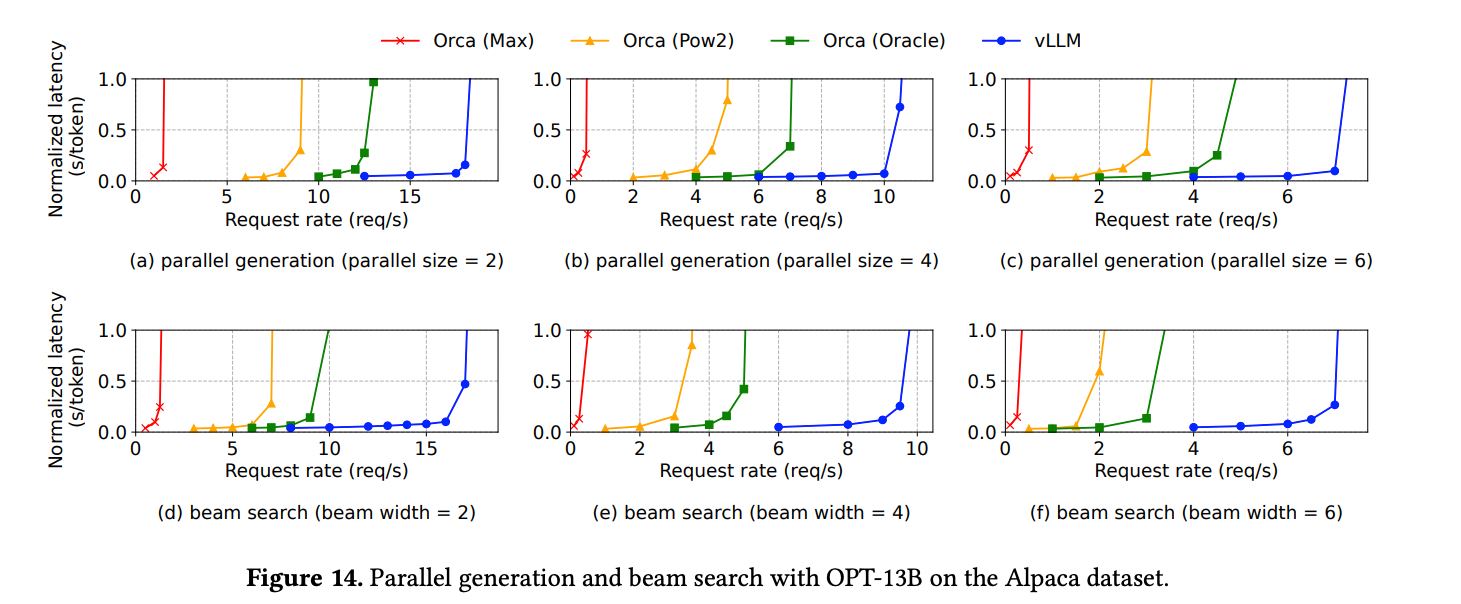
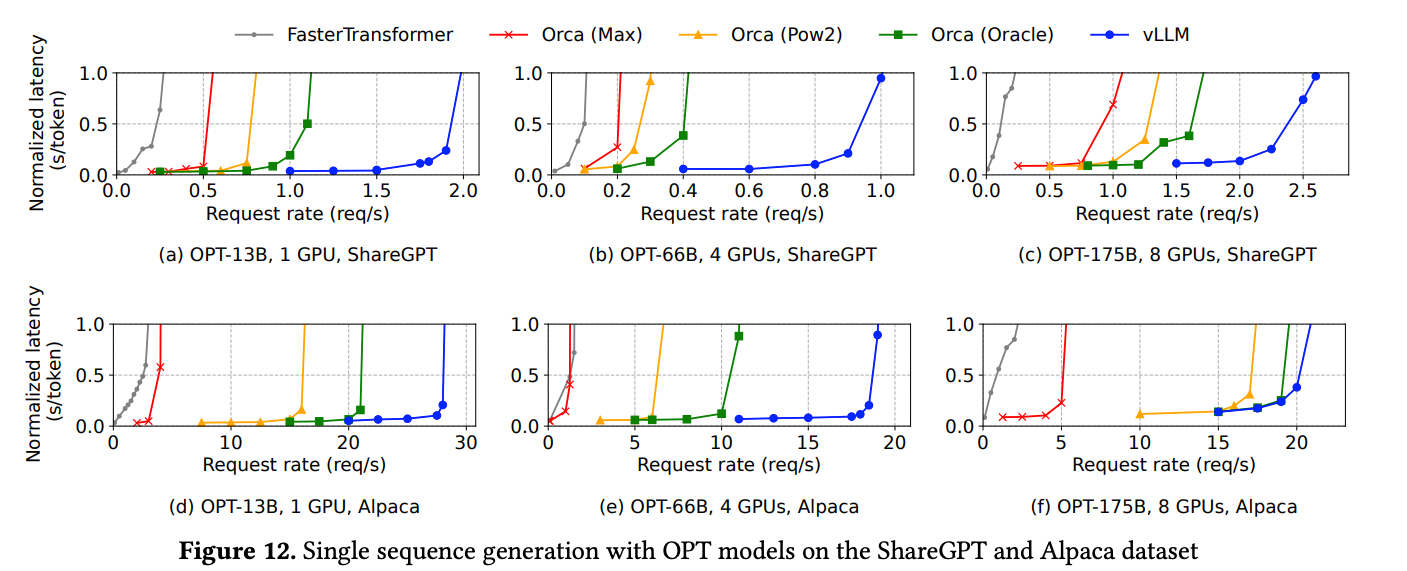
비슷한 레벨의 Normalized latency에서 vLLM 사용시 Request rate가 확연히 증가한 것을 알 수 있다.
그 외에도 Parallel sampling 및 Beam search에서 메모리를 아낄 수 있었다는 평가 지표도 있었다. 더 자세한 내용을 알고 싶으면 논문을 참고하면 좋다.
Discussuion - 다른 GPU workload에 virtual memroy 및 paging technique 도입
모든 GPU workload에 대해 이 방식이 효과적인 것은 아니다. DNN training과 같이 tensor의 shape이 정해진 것들은 메모리 할당이 더 효과적이다. DNN serving도 compute-bound이기 때문에 메모리 효율 증가가 성능에 영향을 미치지 못할 것이다.