
[Paper review] On-demand Container Loading in AWS Lambda
![[Paper review] On-demand Container Loading in AWS Lambda](https://images.unsplash.com/photo-1682686578023-dc680e7a3aeb?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wxfDF8c2VhcmNofDF8fGhpa2luZ3xlbnwwfHx8fDE3MTE4MDIwMTh8MA&ixlib=rb-4.0.3&q=80&w=2000)
[Summary]
- On-demand Container Loading in AWS Lambda introduces how to reduce scalability and cold start latency by introducing Block-level loading, Deduplication, and tiered cache.
- Block-level loading makes an image into a single file system through a flattening process, then divides it into chunks and uploads it to the cache.
- When uploading an image to the cache, the image with the same content is deduplicated as much as possible. The risk of this is adjusted by adding an additional salt to the key.
- AWS's tiered cache uses erasure coding, consistency-limited system, and LRU-K.
[Contents]
- a brief introduction to the paper
- Prerequisite: overlayFS, virtio-blk
- AWS Lambda's Existing Architecture
- Block-Level Loading
- image deduplication
- Tiered cache
1. A brief introduction to the paper
On-demand Container Loading in AWS Lambda is awarded paper at USENIX ATC 23.
This paper introduces how to reduce scalability and cold start latency by introducing Block-level loading, Deduplication, and Tier cache.
The cold start latency refers to the time it takes to scale up when the load increases. To reduce the cold start latency, reducing data movement is key. Users distribute functions in a compressed form (.zip) to Lambda, and decompress each function instance whenever it is assigned.
Currently, AWS Lambda aims to support the creation of 15,000 containers per second for each user. If the image of each container is 10GB, one user uses a network bandwidth of 150PB per second.
2. Prerequisite: overlayFS, virtio-blk
Before reviewing the paper, let's briefly explain the overlay filesystem and virtio-blk.
Overlay Filesystem (overlayFS)
An overlay filesystem is a filesystem that allows you to union two or more directories. Union is when you combine multiple directories to make them look like a single, unified directory.
The target of the union directory created by the Overlay filesystem can be divided into a list of lower directories and one upper directory. The lower directory is read only, while the upper directory is both readable and writable.
Let's take a look at an example.
$ ls
lower merge upper work
$ mount -t overlay overlay-example -o lowerdir=lower/,upperdir=upper/,workdir=work/ mergeIn the example, the merge directory is the unioned directory. When you look at the merge directory, you can see files from both the lower and upper directories. The work directory is an intermediate layer to ensure atomicity.
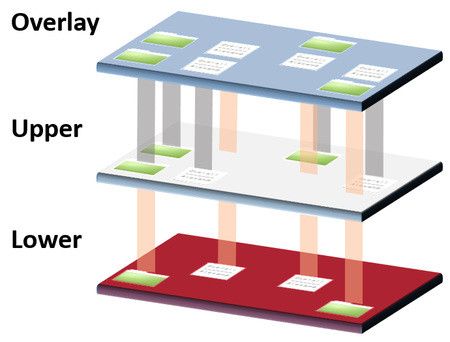
To understand container images, you need to know the Overlay Filesystem.
A container image is essentially a tar file with a root file system and metadata. When you run a container image, Docker downloads the tarball for the image and unpack each layer into separate directories. The overlay filesystem then creates an empty upper directory and mounts them to create a union directory. So anything the container writes is written to the empty upper directory, and the directories containing each layer remain unchanged.
virtio-blk
virtio stands for virtual io and blk stands for block.
virtio-blk is designed to provide a standard interface to the block device in a VM. With virtio-blk, you get near-native IO performance because you are communicating with the hypervisor using an optimized interface.
To understand virtio-blk, you need to be aware of two concepts.
- Paravirtualization: Providing a VM with a simple abstracted version of a device, rather than emulating the full hardware device. Faster than providing a full hardware device.
- Block device: A device that allows storage and retrieval of fixed-size chunks (blocks). Examples include hard drives, SSDs, etc.

With full virtualization, the guest OS runs on top of the hypervisor and the guest doesn't know it's virtualized and doesn't need to set it up.
Paravirtualization must include code that not only knows that the guest OS runs on top of the hypervisor, but also makes guest-to-hypervisor transitions efficient.

virtio is the abstraction layer of the paravirtualization hypervisor, and virtio-blk is the block device of that layer.
3. The existing architecture of Aws Lambda
First, let's look at the architecture of existing AWS Lambda from the paper above.
existing architecture
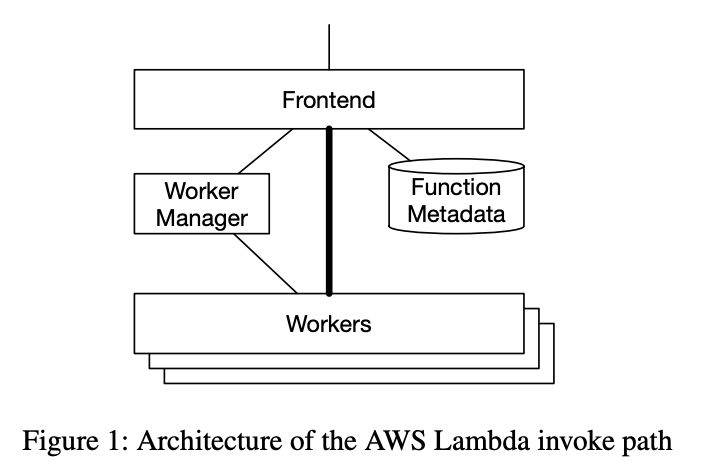
When a request for AWS Lambda comes to the frontend, it is authenticated and forwarded to Worker Manager.
For every unique function in the system, Worker Manager tracks the capacity to run the function.
- If there is enough capacity, forward to worker
- If that's not enough, it finds a worker with enough CPU and RAM and asks it to start a sandbox where it can run the function. Once this is done, the frontend is notified and the function is executed.
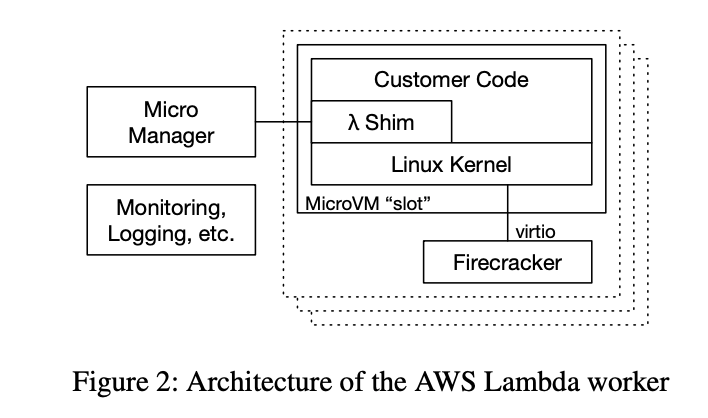
The structure of each Lambda Worker is shown above.
Micro Manager
- Agent for logging and monitoring
MicroVM
- There are a lot of them.
- It has a code for a single lambda function for one consumer.
- You have a minimized Linux guest kernel. This kernel is a small shim that provides lambda's programming model and runtime (JVM, CoreCLR, etc.), as well as your code and libraries.
- Because the user's code and data are untrusted, so the communication between the workload and the worker components inside the MicroVM is simple and well-tested. It is usually a certified implementation of virtio.
When a new MicroVM is created, the worker downloads the function image from Amazon S3 and unpack it into the MicroVM's guest file system.
Pros: Works well with simple, small images
Cons: MicroVMs can download and unpack entire archives before they can work on them
4. Block-Level Loading
To overcome the shortcomings of the existing architecture, it was necessary to ensure that the system could only load the data that the application needed.
To achieve this, we decided to keep the block-level virtio-blk interface between the Micro VM guest and the hypervisor running the file system operations inside the guest. This allows us to perform sparse loading of blocks, not files.
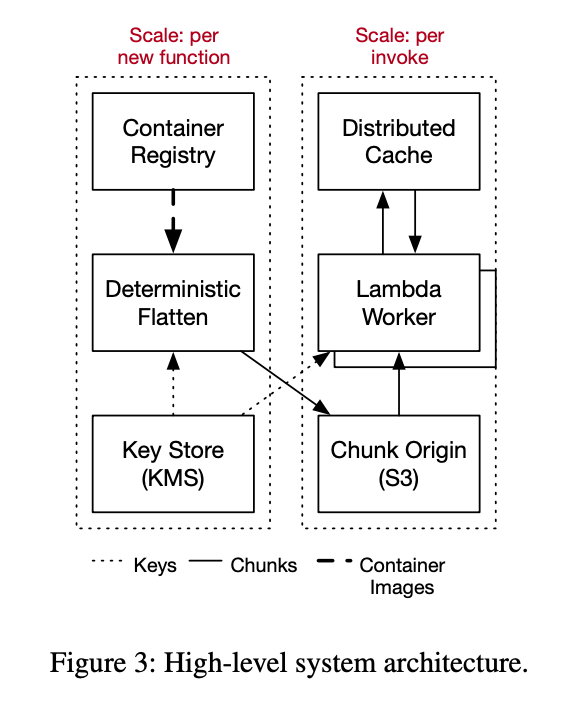
- Lambda worker: Runs the user's code
- Container Registry: Holds the primary copy of the user's container image
To support block level loading, we split the container image into block device images.
Typically, image layers in a container stack are overlaid using overlayFS at runtime, as we saw in (2).
However, in the paper, AWS states that the overlay operation is only performed the first time a function is created and that each layer creates one ext4 file system(a flattening process). Function creation is triggered only when a user makes modifications to the code, configuration, or architecture, which occurs at a low rate.
The flattening process enables block-level deduplication of flattened images between containers that have the same file system block and share a common base layer. The flattening process unwinds each layer into a single ext4 file system. At this point, AWS has modified the file system to perform all operations deterministically, which allows for serial and deterministic selection of variables such as modification dates (most file system implementations introduce concurrency for performance).
A flattened file system is divided into fixed-sized chunks and most of the chunks are uploaded to a cache(in this paper, we used S3). Chunk names are created using the content they have, so chunks with the same content are guaranteed to have the same name and are only cached once.
The fixed size of a chunk is 512 KiB. Smaller size reduces false sharing and has high random access performance. Larger sizes reduce the size of metadata and reduce data load requests.
The new architecture with block level loading is shown below.
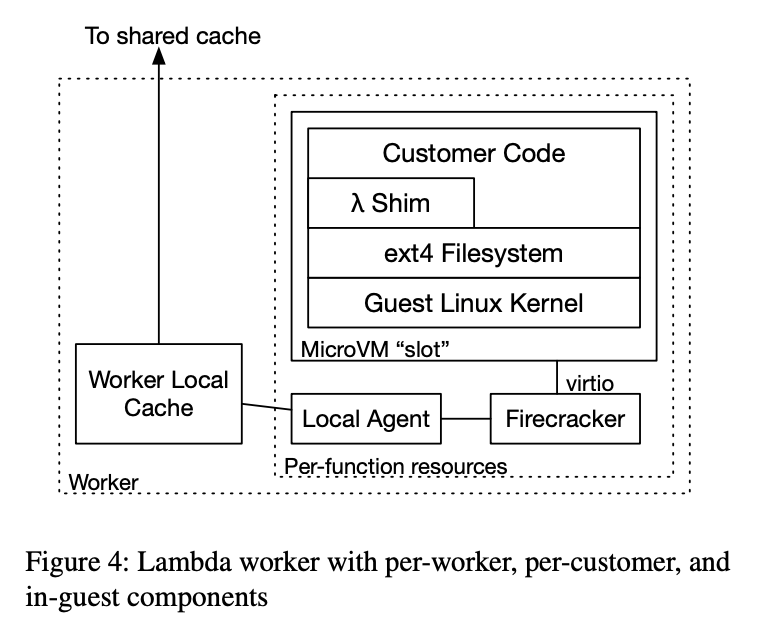
Two components have been added to access chunks in the new architecture.
- per-function local agent: Represents a block device to the Firecracker hypervisor.
- per-worker local cache: Caches frequently used chunks in the worker and interacts with the remote cache.
When the Lambda function starts fresh on the worker, Micro Manager creates a Firecracker MicroVM with a new local agent and two virtio block devices. When this MicroVM boots, it runs the supervisory components and the user code of the container image. Each IO that the code executes goes into a virtio-blk request, which is executed by Firecracker and passed to the local agent.
The local agent fetches the relevant chunk from the tiered cache if the chunk exists in the local cache, if not reading it directly. The local agent writes to the block overlay in the worker storage when writing. It also maintains a bitmap that indicates whether the data should be read from the overlay or the backing container.
5. Image deduplication
Since most of them use similar base container images, we found that 80% of newly uploaded Lambda functions had zero unique chunks and were re-uploads of previously uploaded images. Therefore, deduplicating images is a big help.
When encrypting an image, it is difficult to deduplicate because encrypting the same content with different keys will produce different results.
During the flattening process, AWS computes a SHA256 digest from each chunk to obtain the key and encrypts the block using AES-CTR. AES-CTR guarantees that if the encrypted result is the same, it is the same plaintext.
Deduplication has cost and performance benefits, but it also has risks.
- Because certain chunks are heavily used, access to them may fail or be slow, which affects the entire system.
- Corrupted data, if any, can be detected but not fixed
To address this risk, it includes a variety of salts in the process of obtaining the key. The salt depends on the time of day, the popularity of the chunk, and the location of the infrastructure. Different salts for the same chunk will have different ciphertexts, so they do not deduplicate each other. You can adjust the tradeoffs by controlling how often the salt is rotated.
6. Tiered cache
Tiered Cache of AWS
AWS uses a tiered approach to caching. If a chunk isn't in the local cache, the worker fetches it from the remote AZ level shared cache. If it's not there, it downloads it from S3 and uploads it to cache.
Let's take a look at what caching techniques AWS uses.
(1) Til latency
A simple replica-less cache scheme causes three main problems.
Til latency
- One slow cache server causes a widespread impact
Hit Rate Drops
- If the item is only on one single server, the server will fail or the hit rate will plummet upon deployment.
Throughput Bounds
- If the item is on a single server, it is bounded by that server's bandwidth.
Of these three issues, Til latency was the biggest problem. When fetching 1000 chunks, the 99.9th percentile tail latency of the cache accounted for 63% of all tasks.
Replication can be used to reduce til latency and solve throughput and hit rate problems. However, replicaiton has the disadvantage of increasing costs.
Instead, AWS opted for erasure coding. When a worker misses a cache, it fetches the chunk from the source and uploads the erasure-coded chunk to the cache. When a worker fetches a chunk, it requests more stripes than it needs to rebuild the chunk. Currently in production, we are using 4 of 5 code, which has a 25% storage overhead and has created a significant reduction in til latency. This has effectively prevented cache nodes from failing or the hit rate from dropping on deployment.
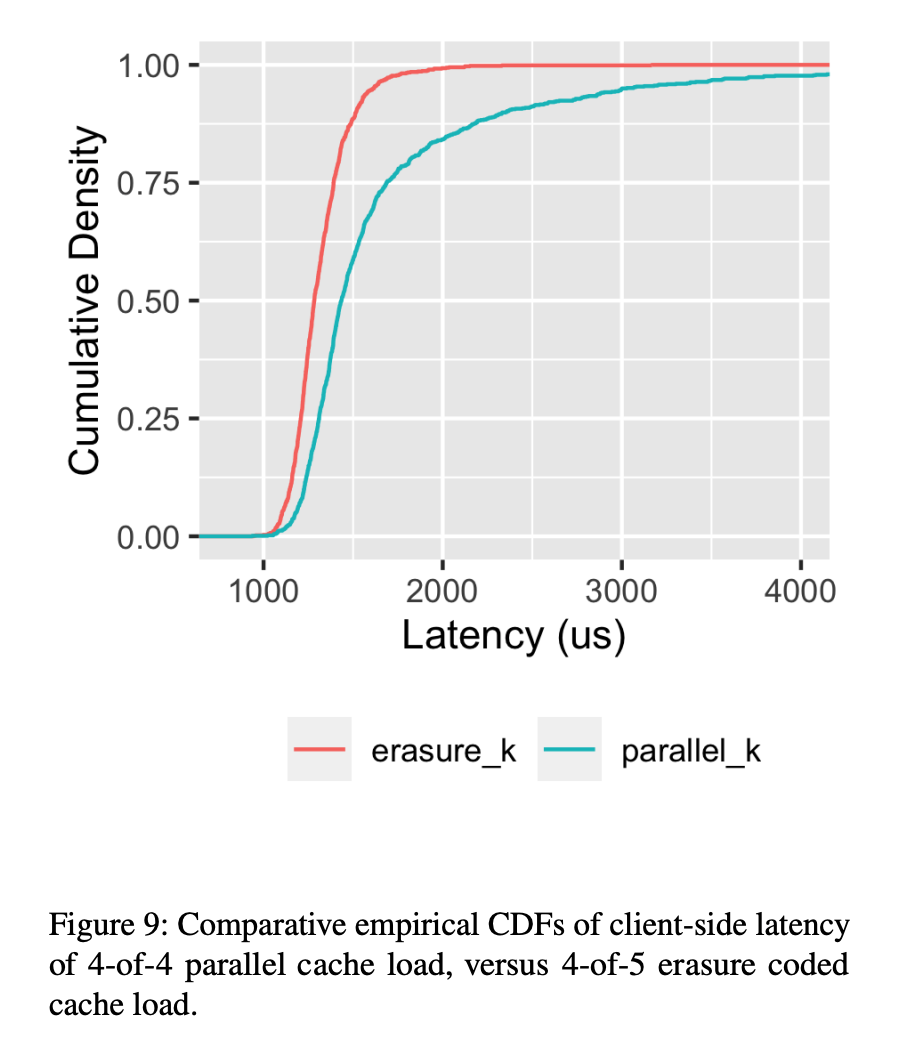
(2) stability
High cache hit rates have a hidden downside. If the cache is empty (due to poser loss or operational issues) or if the hit rate suddenly drops (due to a change in user behavior), traffic to downstream services can suddenly spike.
In AWS, the cache end-to-end hit rate was 99.8%, but downstream traffic could spike 500 times higher than normal. Increased latency downstream causes high concurrency demand, which leads to an increase in lambda slots.
Designing a concurrency-limited systemcan address this to some extent. When the number of concurrent tasks exceeds the limit, new containers are rejected until one is finished.
(3) Cache eviction and sizing
Traditional cache policies are simple and easy to implement, like LRUs or FIFOs. However, in the case of AWS, there are issues with applying them.
This was because recently-used entries from infrequently used functionswere sometimes replacing all the hot entries in the cache, reducing the cache hit rate. This was happening over and over again due to periodic cron job functions, where there are many of them, but each of them runs at a low scale, significantly reducing the role of the cache.
To reduce the reduction in cache hit rate caused by these periodic operations, we use the LRU-k eviction algorithm. LRU-K tracks the last K occurrences of an item in the cache.
Reference