
eBPF/XDP: 당신만 모르는 안전하고 빠른 Networking

[요약]
- eBPF: kernel space 내에서 프로그램을 실행할 수 있도록 하여 어플리케이션 개발자가 런타임에 OS의 기능을 사용할 수 있도록 하는 기술
- XDP: eBPF를 기반으로 한 기술로 packet processing을 할 수 있도록 지원
- XDP는 XDP driver hook 및 eBPF virtual machine 등으로 구성되어 있고 높은 성능으로 안전하게 kernel space에서 packet processing을 할 수 있다.
- Cilium을 비롯한 많은 프로젝트와 구글, 네이버 등 많은 기업들이 활용하고 있다.
1. 들어가며
개발 컨퍼런스나 여러 테크 기업에서 eBPF가 주제로 등장한지 꽤 오랜 시간이 지났다. 그럼에도 불구하고 eBPF는 관련 도메인에 익숙하지 않다면 이해하기 쉽지 않다. 또한 관련 한국어 자료들의 수가 적고 간략하게 설명한 것들이 대부분이라 더욱 어렵게 느껴질 수 있다.
이번 글은 XDP의 설계를 보여준 “The eXpress Data Path: Fast Programmable Packet Processing in the Operating System Kernel”(2018) 을 살펴볼 것이다. 처음부터 논문 내용을 다루면 어려울 수 있어 eBPF와 XDP 사용 예제를 보며 감을 잡을 것이다. 또한 eBPF를 활용한 오픈소스인 Cilium과 네이버에서 NAT를 구현하는데 eBPF를 사용한 사례를 공유하여 eBPF 사용 예시를 보여줄 것이다.
이 글이 eBPF/XDP을 처음 접하는 사람들에게 도움이 되었으면 좋겠다.
2. 예제로 알아보는 eBPF/XDP
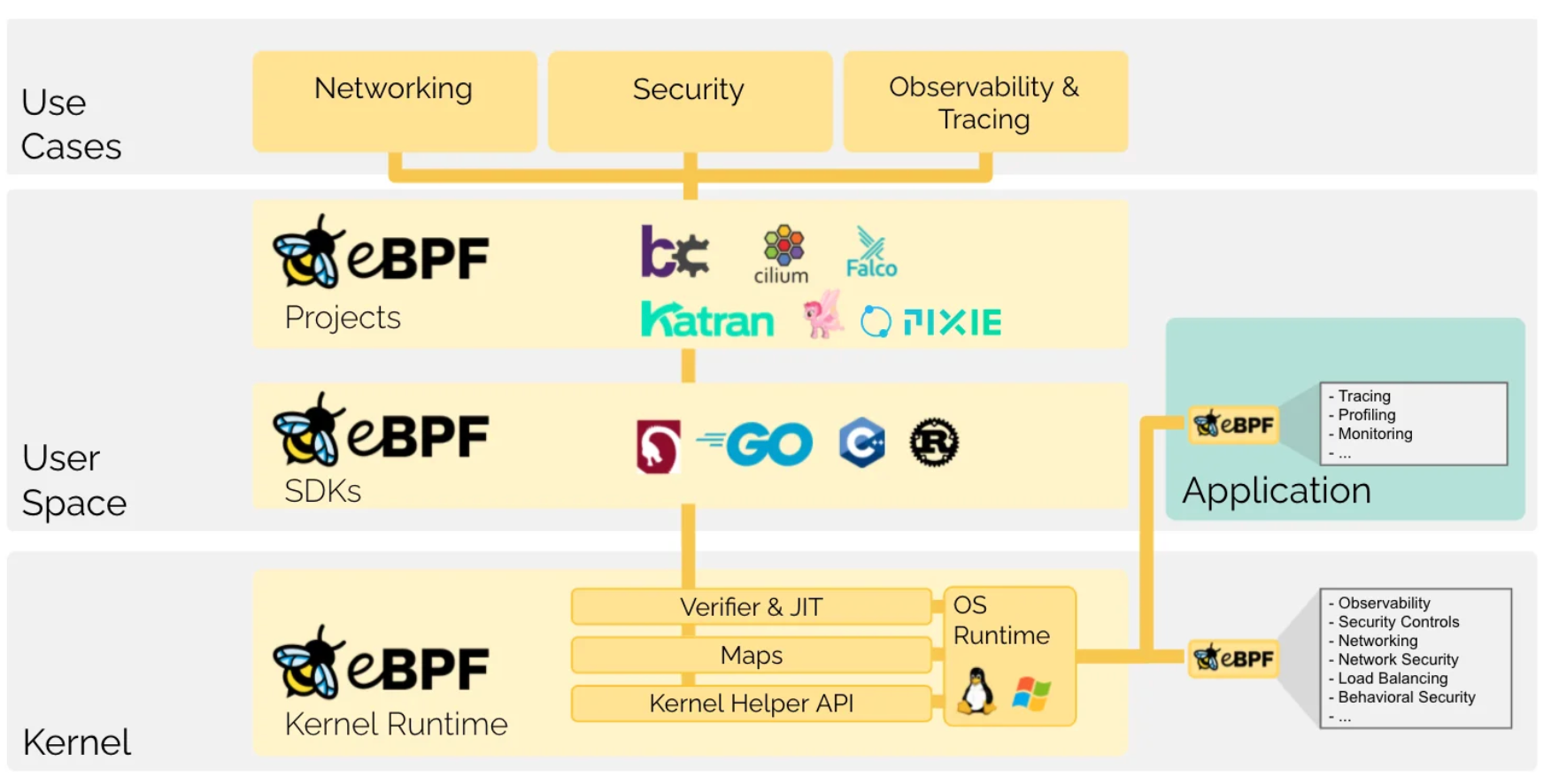
OS는 virtual memory를 사용하여 주소 공간을 user space와 kernel space로 분리한다. 두 주소 공간을 사용하는 레이어는 분리되어 있으며 user space는 유저 어플리케이션과 시스템 데몬 등이 사용하고, kernel space는 Linux kernel이 사용한다.
Linux kernel은 user space를 사용하는 어플리케이션과 다르게 높은 권한을 가지고 있어 시스템을 관찰하거나 제어하기 훨씬 용이하다. 그러나 kernel이 OS에서 중요한 역할을 맡고 있어 안정성과 보안에 높은 요구사항을 받아와 빠르게 발전하기 어려웠다.
eBPF는 kernel space 내에서 프로그램을 실행할 수 있도록 하여 어플리케이션 개발자가 런타임에 OS의 기능을 사용할 수 있도록 하는 기술이다.
XDP(eXpress Data Path)는 eBPF를 기반으로 한 기술로 eBPF 프로그램이 packet processing을 할 수 있도록 지원해준다.
예제를 살펴보면서 이해를 높여보자.
2.1 어플리케이션에서 eBPF(XDP) 사용하기
해당 예제는 ebpf-go의 예제를 재구성하였습니다.
목표: eth0 인터페이스로 들어오는 패킷의 수를 세는 프로그램을 만들기
다음과 같은 과정으로 진행한다.
(1) 커널에서 돌아가는 eBPF 프로그램 작성
(2) eBPF로 컴파일 및 golang 코드 생성
(3) 해당 eBPF 프로그램을 load 및 통신하는 golang 어플리케이션 작성
(1) 커널에서 돌아가는 eBPF 프로그램 작성
우리는 eBPF 프로그램을 빌드하기 위해 C로 코드를 작성하고 LLVM으로 컴파일할 것이다.
먼저 다음과 같은 파일 counter.c를 작성하자.
//go:build ignore
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__type(key, __u32);
__type(value, __u64);
__uint(max_entries, 1);
} pkt_count SEC(".maps");
// count_packets atomically increases a packet counter on every invocation.
SEC("xdp")
int count_packets() {
__u32 key = 0;
__u64 *count = bpf_map_lookup_elem(&pkt_count, &key);
if (count) {
__sync_fetch_and_add(count, 1);
}
return XDP_PASS;
}
char __license[] SEC("license") = "Dual MIT/GPL";pkt_count는 패킷의 수를 기록하는 구조체이다. eBPF에서 map 구조체로 사용된다. __uint와 __type은 eBPF maps에서 사용하는 macro다.
count_packets은 호출될 때마다 pkt_count의 카운터를 증가시킨다. 좀 더 자세히 살펴보면 bpf_map_lookup_elem이 pkt_count에서 key와 관련된 value를 가져오고, __sync_fetch_and_add가 1을 증가시킨다.
(2) eBPF로 컴파일 및 golang 코드 생성
counter.c를 오브젝트 파일로 컴파일하고 그와 대응되는 golang 코드를 생성해볼 것이다.
먼저 Golang toolchain을 사용하기 위해 Go module을 정의하고 bpf2go를 받아오자.
$ go mod init ebpf-test && go mod tidy
$ go get github.com/cilium/ebpf/cmd/bpf2go다음과 같은 gen.go 코드를 작성하자.
package main
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go counter counter.cbpf2go는 clang을 사용해 counter.c를 오브젝트 파일로 빌드하고 대응되는 golang 코드를 생성해준다.
$ ls
counter.c counter_bpfeb.go counter_bpfeb.o counter_bpfel.go counter_bpfel.o gen.go go.mod go.sum생성된 golang 코드들은 eBPF 프로그램이 생성한 객체를 사용할 수 있도록 함수 및 struct를 정의한다.
// loadCounterObjects loads counter and converts it into a struct.
//
// The following types are suitable as obj argument:
//
// *counterObjects
// *counterPrograms
// *counterMaps
//
// See ebpf.CollectionSpec.LoadAndAssign documentation for details.
func loadCounterObjects(obj interface{}, opts *ebpf.CollectionOptions) error {
spec, err := loadCounter()
if err != nil {
return err
}
return spec.LoadAndAssign(obj, opts)
}
....
// counterObjects contains all objects after they have been loaded into the kernel.
//
// It can be passed to loadCounterObjects or ebpf.CollectionSpec.LoadAndAssign.
type counterObjects struct {
counterPrograms
counterMaps
}
// counterMaps contains all maps after they have been loaded into the kernel.
//
// It can be passed to loadCounterObjects or ebpf.CollectionSpec.LoadAndAssign.
type counterMaps struct {
PktCount *ebpf.Map `ebpf:"pkt_count"`
}
// counterPrograms contains all programs after they have been loaded into the kernel.
//
// It can be passed to loadCounterObjects or ebpf.CollectionSpec.LoadAndAssign.
type counterPrograms struct {
CountPackets *ebpf.Program `ebpf:"count_packets"`
}(3) 해당 eBPF 프로그램을 load 및 통신하는 golang 어플리케이션 작성
위에서 생성한 counter_bpfeb.go, counter_bpfel.go을 사용해 eBPF를 로드하고 통신하는 어플리케이션을 작성해보자.
func main() {
// Remove resource limits for kernels <5.11.
if err := rlimit.RemoveMemlock(); err != nil {
log.Fatal("Removing memlock:", err)
}
// Load the compiled eBPF ELF and load it into the kernel.
var objs counterObjects
if err := loadCounterObjects(&objs, nil); err != nil {
log.Fatal("Loading eBPF objects:", err)
}
defer objs.Close()
ifname := "eth0" // Change this to an interface on your machine.
iface, err := net.InterfaceByName(ifname)
if err != nil {
log.Fatalf("Getting interface %s: %s", ifname, err)
}
// Attach count_packets to the network interface.
link, err := link.AttachXDP(link.XDPOptions{
Program: objs.CountPackets,
Interface: iface.Index,
})
if err != nil {
log.Fatal("Attaching XDP:", err)
}
defer link.Close()
log.Printf("Counting incoming packets on %s..", ifname)
// Periodically fetch the packet counter from PktCount,
// exit the program when interrupted.
tick := time.Tick(time.Second)
stop := make(chan os.Signal, 5)
signal.Notify(stop, os.Interrupt)
for {
select {
case <-tick:
var count uint64
err := objs.PktCount.Lookup(uint32(0), &count)
if err != nil {
log.Fatal("Map lookup:", err)
}
log.Printf("Received %d packets", count)
case <-stop:
log.Print("Received signal, exiting..")
return
}
}
}loadCounterObjects는 컴파일된 eBPF 프로그램을 커널에 로드한다.
AttachXDP는 eBPF 프로그램의 count_packets 함수를 network interface에 attach한다. XDP에 대해서는 뒤이어 추가 설명하겠다.
빌드 후 어플리케이션을 실행하면 eth0로 들어오는 패킷 수를 셀 수 있다.
$ sudo ./ebpf-test
2024/07/07 02:19:20 Counting incoming packets on eth0..
2024/07/07 02:19:21 Received 5 packets
2024/07/07 02:19:22 Received 10 packets
2024/07/07 02:19:23 Received 16 packets
...2.2 XDP 단독으로 사용하기
해당 예제는 Get started with XDP 예제를 재구성하였습니다.
앞의 예제는 golang 어플리케이션이 eBPF 프로그램을 load하고 통신하는 것을 보여주었다. 이번에는 shell에서 XDP 프로그램을 로드하는 예제를 살펴보겠다.
목표: 특정 network interface의 패킷을 전부 drop 하는 XDP 프로그램 작성
다음과 같은 과정으로 진행한다.
(1) XDP 프로그램 작성 및 빌드
(2) 실험 대상 virtual network interface 생성
(3) XDP 프로그램 로드 및 ping test
(1) XDP 프로그램 작성
다음과 같은 xdp_drop.c 파일을 작성한다.
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
SEC("xdp_drop")
int xdp_drop_prog(struct xdp_md *ctx)
{
return XDP_DROP;
}
char _license[] SEC("license") = "GPL";매우 단순한 코드로 xdp_drop_prog가 호출되면 XDP_DROP을 리턴한다. XDP_DROP을 받은 패킷은 전부 drop되므로 해당 프로그램이 붙은 network interface는 패킷이 전부 drop될 것이다.
다음과 같이 clang으로 빌드하자.
$ clang -O2 -g -Wall -target bpf -c xdp_drop.c -o xdp_drop.o(2) 실험 대상 virtual network interface 작성
사용하고 있는 network interface에 attach 하는 것은 위험하므로, 위 XDP 프로그램을 load할 virtual network interface를 따로 생성해보자.
별도의 network namespace를 만들고 해당 namespace와 link된 veth 페어를 만들 것이다.
# net이라는 network namespace 생성
$ sudo ip netns add net
# default namespace에 veth1, net namespace에 veth2 생성
$ sudo ip link add veth1 type veth peer name veth2 netns net
# 생성 확인
$ sudo ip link show
...
369: veth1@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether fa:46:33:26:e9:0c brd ff:ff:ff:ff:ff:ff link-netns net
$ sudo ip netns exec net ip link show
...
3: veth2@if369: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 62:df:82:b0:ed:63 brd ff:ff:ff:ff:ff:ff link-netnsid 0veth1과 veth2에 ip를 할당하고 ping check까지 해보자.
# ip 할당
$ sudo ip addr add 192.168.1.1/24 dev veth1
$ sudo ip netns exec net ip addr add 192.168.1.2/24 dev veth2
# interface up
$ sudo ip link set veth1 up
$ sudo ip netns exec net ip link set veth2 up
# route check
$ ip route show
..
192.168.1.0/24 dev veth1 proto kernel scope link src 192.168.1.1
# ping check
$ ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.037 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.029 ms
64 bytes from 192.168.1.2: icmp_seq=3 ttl=64 time=0.036 msveth1을 통하여 veth2(192.168.1.1)로 ping이 성공하는 것을 확인할 수 있다.
(3) XDP 프로그램 로드 및 ping test
(1)에서 작성했던 XDP 프로그램을 load하여 veth1에 붙일 것이다. XDP 프로그램은 veth1으로 들어오는 패킷을 전부 drop하므로 load 후 ping이 실패해야 한다.
# xdp load
$ sudo xdp-loader load -m skb -s xdp_drop veth1 xdp_drop.o
$ sudo xdp-loader status
CURRENT XDP PROGRAM STATUS:
Interface Prio Program name Mode ID Tag Chain actions
--------------------------------------------------------------------------------------
...
veth1 xdp_dispatcher skb 66 94d5f00c20184d17
=> 50 xdp_drop_prog 73 57cd311f2e27366b XDP_PAS
$ sudo ip link show veth1
369: veth1@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdpgeneric qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether fa:46:33:26:e9:0c brd ff:ff:ff:ff:ff:ff link-netns net
prog/xdp id 66 name xdp_dispatcher tag 94d5f00c20184d17 jitedxdp_dispatcher는 xdp-loader가 생성한 것이고 xdp_drop_prog가 우리가 작성한 프로그램이다.
이제 다시 ping을 해보면 실패하는 것을 확인할 수 있다.
$ ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
From 192.168.1.1 icmp_seq=1 Destination Host Unreachable
From 192.168.1.1 icmp_seq=2 Destination Host Unreachable
From 192.168.1.1 icmp_seq=3 Destination Host Unreachable위 두 예제로부터 eBPF/XDP를 사용하면 (1) packet processing을 하는 프로그램을 작성 가능하고 (2) kernel space에서 실행 및 user space와 통신 가능하다는 것을 알 수 있다.
이제 다음 섹션에서 “The eXpress Data Path: Fast Programmable Packet Processing in the Operating System Kernel”(2018) 을 통해 XDP의 구조 및 eBPF에 대해 좀 더 자세히 알아보자.
3. XDP 구조와 eBPF
“The eXpress Data Path: Fast Programmable Packet Processing in the Operating System Kernel”(2018) 의 내용을 요약하였습니다.
3.1 Abstract & Introduction
XDP는 eXpress Data Path의 줄임말로 programable packet processing 기술이다. 그 전에도 packet processing 기술이 존재했으나 kernel을 우회하였다. Kernel과 user space간 context switching을 피하기 위해서였으나 OS가 제공하는 보안 및 안정성의 혜택을 받지 못했다.
XDP는 os kernel이 제공하는 안전한 실행 환경에서 수행되며 이는 eBPF 기반으로 구축되었기 때문이다. eBPF는 프로그램을 statically verify하여 안정성을 보장하고 kernel space에서 실행될 수 있도록 한다. 뿐만 아니라 kernel의 network stack이 패킷을 받기 전 먼저 패킷을 받을 수 있다.
장점을 간단하게 나열하면 다음과 같다.
- linux networking stack과 통합 가능.
- 서비스 중단 없이 동적으로 feature를 추가하거나 제거할 수 있다.
- 패킷을 처리하는 dedicating CPU 코어가 필요 없어 낮은 cpu usage로도 운영이 가능하다.
- eBPF를 사용해 kernel space에서 안전하게 실행될 수 있다.
3.2 The Design of XDP
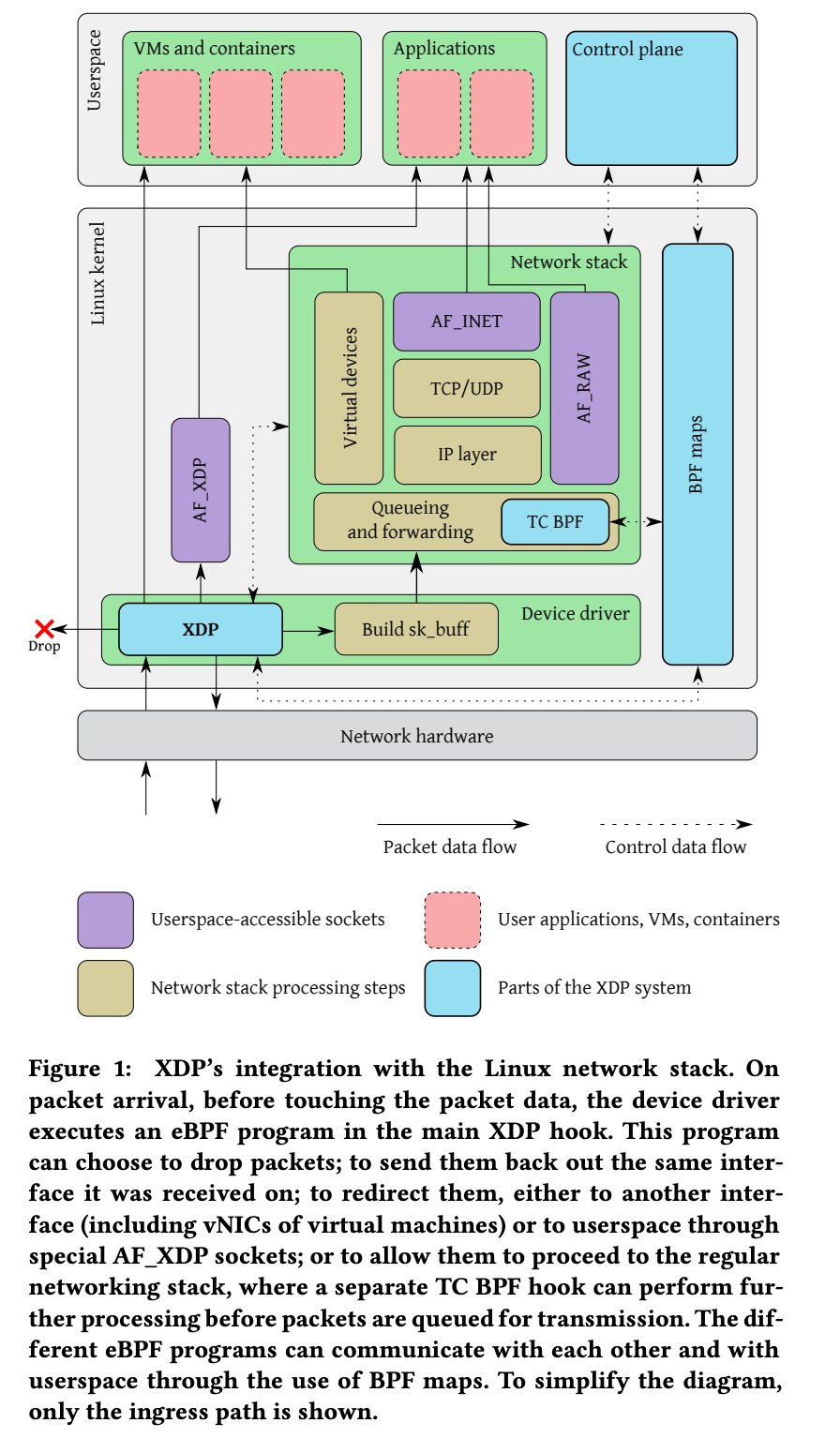
XDP 시스템에는 4개의 메이저 컴포넌트가 존재한다.
- XDP driver hook: XDP 프로그램의 main entry point이고 하드웨어에서 패킷을 받으면 실행
- eBPF virtual machine: XDP 프로그램의 바이트 코드를 실행한다. 추가적으로 JIT compile을 사용
- BPF maps: key/value store이다. 다른 시스템들과의 커뮤니케이션 채널로 사용
- eBPF verifier: 로드되기 전 프로그램을 statically verify하고 커널을 crash 및 corrupt 하지 않음을 보장
3.2.1 XDP Driver Hook
XDP 프로그램은 패킷이 도착할 때마다 network device driver 내의 hook에 의해 실행된다. 이때 XDP 프로그램은 device driver에서 실행되고 userspace로 컨텍스트 스위칭하지 않는다. 또한 Figure 1에서 볼 수 있듯이 network stack보다 먼저 패킷을 받는다.
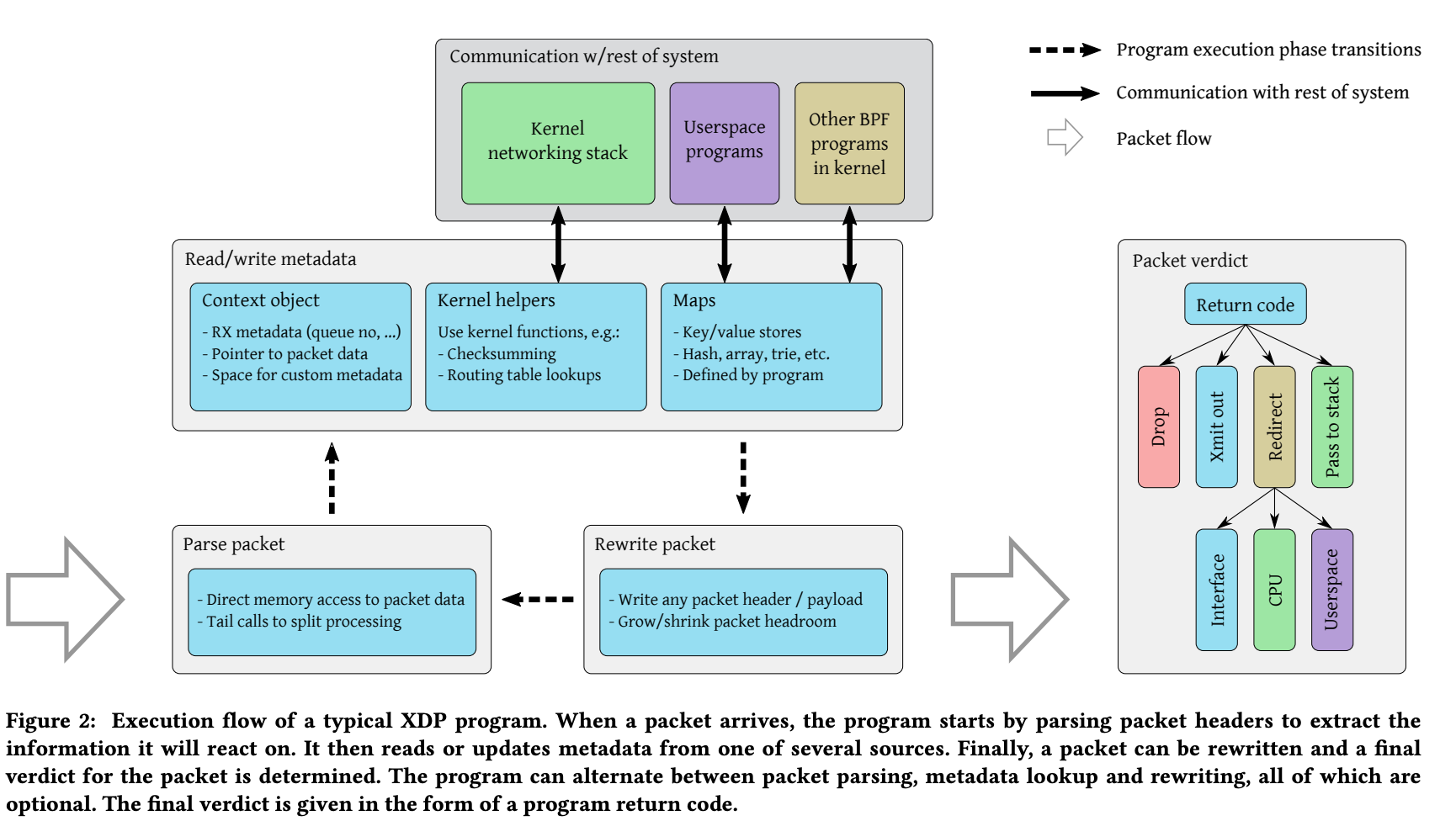
Figure2는 XDP 프로그램의 처리 단계를 보여준다.
(1) XDP 프로그램이 패킷을 parsing을 한다.
(2) context object를 통해 패킷과 관련된 메타데이터를 필드를 읽는다. 또한 kernel helper를 사용하거나 mapper를 통해 로직을 수행할 수 있다.
(3) 패킷 데이터를 쓸 수 있으며 패킷 버퍼를 늘리거나 줄일 수도 있다. 포워딩처럼 주소 필드를 다시 쓰는 것도 가능하다.
(4) 패킷 처리가 끝나면 최종적인 return code를 발행한다. redirect의 경우 다른 network interface 및 CPU, user space 소켓 주소로 보낼 수 있다(Figure 1에서 실선 부분).
3.2.2 eBPF Virtual Machine
XDP 프로그램은 eBPF virtual machine에서 실행된다.
eBPF는 BSD packet filter(BPF)의 발전된 형태이다. BPF의 virtual machine은 2개의 32bit register와 22개의 instruction을 사용했다. eBPF는 11개의 64bit register을 사용하였고, BPF call instruction을 native call instruction과 매핑하여 함수 호출의 오버헤드가 거의 없다.
eBPF instruction set은 general purpose computation을 가능하게 만들었지만 eBPF verifier가 kernel을 보호하기 위해 프로그램에 제한을 건다(뒤에서 후술(3.2.4)).
eBPF Maps(뒤에서 후술 (3.2.3))를 통하여 eBPF 프로그램이 커널의 다른 부분에서 발생한 이벤트에 반응하는 것도 가능하다. 예를 들어 CPU load를 모니터링하거나 특정 threshold를 넘어가면 XDP 프로그램이 패킷을 drop하는 것도 가능하다.
eBPF virtual machine은 dynamically loading과 프로그램 reloading을 지원한다.
3.2.3 BPF Maps
eBPF 프로그램은 커널 내 이벤트에 대한 응답으로 실행이 된다. XDP의 경우 패킷이 도착하면 실행이 되는 식이다. 이때 프로그램들은 같은 initial state에서 시작하지만 메모리가 persistent 하지 않다. 대신 eBPF maps를 사용한다.
BPF maps는 eBPF 프로그램을 로딩하기 위해 정의된 key/value store이고 eBPF code에 의해 접근할 수 있다. Map은 global 및 per cpu로 존재할 수 있고 여러 eBPF 프로그램 및 kernel과 user space 사이에서도 공유될 수 있다.
BPF Maps를 사용하면 한 eBPF 프로그램이 상태를 변경해 다른 프로그램의 행동을 변경할 수 있고 userspace 프로그램과 eBPF 프로그램간 커뮤니케이션 또한 수행할 수 있다(2. 예제로 알아보는 eBPF/XDP 참고).
3.2.4 eBPF Verifier
eBPF 코드는 kernel space에서 실행되어 kernel 메모리를 손상시킬 수 있다. 이를 막기 위해 kernel은 모든 eBPF 프로그램에 대해 하나의 entry point를 강제한다(bpf() 시스템 콜). Entry point로 eBPF 프로그램이 loading되면 kernel 내 eBPF verifier가 분석한다.
eBPF verifier는 해당 프로그램 byte code에 대해 static analysis를 수행하여 임의의 메모리에 접근하는 등 unsafe한 동작을 하지 않는다는 것을 보장한다. 이를 위해 반복문을 허용하지 않고 프로그램의 최대 크기를 제한하는 등의 방법을 사용한다.
verifier는 프로그램의 control flow로 DAG를 만들어 확인한다.
- DFS를 하여 DAG가 acyclic 하다는 것을 확인(loop가 없는지 등)
- DAG의 모든 가능한 path를 확인하여 안전한 메모리 접근 및 올바른 인자로 함수 호출이 일어나는지 확인한다.
verifier는 register의 상태를 트래킹한다. 데이터 타입 및 포인터 offset, 가능한 값의 범위 등을 포함한다. 이러한 정보를 사용하면 verifier가 load instruction에 대하여 memory의 범위를 예측할 수 있어 안전한 메모리 접근을 보장할 수 있다.
verifier가 안전하다고 증명하지 못한 eBPF 프로그램은 load시 거부된다.
3.3 Performance Evaluation
논문에서는 성능 측정을 위해 다음 3가지 항목을 측정하였다.
- packet drop performance
- CPU usage
- Packet forwarding performance
비교군으로 기존 packet processing solution 중 성능이 가장 좋은 DPDK를 선정하였고, 기존 리눅스 network stack도 선정하였다.
packet drop performance
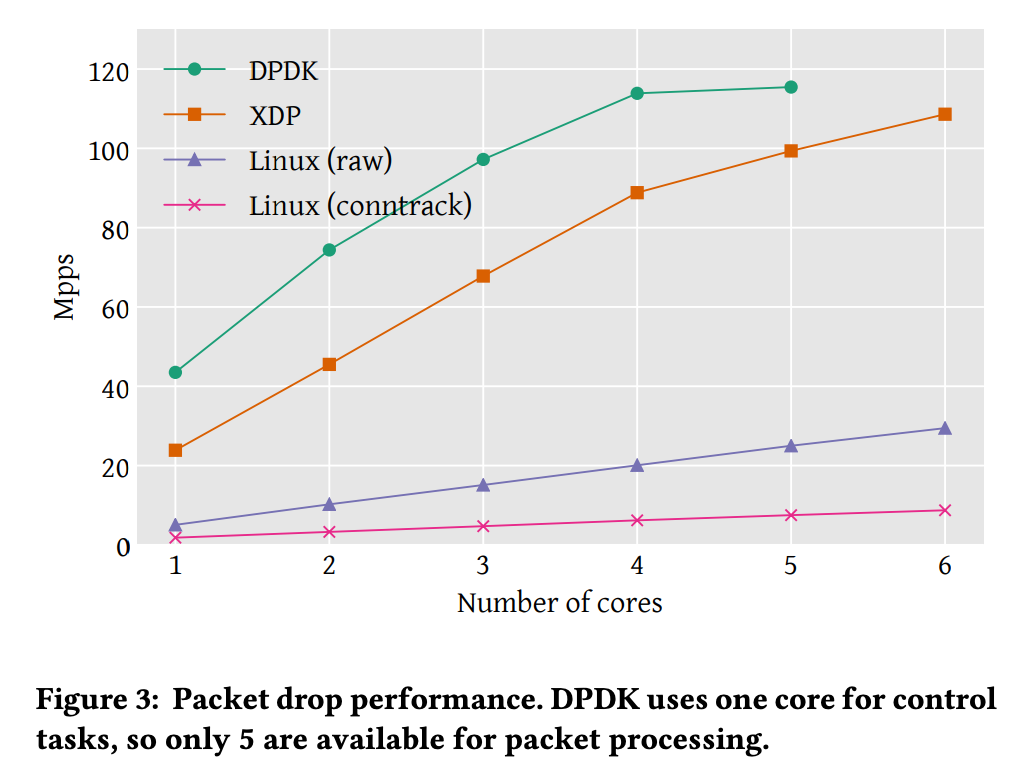
Mpps: Maximum packets per second
Linux(raw): linux iptable firewall 모듈 사용
Linux(conntrack): connection tracking 모듈 사용
Linux 모듈보다 성능이 높게 나왔지만 DPDK보다 성능이 낮게 나왔다. DPDK는 하나의 코어를 control task에 사용하여 5개의 코어까지만 성능을 측정할 수 있었다.
CPU usage
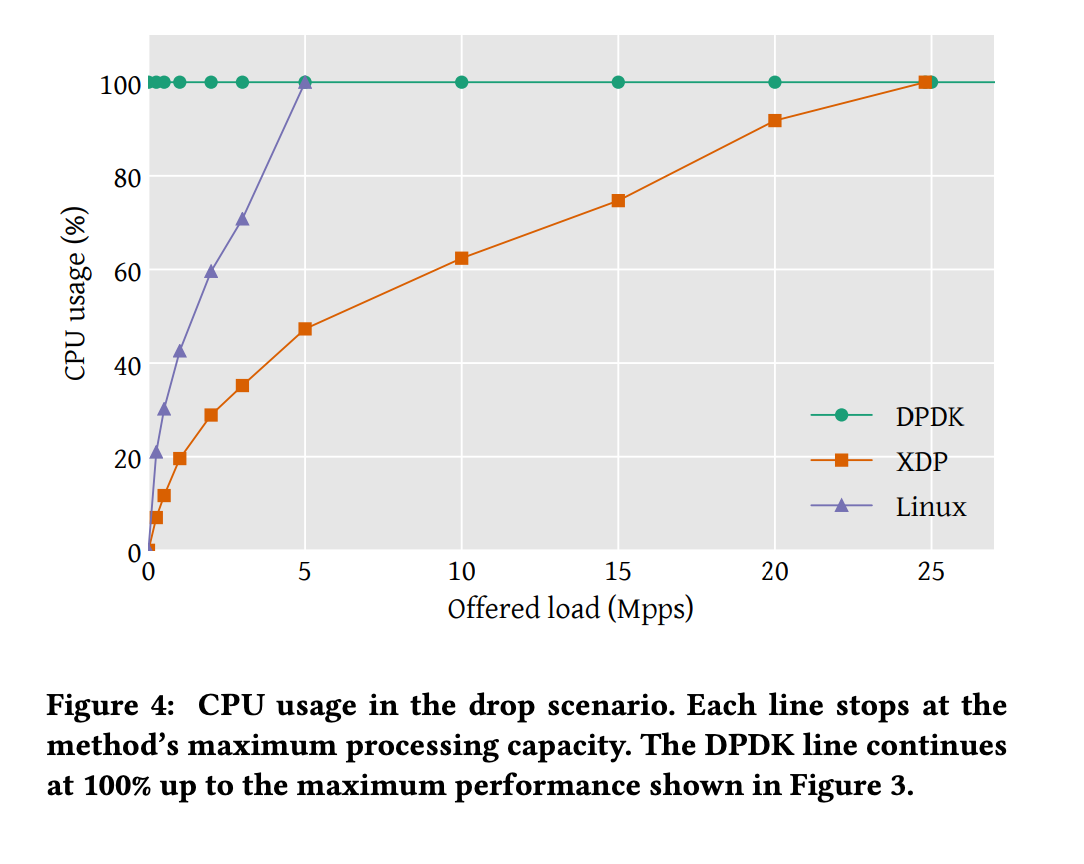
DPDK는 full core를 packet processing을 하도록 설계되어 있고, packet을 처리하기 위해 busy polling을 사용하여 100% 사용률이 나왔다.
왼쪽 아래에 non linear 구간은 interrupt processing의 고정 overhead 때문에 발생하였다.
Packet forwarding
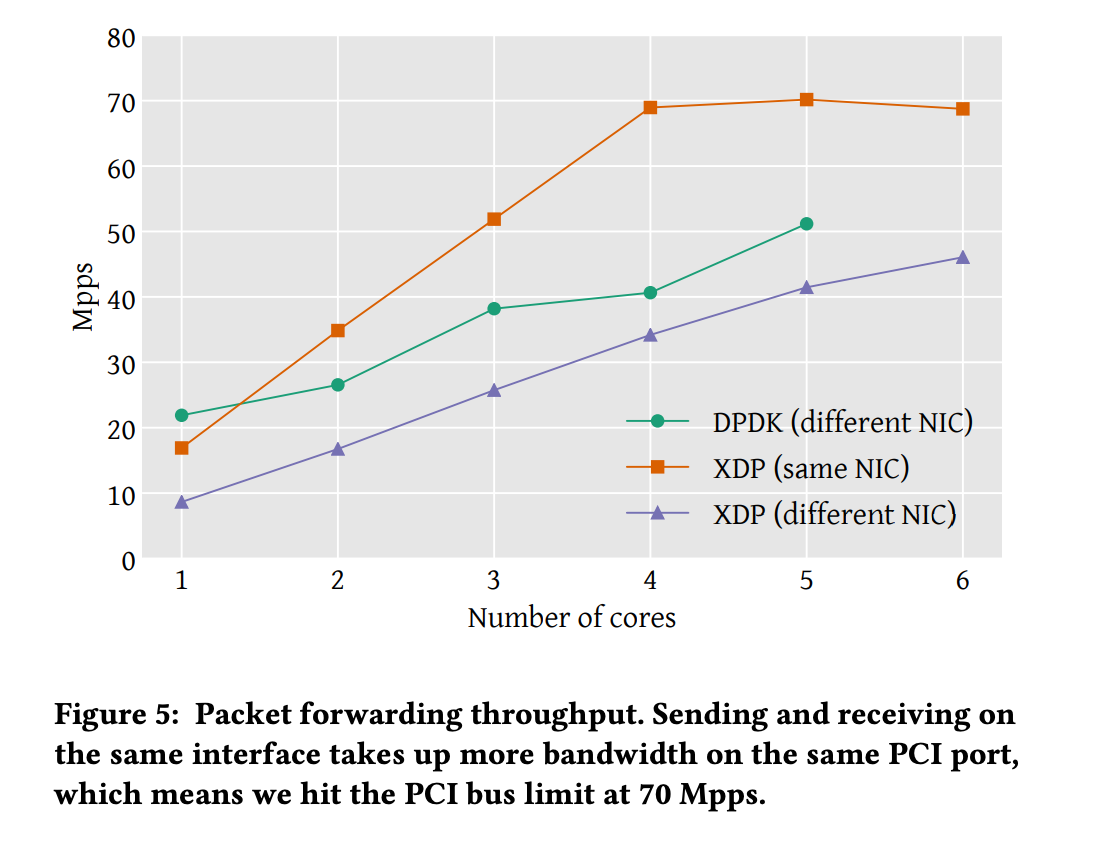
XDP가 같은 NIC로 포워딩이 가능하여 평가에 포함했다. 같은 NIC로 보낼 때 성능이 올라가는 이유는 메모리 처리에서 나온 차이다. 패킷 버퍼는 device driver에 의해 할당되고 이는 interface와 관련이 있다. 그래서 패킷이 다른 interface로 포워딩될 때 메모리 버퍼가 그 interface로 할당되야 한다.
XDP는 linux networking stack보다 빠르지만 DPDK에 미치지 못한다. 하지만 논문에서는 DPDK가 low level 단에서 많은 최적화를 했기 때문이라고 주장한다. 예를 들어 packet drop에서 싱글 코어에서 패킷당 처리 시간 차이는 18.7ns인데, 이 중 13ns가 특정 driver가 처리할 때 사용한 함수에서 발생함을 확인했다. 이러한 driver level의 함수 최적화 등을 수행하면 DPDK와 성능 차이가 나지 않을 것을 예상하였다.
4. eBPF/XDP를 사용한 예시
3에서 살펴본 논문이 나온지 6년이 지난 현재, eBPF/XDP는 많은 프로젝트 및 기업에서 사용되고 있다. 그 중 대표적인 프로젝트인 Cilium과 네이버의 사례를 간략하게 소개해보려 한다.
(1) Cilium
Cilium은 CNCF 프로젝트로 쿠버네티스 클러스터간 networking task에서 주로 사용한다다.
전통적인 Linux network는 IP 주소와 TCP/UDP port로 필터링을 하지만 쿠버네티스와 같은 컨테이너 환경에서는 문제가 있었다. 마이크로서비스 구조가 보편화되며 컨테이너 수명이 짧아지자 IP 주소가 너무 자주 바뀌게 되면서 로드밸런서나 ACL 규칙을 IP 주소와 포트 번호로 제어하기에 어려움이 발생한 것이다.
Cilium은 IP 주소로 식별하지 않고 service / pod / container id를 기반으로 하고 HTTP와 같은 어플리케이션 레이어에서도 필터링하는 방식을 제공한다. 즉, IP 주소 할당과 보안 정책을 분리할 수 있게 한다.
(2) 네이버 — eBPF/XDP 기반 NAT 시스템
네이버에서 운영하는 쿠버네티스 클러스터에서도 비슷한 문제를 직면하였다. 처음에는 ACL을 IP 주소로 관리하기 위해 Pod과 ACL 시스템의 정보를 동기화하였으나 이것이 부담이 되었다. 또한 일부 pod이라도 ACL 전파가 되지 않으면 장애로 이어질 수 있었다.
이를 해결하기 위해 NAT를 구현하였다. 처음에 Linux Netfilter(iptable)을 이용해 구현하였으나 성능 문제가 발생하여 eBPF를 사용했다고 한다. 자세한 구현 내용은 Deview를 참고 바란다.
5. 마무리
예제, 논문, 실사례를 간략히 살펴보며 eBPF/XDP에 대해 알아보았다.
eBPF는 (1) 비교적 높은 성능으로 (2) 안전하게 (3) 서비스 중단 없이 networking 작업 등을 가능하게 하는 장점이 많은 기술이다. 특히 Cilium과 네이버의 사례에서 보았듯이 컨테이너 환경이 보편화되며 더욱 빛을 발하고 있다.
예제에서 보았듯이 어플리케이션에서 eBPF 프로그램을 load하고 소통할 수 있으니 현업에서도 유용하게 쓸 수 있기를 바란다.
Reference
The eXpress Data Path: Fast Programmable Packet Processing in
the Operating System Kernel (2018)