
[구글 시리즈] #3. Chubby (feat ZooKeeper)
![[구글 시리즈] #3. Chubby (feat ZooKeeper)](https://images.unsplash.com/photo-1731351621470-8aebda14d242?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8YWxsfDJ8fHx8fHx8fDE3MzE4NDEzNDV8&ixlib=rb-4.0.3&q=80&w=2000)
현재 검색 시장뿐만 아니라 다양한 분야를 장악한 구글은 불과 1998년에 설립되었습니다. 구글은 매우 빠른 속도로 성장했고, 이를 위한 인프라 시스템들을 구축했습니다. 구글의 인프라 시스템은 다른 회사 및 개발자에게 많은 영향을 끼쳤습니다. 구글 시리즈는 이러한 논문들 중 일부를 뽑아 소개를 하고자 합니다.
이번 글에서는 구글의 Chubby만 다루는 것이 아니라, Zookeeper도 같이 다룹니다.
- The Google File System (2003)
- BigTable: A Distributed Storage System for Structured Data (2006)
- The Chubby lock service for loosely-coupled distributed systems (2006)
- Dapper, a Large-Scale Distributed Systems Tracing Infrastructure (2010) (예정)
- Large-scale cluster management at {Google} with {Borg} (2015) (예정)
1. 개요
합의 알고리즘에서 가장 어려운 문제 중 하나는 리더 선발입니다. 사람의 개입 없이 자동으로 리더 선발을 하려면 스플릿 브레인 문제가 발생하지 않게 모든 노드가 누가 리더인지 동의해야 합니다. 그래서 리더 선발을 위해서는 합의가 필요합니다. 즉, 합의 알고리즘을 구현하기 위해 합의가 필요한 상황인 것입니다.
paxos나 raft 같은 합의 알고리즘에서는 에포크 번호를 정의하고 각 에포크 내에서 리더가 유일하다고 보장합니다. 두 리더 사이에 충돌이 있으면 에포크 번호가 높은 리더가 이기고, 리더 선출 및 리더 제안 투표에는 정족수(보통 과반)을 요구하여 리더가 유일하도록 합니다.
이런 합의 알고리즘들은 리더 문제를 해결하기 위해 과반의 정족수를 요구하기에 노드 n대의 장애를 견디려면 2n+1대가 필요합니다. 또한 투표하는 과정이 일종의 동기식 복제이기에 성능도 좋지 않습니다. 그 외에도 투표에 참여하는 노드의 수가 고정되어 있어 추가로 노드를 추가하거나 제거할 수 없는 문제, 네트워크 문제에 취약한 문제 등 분산 시스템을 실제로 서비스에서 운영할 때 생각해야할 문제들이 너무 많습니다.
Zookeeper, etcd, consul 등으로 대표되는 코디네이션 설정 서비스들은 분산 시스템을 운영할 때 발생하는 문제들을 일부 해결해줍니다.
Zookeeper와 같은 코디네이션 서비스들은 자신이 저장하고 있는 데이터를 전체 순서 브로드캐스트(total order broadcast)하여 자신의 모든 노드에 복제합니다. 전체 순서 브로드캐스트는 분산 시스템에서 모든 연산의 순서를 정하는 것을 말합니다. 그래서 여러 쓰기 요청을 같은 순서로 적용하여 모든 복제본들이 일관성을 유지할 수 있습니다.
Zookeeper는 전체 순서 브로드캐스트 외에도 분산 시스템 구축시 필요한 기능들을 제공합니다.
- 선형적 원자적 연산: compare-and-set 연산으로 잠금을 지원해 여러 노드가 동시에 수행할 때 하나만 성공함을 보장
- 연산의 전체 순서화: 펜싱 토큰(잠금을 획득할 때마다 단조 증가하는 어떤 숫자) 제공. Zookeeper는 모든 연산에 전체 순서를 정하고 각 연산에 단조 증가하는 트랜잭션 ID(zxid)와 버전 번호(cversion)을 할당해 제공한다.
- 장애 감지: 클라이언트와 zookeeper가 세션을 유지하고 하트비트를 교환해 세션이 죽었는지 감지. 세션이 죽으면 세션에서 획득된 잠금은 해제되도록 설정할 수 있다(ephemeral node).
- 변경 알림: 클라이언트는 다른 클라이언트가 생성한 잠금 및 값을 읽을 수 있고 변경이 있는지 알림을 받을 수 있다. 이를 통해 클라이언트는 다른 클라이언트가 언제 클러스터에 합류했는지, 장애가 났는지(ephemeral node가 사라졌는지) 등을 알 수 있다. 또한 이런 알림은 구독할 수 있어 주기적으로 폴링할 필요가 없다.
이런 기능들을 조합하면 분산 코디네이션에 유용하게 사용할 수 있습니다.
- 리더 선발: 합의 시스템이 누가 리더인지 저장하고 다른 서비스들이 리더가 누구인지 찾을 때 사용
- 노드에 자원 할당: 노드가 합류/제거되어 부하를 분배하기 위해 자원을 다시 할당하는 케이스 등
- 서비스 찾기(service discovery): 주로 클라우드에서 서비스가 시작할 때 자신의 엔드포인트를 등록. 다른 서비스들은 Zookeeper를 참고해 서비스를 찾음.
- 멤버십 서비스: 어떤 노드가 활성화된 노드인지 결정. Zookeeper의 장애 감지를 분산 시스템에서 합의할 때 사용하는 것(실제로 살아 있지만 죽은 것으로 잘못 선언될 가능성이 존재).
또한 수천대의 노드를 가진 분산시스템에서 과반수 투표를 진행하는 것보다 3대나 5대의 노드를 가진 Zookeeper 내에서 투표를 진행하면 성능 이점을 챙길 수 있습니다. 코디네이션 시스템은 이렇게 분산 시스템의 일부 작업을 위탁받아 대신 수행하는 역할을 합니다.
대표적인 코디네이션 서비스의 Zookeeper는 이번에 다룰 Chubby의 영향을 받았습니다.
Chubby는 분산 시스템을 위한 신뢰성 있는 분산 잠금 서비스를 표방하고 있습니다. Chubby는 분산 파일 시스템과 유사한 인터페이스를 제공하는 한편 고성능보다는 가용성 및 안정성에 초점을 둡니다. 이 논문이 발표될 당시(2006년) 기준 구글에서 수년간 서비스가 되었으며 몇 인스턴스는 수만 개의 클라이언트를 동시에 처리하기도 하였습니다.
이번 글에서는 Chubby와 Zookeeper의 논문을 참고하여 각각의 구현에 대해 알아보겠습니다.
2. Chubby
Chubby는 2006년 구글이 발표한 잠금 서비스입니다.
Chubby는 느슨하게 결합된 분산 시스템(loosely-coupled distributed system)을 위해 coarse-grained 잠금 서비스를 제공하는 것을 목적으로 합니다. 쉽게 말하면 공유하는 자원에 대한 접근 관리를 쉽게 할 수 있도록 분산 시스템에게 잠금 서비스를 제공합니다.
Chubby는 GFS 및 Bigtable 등의 서비스들이 리더를 선발하거나 서비스 찾기(service discovery)의 용도 등으로 사용하고 있습니다.
2.1 Lock의 방식: coarse-grained and advisory
Chubby는 coarse-grained advisory locking을 제공합니다. 여기서 우리는 (1) coarse-grained와 (2) advisory가 각각 무엇인지 알아볼 필요가 있습니다.
coarse-grained lock vs fine grained lock
coarse-grained lock은 수 시간 혹은 몇일 이상 유지되는 잠금을 말합니다. Chubby가 coarse-grained lock 서비스를 제공한다는 것은 성능보다 가용성과 신뢰성을 중시한다는 것을 의미합니다.
advisory lock vs mandatory lock
advisory lock은 잠금을 획득할 때만 다른 잠금을 획득하는 프로세스들과 경합하는 것을 의미합니다. 잠금과 대상 파일을 완전히 분리한 것으로 잠금을 획득할 때 대상 파일에 접근할 필요가 없습니다. 그래서 만약 프로세스가 잠금의 존재 여부를 모른다면 잠금을 무시하고 파일을 접근하는 일도 발생할 수 있습니다. 논문에서 구체적인 구현 방법은 나오지 않았지만, 리더가 메모리에서 여러 노드들이 가진 lock의 상태를 관리하는 구현의 한 예가 될 수 있습니다. 한편 linux에서도 flock 커맨드로 advisory lock을 지원합니다.
이와 반대되는 개념은 mandatory lock입니다. 잠금 획득시 커널에만 의존하는 것을 말합니다(다른 프로세스들과 상호작용할 필요가 없습니다). 예를 들어 커널의 파일시스템으로 mandatory lock을 구현하면 파일에 group id bit 등을 이용해 다른 프로세스의 접근 자체를 불가하게 만들 수 있습니다.
chubby 논문에서 mandatory lock을 사용하지 않은 이유 중 하나로 디버깅 혹은 관리하기 어려운 것을 꼽았습니다. 운영 중 잠겨진 파일에 접근하기 위해 해당 잠금을 가진 어플리케이션을 강제로 종료시키는 일들이 발생하는 것은 까다로울 것입니다. 특히 많은 노드가 존재하는 분산 어플리케이션임을 생각하면 Chubby가 advisory lock을 선택한 것은 어쩌면 당연한 일입니다.
2.2 API와 이벤트
클라이언트는 유닉스 파일시스템과 유사한 API를 사용할 수 있습니다. 다만 symlink/hardlink 등 일부 유닉스 파일시스템의 기능을 지원하지 않습니다.
- Open과 Close: 파일 혹은 디렉토리를 다루는 handle을 열거나 닫을 수 있습니다. 이 Handle을 사용하는 다른 API를 통해 파일을 읽거나 쓸 수 있습니다.
- Advisory reader/writer lock을 획득하거나 제거할 수 있습니다.
- ACL을 설정할 수 있습니다.
Chubby는 클라이언트가 handle을 생성할 때 이벤트 구독을 지원합니다. 클라이언트는 이벤트를 구독하여 파일 내용이 변경되었거나, 자식 노드가 추가되었거나, Chubby 마스터가 실패했거나(이벤트가 소실될 수 있어 데이터를 다시 스캔해야함), 잠금 획득/충돌 등을 알 수 있습니다.
2.3 Chubby Cell and Paxos
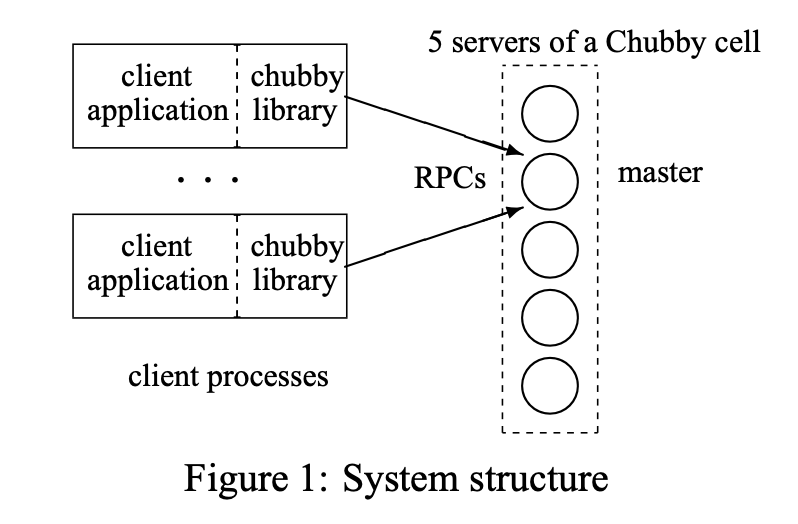
Chubby는 두 개의 컴포넌트로 이루어져 있습니다. (1) 서버와 (2) 클라이언트 어플리케이션이 사용하는 라이브러리입니다. 서버와 라이브러리는 RPC를 통해 통신합니다.
Chubby에서 관리하는 서버들의 작은 집합을 Chubby cell이라고 합니다. Chubby cell은 보통 5개의 서버로 이루어집니다. Chubby cell에는 하나의 마스터가 존재하며 나머지를 레플리카라고 부릅니다.
Chubby는 분산 합의 알고리즘으로 paxos를 사용합니다. Paxos는 비동기 시스템에서 사용할 수 있는 알고리즘입니다. Paxos의 가정을 살펴보면 Chubby가 어떤 네트워크 환경을 가정하는지 짐작할 수 있습니다. Paxos에 참여하는 컴포넌트들은 독립적이고 처리 속도도 각각 다르며 실패할 수 있습니다. 컴포넌트간 주고 받은 메시지는 전송 후 받을 때까지 오래 걸릴 수 있으며 메시지를 받는 순서 또한 보장되지 않습니다. 다만 컴포넌트가 거짓말을 한다던가(이를 비잔틴 결함이라고 합니다) 전송된 메시지가 위조되는 등의 상황을 가정하지 않습니다.
Cell 내 레플리카들은 리더(마스터)를 선출합니다. 레플리카의 과반수가 리더 후보에 동의해야 선출 성공합니다. 또 여러 리더가 동시에 존재하는 것을 방지하기 위해 “master lease”를 둡니다. master lease 기간 동안에는 선거를 진행할 수 없습니다. 기존 마스터는 마스터 활동을 연장하기 위해 master lease를 주기적으로 갱신해야 합니다. master lease가 없다면, 기존 마스터가 잠시 실패하고 재시작하는 동안 다른 마스터가 선발되어 두 마스터가 동시에 활동할 수도 있습니다. master lease를 도입하면, 기존 마스터가 재시작해도 자신의 maser lease가 만료된 것을 인지하여 마스터로 활동하지 않습니다.
Chubby 클라이언트들은 레플리카들과 통신하여 마스터의 위치를 알아내고 그 이후 마스터로만 요청을 보냅니다. 쓰기 요청들은 분산 합의 알고리즘을 통해 다시 전파되고 Cell 내 절반 이상의 레플리카가 요청을 받으면 쓰기에 성공합니다. 읽기 요청은 마스터만 살아있다면 성공합니다.
2.4 Sequencer
분산 시스템에서 발생할 수 있는 잠금 문제 하나를 들어봅시다.
(1) A가 잠금 L을 들고 있는 상태에서 쓰기 요청 보냅니다. 그런데 그 직후 A가 실패하였습니다(shutdown).
(2) A가 실패했으므로 잠금 L은 풀렸고, B는 잠금 L을 획득하고 쓰기 요청을 보냅니다.
(3) B의 쓰기 요청이 먼저 수행되고 A가 보낸 쓰기 요청이 수행됩니다.
이 경우 A가 쓰기 요청을 보낼 때의 상황과 쓰기 요청이 도착했을 때의 상황이 달라져 잘못된 변경이 이루어질 수 있습니다.
잠금을 들고 있는 프로세스가 죽었을 때 잠금에 접근하지 못하게 하는 방법 등으로 해결할 수도 있지만 Chubby는 sequencer를 도입하여 이를 풀어냈습니다.
Chubby는 잠금을 사용하는 요청에 대해 sequencer라는 바이트 문자열을 부여합니다. sequencer는 잠금의 이름, 모드(exlusive 혹은 share), 잠금 생성 숫자 등을 가지고 있습니다. 클라이언트는 sequencer를 요청에 같이 첨부하여 서버에 보내고 서버는 sequencer가 유효한지 검증하여 요청을 적용할지 결정합니다.
Sequencer를 도입하면 요청의 수행이 느려질 수 밖에 없습니다. 그래서 Chubby는 비교적 성능이 낫지만 불완전한 메커니즘도 같이 지원합니다. 그 메커니즘은 잠금을 소유한 소유자가 실패하거나 접근이 불가하면 “lock-delay”라는 기간 동안 다른 클라이언트가 잠금을 소유할 수 없게 합니다. 다만 처음 제시한 문제에서 A가 보낸 쓰기 요청이 “lock-delay” 이후에 도착하면 이 방법도 문제를 해결하지 못하므로 완전하지 못합니다. 하지만 대다수의 케이스는 이 방법으로도 충분히 막을 수 있습니다.
2.5 Session
클라이언트와 Chubby cell의 서버는 세션을 유지합니다. 클라이언트는 주기적으로 keep alive 요청을 마스터에게 보내 세션을 유지합니다. 세션을 유지함으로써 클라이언트는 파일 등을 캐시하여 사용할 수 있습니다. keep alive 요청은 캐시들을 무효화하는 요청 등을 포함하여 캐시를 관리하는 역할도 수행합니다.
클라이언트는 Chubby cell의 마스터와 새로운 세션을 시작합니다. 세션은 둘 중 하나가 멈추거나 idle 상태가 되면 멈춥니다. (idle: open handle이 없고 1분 동안 아무 call이 없는 상태)
마스터는 세션마다 lease를 두어 관리합니다. 마스터가 lease의 타임 아웃을 연장하는 경우는 3가지입니다.
- 세션의 생성
- 마스터가 실패한 후 재시작했을 때
- 클라이언트로부터 KeepAlive RPC를 받아 응답할 때
KeepAlive 요청을 받으면 마스터는 클라이언트의 이전 lease가 만료될 때까지 KeepAlive RPC 요청에 응답하지 않고 멈춥니다(block). 이전 lease 만료 이후 마스터는 RPC에 응답하며 클라이언트에게 새 lease의 타임 아웃을 알려줍니다. 기본 값은 12초로 설정되어 있지만, 마스터의 과부화 정도에 따라 KeepAlive 횟수를 줄이기 위해 늘릴 수도 있습니다.
클라이언트는 로컬 lease 타임 아웃을 따로 관리합니다. 마스터의 lease 타임 아웃보다 보수적인 값으로 설정하는데, KeepAlive 응답이 전송 중 소비하는 시간과 마스터의 시계(clock)과 차이가 나는 정도를 고려합니다. 클라이언트의 로컬 lease가 만료되면 클라이언트 입장에서 마스터가 세션을 종료한 것인지 알 수 없습니다. 그래서 클라이언트는 캐시를 비우고 세션을 비활성화하는데 이러한 세션 상태를 jeopardy라고 부릅니다.
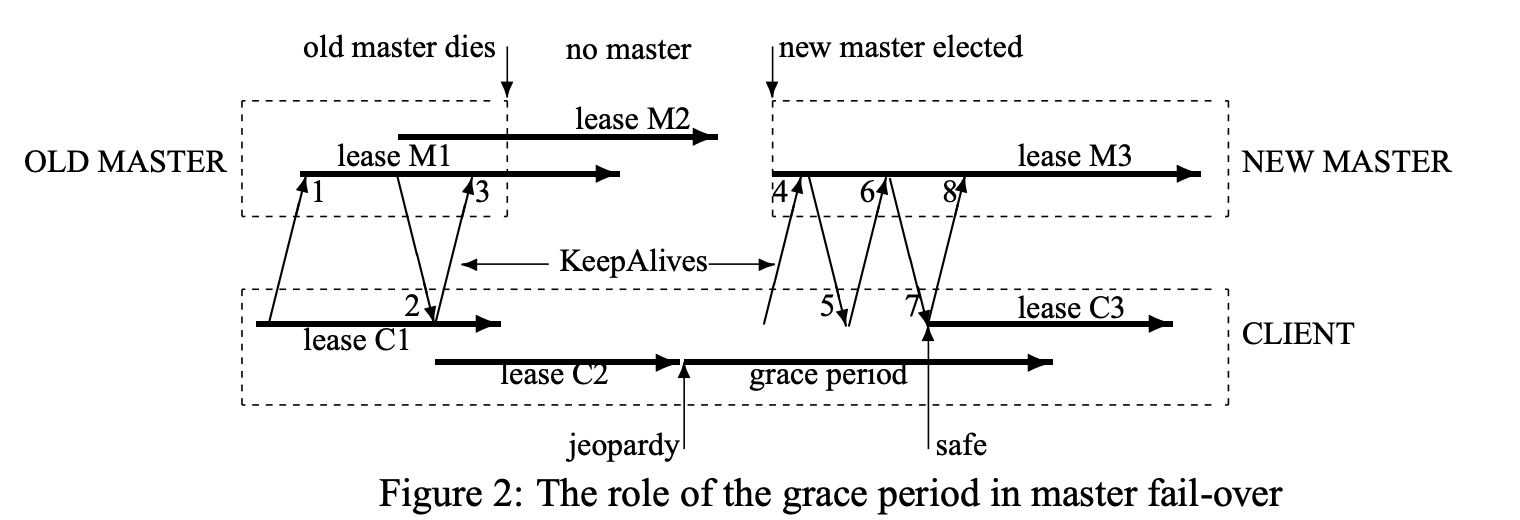
세션이 jeopardy 상태로 변경되면, 클라이언트는 45초 간 grace period를 기다립니다. 만약 이 기간동안 마스터와 keep alive 메시지 교환에 성공한다면 클라이언트는 해당 세션을 유지합니다. 교환이 실패하면 세션을 만료합니다.
클라이언트 라이브러리는 grace period가 시작되면 어플리케이션에 jeopardy 이벤트를 보내줍니다. 이후 세션이 복구 되면 safe 이벤트를, 그렇지 못하면 expired 이벤트를 전송하여 어플리케이션이 세션의 상태에 따라 대처할 수 있게 도와줍니다.
3. ZooKeeper
Zookeeper는 Chubby의 디자인에 많은 영향을 받았습니다.
Chubby가 GFS에게 하는 유사한 역할을 HDFS에게 하고 있습니다(마찬가지로 HDFS도 GFS의 영향을 받았습니다)
앞 개요에서 살펴보았듯이 Zookeeper와 Chubby는 단순한 분산 잠금 서비스를 넘어 분산 시스템에 필요한 많은 기능들을 제공하고 있습니다.
3.1 Znode
zookeeper는 클라이언트에게 추상화된 znode의 세트를 제공합니다.
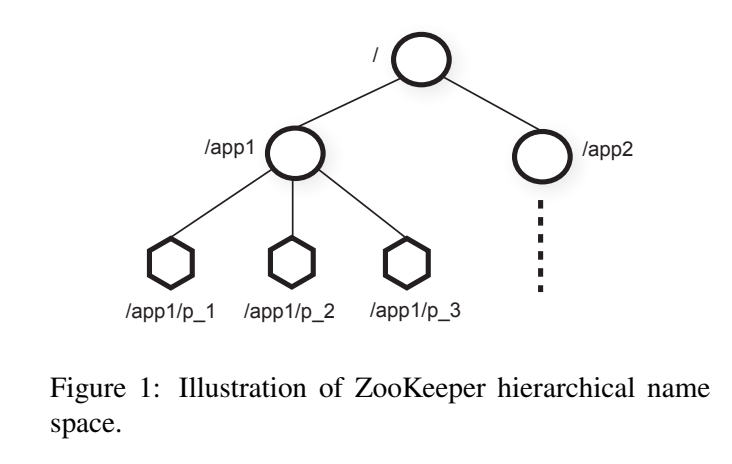
Znode는 위 그림과 같이 계층 구조안에 속해있으며 클라이언트는 ZooKeeper API를 통해 이를 조작할 수 있습니다.
Znode는 인메모리 데이터 노드이며, UNIX와 비슷한 path notation을 가지고 있습니다.
클라이언트가 만들 수 있는 znode는 두 가지입니다.
- Regular: 클라이언트가 명시적으로 생성하고 삭제할 수 있는 znode 입니다.
- Ephemeral: 클라이언트가 명시적으로 생성하고 삭제할 수도 있고, 생성한 세션이 닫혔을 때 시스템이 자동으로 삭제하는 znode입니다.
3.2 Wait free
Zookeeper의 API는 znode를 다룹니다. 클라이언트는 단순한 API 들을 통해 znode를 파일 시스템처럼 사용할 수 있습니다.
Zookeeper의 API가 Chubby와 다른 점 중 하나는 wait free라는 것입니다. Wait free는 클라이언트의 수와 시스템의 상태와 상관 없이 모든 operation이 일정 시간 내에 응답을 받을 수 있음을 보장합니다. 좀 더 구체적으로 말하면, Chubby와 다르게 API에 lock과 같은 blocking primitive를 사용하지 않았습니다.
lock을 사용하는 API를 제공하지 않지만 API를 조합하여 blockign primitive를 구현 가능합니다. 논문에서 Simple Lock, Simple locks without Herd Effect, Read/Write Lock 등의 구현 예제를 설명하고 있으나 이 글에서는 다루지 않겠습니다.
API가 wait free이면 가지는 장점들은 다음과 같습니다.
- 성능: 클라이언트들의 수와 관계 없이 성능이 보장되므로 읽기 위주의 워크로드에서 높은 처리량과 낮은 레이턴시를 달성할 수 있습니다.
- Fault tolerance: 일부 느리거나 실패한 클라이언트들이 전체 시스템의 성능에 영향을 미치지 않습니다.
- 단순한 서비스 구현: 서버가 blocking operation을 생각하지 않아도 되니 구현이 단순해집니다.
3.3 선형성(Linerizability)
최신 데이터를 꼭 읽을 필요가 없다면 클라이언트는 읽기 요청을 마스터에게 보낼 필요가 없습니다. 오히려 throughput을 위해서라면 적극적으로 여러 레플리카에게 읽기 요청을 분산하는 것이 도움이 될 것입니다.
레플리카들에게 읽기 요청을 할 수 있으려면 클러스터에서 선형성(Linerizability)를 보장해야 합니다. 선형성이란 operation이 시작한 시간과 끝나는 시간 사이 정확히 한 번만 반영이 되어야야 하는 특성을 말합니다. 예를 들어 클라이언트가 두 개의 읽기 요청을 보냈는데, 첫번째 읽기 요청의 반환 값이 두 번째 읽기 요청의 반환 값보다 최신 값이면 안됩니다. 클라이언트 입장에서는 어떤 operation이 어떤 시점에는 반영이 되었다가 그 뒤에는 취소되었고 그 이후에 다시 반영된 것으로 보일 수 있기 때문입니다.
ZooKeeper는 선형성을 보장합니다. 더 나아가 ZooKeeper의 논문에서는 선형성을 확장한 비동기적 선형성(A-linearizability)를 만족한다고 소개합니다. 선형성의 원래 정의에서 클라이언트는 한번에 하나의 요청만 보낼 수 있다고 가정합니다(하나의 클라이언트는 하나의 쓰레드를 가짐). Zookeeper에서는 클라이언트가 여러 개의 operation을 보낼 수 있고 클라이언트가 보낸 순서대로 요청을 처리함을 보장합니다. 이를 비동기적 선형성이라고 합니다.
Zookeeper는 선형성을 구현하기 위해 다음 두 가지를 보장하였습니다.
- 선형적 쓰기(Linearizable Write)
- FIFO 클라이언트 순서(FIFO client order)
선형적 쓰기는 ZooKeeper의 상태를 업데이트하는 모든 요청은 직렬화(serializable)되고 우선순위가 있음을 말합니다. 클라이언트는 쓰기 요청을 리더로만 보내고, 리더가 쓰기 요청 간 순서를 정하면 이를 만족할 수 있습니다.
FIFO 클라이언트 순서는 어떤 클라이언트가 보낸 요청은 반드시 보낸 순서대로 처리가 되야함을 의미합니다. 클라이언트가 요청에 번호를 담아 보내면 이를 만족할 수 있습니다. 예를 들어서 요청 2개를 보낼 때 번호를 명시한 1번 요청과 2번 요청을 보내면, 서버는 2번 요청을 먼저 받더라도 1번 요청을 먼저 처리하고 2번 요청을 처리합니다.
이 두 가지가 어떻게 선형성을 만족시킬 수 있을까요?
레플리카는 클라이언트의 읽기 응답을 보낼 때 이전에 클라이언트가 받은 응답보다 오래된 상태의 값을 돌려주면 안됩니다. 그래서 ZooKeeper는 zxid라는 번호를 만들어 관리합니다. zxid는 레플리카가 가장 마지막으로 본 트랜잭션의 번호입니다. 클라이언트가 읽기 요청을 보낼 때 이전 읽기 요청으로 돌려받은 zxid를 첨부하여 보냅니다. 레플리카가 자신이 갖고 있는 zxid가 읽기 요청에 첨부된 zxid보다 작다면, 업데이트가 될 때까지 해당 요청에 응답하지 않습니다. 이를 통해 클라이언트가 이전 요청보다 오래된 값을 돌려주는 일을 방지할 수 있습니다.
3.4 Zab - Paxos의 문제를 극복
Zab은 ZooKeeper가 사용하는 합의 프로토콜입니다. 왜 Chubby와 다르게 Paxos를 사용하지 않고 Zab을 사용할까요?
Paxos는 state machine replication을 위한 알고리즘이지만, Zab은 primary-backup 시스템을 위한 알고리즘입니다.
state machine replication 시스템은 각 레플리케이션이 요청을 받아 처리하고 자신의 상태를 변경한 뒤 응답합니다. 만약 같은 순서대로 요청들을 받았다면 두 state machine은 같은 상태를 가지고 같은 응답을 만듭니다. State machine replication 시스템의 합의 알고리즘은 기존 리더가 실패 후 새로운 리더가 선발되면, 새로운 리더는 커밋되지 않은 요청들의 순서를 변경할 수도 있습니다.
primary backup 시스템은 레플리카들은 증분 상태 업데이트에 대한 순서를 정합니다. 레플리카들은 클라이언트 요청이 아니라 상태 업데이트가 primary와 같은 순서대로 적용되야 합니다. 기존 primary가 실패더라도 새로운 primary는 커밋되지 않은 상태 업데이트들을 재배열할 수 없습니다.
Paxos를 ZooKeeper에 적용했을 때 문제는 primary가 병렬로 상태를 업데이트 중 실패하면 새로운 primary가 커밋되지 않은 상태를 잘못된 순서로 적용할 수 있습니다.
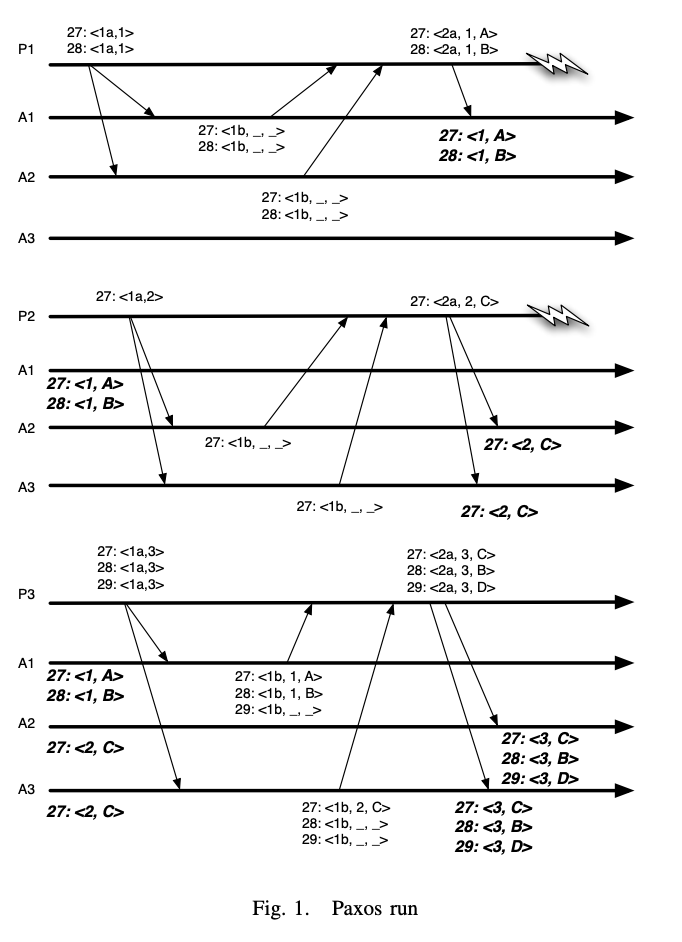
위 그림의 notation 순서는 slot number: ballot number, state transition 입니다
Phase 1(첫번째 그림): proposer P1은 과반인 A1과 A2에게 27번과 28번에 대해 각각 A와 B를 제시하려 합니다. Accepor A1은 이 두 요청을 잘 처리하였으나(27: <1, A>, 28: <1, B>) A2에는 제시하지 못하고 실패합니다.
Phase2(두번째 그림): proposer P2는 phase 1을 A2와 A3에 재실행하려 합니다. 하지만 phase1에서 A2와 A3는 phase 1에서 받은 것이 없습니다(그림에서 <1b, _, _> 응답). 이후 A2와 A3에게 27번 C를 제시 성공 후 실패합니다.
Phase3(세번째 그림)에서 P3는 phase1, 2를 A1과 A3에 재실행하려 합니다. P3는 A1과 A3에게 받은 값을 조합하여 27번의 값 C와 28번의 값 B를 같이 제시합니다.
위 케이스에서 Casual order가 위반됩니다. 의도했던 동작 순서는 값 A,B 변경이 먼저 수행된 이후 값 C 변경이 수행되어야 합니다. 하지만 A2, A3는 값 C 변경이 먼저 수행되고 값 B 변경이 이후에 일어났습니다.
Paxos에서 이 문제를 해결하려면 상태 업데이트에 순차적으로 동의해야합니다. 프라이머리는 이전의 모든 상태 업데이트를 커밋한 이후에만 상태 업데이트를 제안해야 이를 막을 수 있습니다. 하지만 이렇게 Paxos를 구현하면 성능이 저하가 됩니다.
Paxos와 달리 Zab의 리더는 복구시 이전 커밋을 무조건 과반수의 팔로워들에게 전달해야 합니다. 만약 Paxos에 이런 특성이 있었다면 phase2 시작할 때 이미 과반수의 팔로워들이 <27: A, 28: B>를 가졌을 것이기에 위의 문제를 막을 수 있었을 것입니다.
Zab의 레플리카들은 여러 상태 업데이트 순서들을 동시에 동의할 수 있어 성능 문제를 겪지 않았다고 합니다. paxos와 비교할 때 복구시 한 번의 단계를 더 추가하고 zxid에 기반하여 인스턴스들의 번호를 사용함으로써 이를 달성할 수 있었다고 합니다.
4. Reference
- The Chubby lock service for loosely-coupled distributed systems(2006)
- 데이터 중심 어플리케이션 설계
- https://medium.com/princeton-systems-course/implementing-chubby-a-distributed-lock-service-8cf3c026c672
- https://medium.com/@hrjeet0987/list-the-points-of-difference-in-the-design-philosophy-of-chubby-and-zookeeper-39832e49bb8f
- file locking: https://www.baeldung.com/linux/file-locking
- Purdue CS505
- ZooKeeper: Wait-free coordination for Internet-scale systems
- MIT Distributed System: Zookeeper
- Zab algorithm: https://medium.com/@adityashete009/the-zab-algorithm-502781c54498
- Zab wikipedia
- Zab: High-performance broadcast for primary-backup systems