
구글 Spanner의 Paxos 및 TrueTime 활용을 알아보자

[요약]
- Paxos는 분산 시스템에서 사용되는 합의 알고리즘으로 2PC를 확장한 알고리즘으로 볼 수 있습니다.
- Spanner는 lease를 활용한 리더 기반 Paxos를 사용합니다.
- Spanner의 TrueTime은 오차가 제한되는 전역 동기화 시계로 이벤트 간 순서를 정할 때 도움을 줍니다.
- TrueTime을 통해 Spanner는 external consistency 및 MVCC를 제공합니다.
[목차]
- 2PC
- paxos
- Spanner의 paxos
- Spanner의 TrueTime 및 MVCC
이 글은 Spanner: Google's Globally Distributed Database(2013)과 Spanner, TrueTime and the CAP Theorem(2017)을 바탕으로 하였습니다. 위 논문을 이해하기 위한 기초 개념들을 정리하고 Spanner의 TrueTime에 대해서 다룹니다.
Spanner는 구글에서 개발한 글로벌 분산 DB입니다. 구글의 광고 백엔드인 F1 및 Gmail, Google Photo 등 구글의 서비스들이 Spanner를 사용하고 있으며 현재 누구나 구글 클라우드에서 사용할 수 있습니다.
Spanner는 전 세계에 퍼져있는 데이터 센터에 데이터를 샤딩하고 있음에도 partition이 없고 consistent 합니다. CAP 이론을 바탕으로 Spanner를 분류하면 CP 시스템이지만 Spanner의 availability는 1 failure in 10^5 이기 때문에 high availability도 만족합니다.
Spanner는 consistency를 유지하기 위해 전역 동기화 시계인 TrueTime을 도입하였습니다. 네트워크 속도를 아무리 빨리 높이더라도 대륙 간 라운드 트립은 10ms 정도가 걸립니다(구글에서 region은 2ms 라운드 트립이 걸리는 것으로 정의합니다). 일반적으로 넓은 지역에서 발생하는 대용량의 트랜잭션의 순서를 정하는 것은 매우 어려우나 TrueTime으로 external consistency를 달성하는 것을 성공하였습니다.
Spanner는 여느 분산 데이터베이스처럼 2PC와 Paxos를 사용합니다. RAFT 알고리즘이 등장하기 전이었기 때문에 Paxos를 사용하였으나 성능을 위해 살짝 변형하여 leader lease를 지원합니다. 2PC 및 Paxos 사용은 partition 상황이 발생하더라도 항상 consistency를 유지하도록 합니다.
이 글은 Spanner의 TrueTime 및 Paxos에 대해 다룹니다. Spanner를 다루기 전 2pc, paxos 개념을 간단하게 정리하겠습니다.
2PC
2PC(Two phase commit protocol)은 여러 노드에 걸친 원자적 트랜잭션 커밋을 달성하는 분산 알고리즘입니다. 즉 어떤 트랜잭션이 모든 노드에서 커밋 되거나 어보트됨을 보장합니다. 그래서 분산 시스템이 consistency 및 integrity를 유지할 수 있도록 도와줍니다.
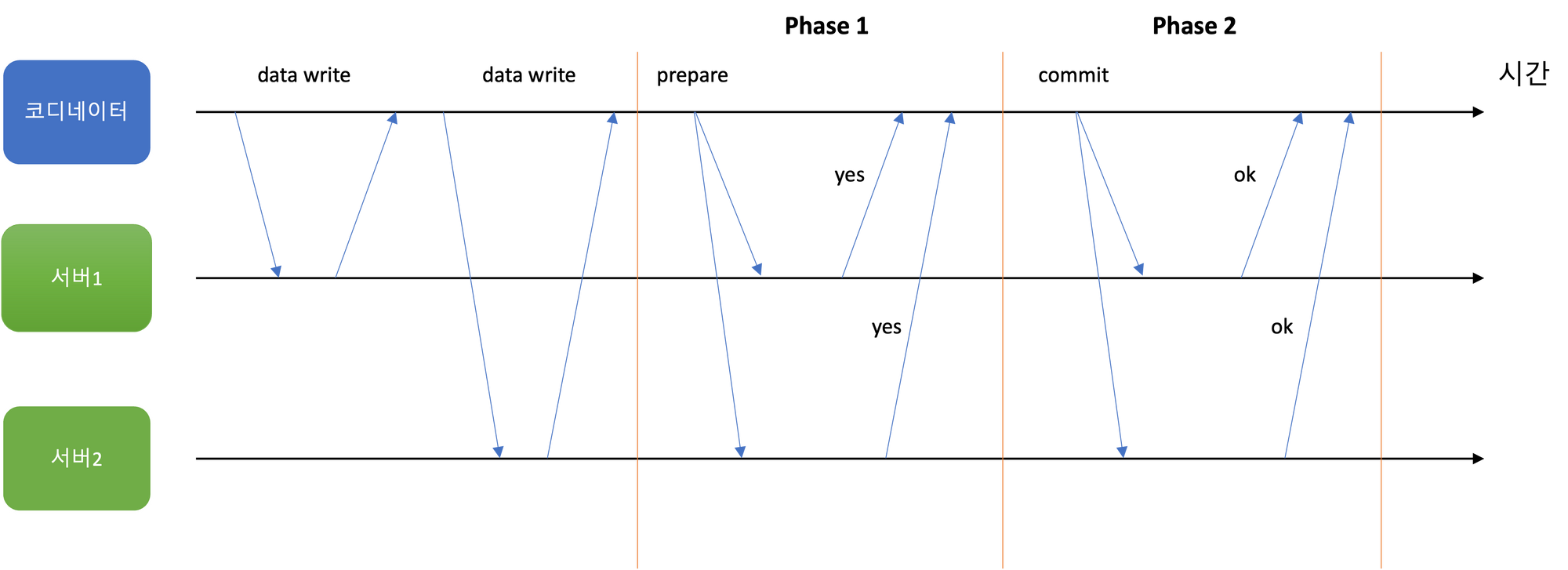
2PC에서는 단일 노드 트랜잭션에서 보통 존재하지 않는 컴포넌트인 코디네이터를 사용합니다. 2PC를 하기 전 어플리케이션은 코디네이터에게 트랜잭션 ID를 요청합니다. 이 트랜잭션 ID는 유일함이 보장되어야 합니다. 해당 트랜잭션 ID로 각 서버에 쓰기 요청을 보냅니다. 이 단계에서 서버가 죽는 등 문제가 있다면 코디네이터 혹은 서버가 요청을 어보트할 수 있습니다.
코디네이터가 모든 서버로부터 쓰기 요청 응답을 받았다면 2PC의 Phase 1이 시작됩니다.
Phase 1
- Prepare: 코디네이터는 모든 서버에게 트랜잭션 ID로 태깅된 준비 요청을 보냅니다. 만약 요청들 중 실패한 것이 있으면 코디네이터는 모든 서버에게 어보트 요청을 보냅니다.
- Promise: 요청을 받은 서버는 트랜잭션을 커밋할 수 있는지 확인합니다. 데이터를 디스크에 쓸 수 있는지(디스크 용량 확인 등), 충돌, 제약 조건 위반 등을 확인합니다. 코디네이터에게 ok를 응답하면 지금 커밋하지 않지만 할 것이라고 약속합니다.
Phase 2
- 코디네이터는 모든 요청으로부터 응답을 받고 트랜잭션을 커밋할지 어보트할지 결정합니다. 만약 코디네이터가 죽으면 2PC는 더 이상 진행되지 않고 멈춥니다. 코디네이터가 다시 시작할 때 2PC를 이어나갈 수 있도록 결정을 디스크의 트랜잭션 로그에 기록합니다(커밋 포인트).
- Accept: 코디네이터가 커밋 포인트를 기록하면 모든 서버에게 커밋이나 어보트 요청이 전송됩니다. 커밋 포인트가 기록되었기 때문에 코디네이터는 요청이 실패하더라도 성공할 때까지 재시도합니다.
- Accepted: 서버는 코디네이터에게 커밋 요청을 받았으면 커밋을, 어보트 요청을 받았으면 어보트를 합니다.
2PC에서는 코디네이터가 중요한 역할을 합니다. 각 서버는 준비 요청을 받고 ok라고 응답하면 일방적으로 어보트할 수 없습니다. 코디네이터가 결정을 하고 응답을 줄 때까지 기다려야 합니다. 이 때문에 코디네이터가 죽거나 네트워크 장애가 나면 서버는 계속 기다리기만 합니다. 만약 일방적으로 어보트를 한다면 다른 서버와 일관적인 결정을 하지 않을 수도 있기 때문입니다.
2PC는 분산 트랜잭션의 안정성 보장을 하지만 성능을 떨어뜨립니다. 디스크 쓰기(fsync)가 강제와 추가 요청이 소모하는 시간이 트랜잭션의 속도를 느리게 만듭니다.
Paxos
Paxos는 분산 시스템에서 사용되는 합의 알고리즘입니다. 1989년에 Lamport에 의해 제안되었으며 2014년 RAFT가 등장하기 전까지 많이 사용되었습니다.
Paxos 알고리즘은 다음을 만족해야 합니다.
- Safety: 단 하나의 value만 선택될 수 있고, 서버는 해당 value가 선택되기 전에 그 값을 배우면 안 됩니다.
- Liveness: 제안된 value 중 일부는 결국 선택됩니다. 서버들은 선택된 value를 언젠가 가집니다.
Basic Paxos의 구성 요소는 proposer와 acceptor로 나눌 수 있습니다.
- Proposer: Acceptor에게 value를 제안하고 클라이언트의 요청을 핸들링합니다.
- Acceptor: Proposer에게 받은 메시지에 응답하고 선택된 값을 보관합니다.
Paxos는 2PC를 확장한 알고리즘으로 볼 수 있어 방식이 매우 흡사합니다. Paxos의 각 라운드는 2개의 phase를 가집니다.
Phase 1
- Prepare: Proposer가 identifier 숫자 N을 붙여 메시지를 생성합니다. 이때 N은 proposer가 이전에 보냈던 메시지들의 숫자보다 커야 합니다. 이 메시지는 최소 정족수 이상의 acceptor들에게 전송되어야 합니다.
- Promise: Acceptor가 Prepare 메시지를 받으면 숫자 N을 확인합니다. 만약 N이 이전에 받은 메시지보다 작으면 무시합니다(구현에 따라 거부 메시지를 보낼 수도 있습니다). 그렇지 않다면 Promise 메시지로 응답합니다. 이때 이전에 받은 메시지가 있다면 해당 숫자를 포함해 응답합니다.
Phase 2
- Accept: Proposer가 정족수 이상의 Promise를 받았으면 메시지에 value v를 할당해 전송합니다. Acceptor가 이전 값을 포함해 Proposer에게 응답했다면 가장 높은 identifer 숫자를 가진 값을 선택해 그 값을 할당합니다. Proposer는 숫자와 값을 포함한 Accept 메시지를 생성하여 Acceptor들에게 다시 전송합니다.
- Accepted: Acceptor가 Proposer에게 Accept 메시지를 받으면 이전에 다른 메시지로 promise가 되어 있지 않다면 무조건 값을 받아들여야 합니다.
Basic Paxos의 예시를 살펴보겠습니다.

서버 5가 Proposal 할 때 서버 3으로부터 value X를 받습니다. 원래 Y로 Proposal을 하려 했으나 X로 변경하여 proposal 하여 모든 서버가 accept된 value가 X가 되었습니다.
케이스 2

케이스 1과 달리 서버 3이 Accept 되기 전 서버 5가 proposal 한 경우입니다. 서버 3은 X가 Y에 비해 오래된 것이므로 X를 거부합니다. Y를 선택한 서버가 과반이기 때문에 케이스 1과 달리 Y가 선택됩니다.
2PC vs Paxos
Paxos와 2PC의 차이점은 무엇일까요? 동작은 비슷하지만 2PC는 모든 참여자의 동의를 받아야 하는 반면 paxos는 정족수 이상의 참여자에게 동의를 받으면 됩니다. Paxos는 identifier를 사용하여 요청의 순서를 정하는 것도 차이가 있습니다. 또 다른 주요한 차이점은 2PC의 경우 코디네이터가 실패하게 되면 동작이 멈추게 됩니다. Paxos의 경우 코디네이터가 따로 없고 Proposer가 중간에 실패하더라도 acceptor가 상태를 보관하고 있기 때문에 다른 acceptor가 이를 대체할 수 있습니다. 이번 글에서는 Paxos를 간략하게 다루었지만 좀 더 자세한 설명을 원하신다면 Paxos를 제안한 Lamport가 작성한 Consesns on Transaction Commit을 보는 것을 추천드립니다.
Spanner의 Paxos
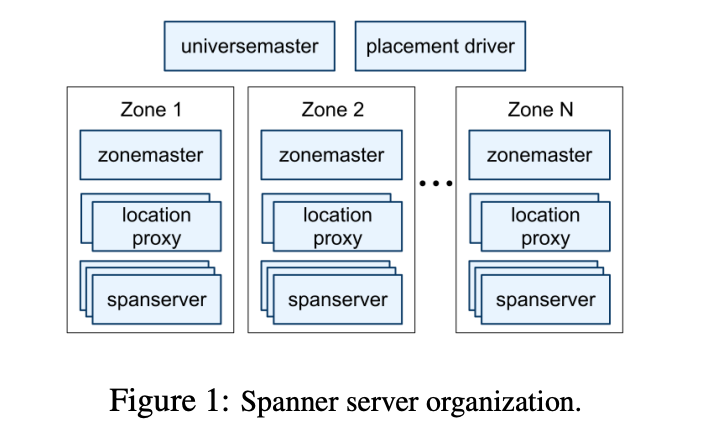
Spanner는 zone 단위로 조직화되어 있습니다. 각 데이터는 zone 단위로 레플리카가 형성되고 zone은 실행 중인 시스템에서 추가되거나 제외될 수 있습니다. 또한 zone은 물리적으로 분리된 단위이기도 합니다.
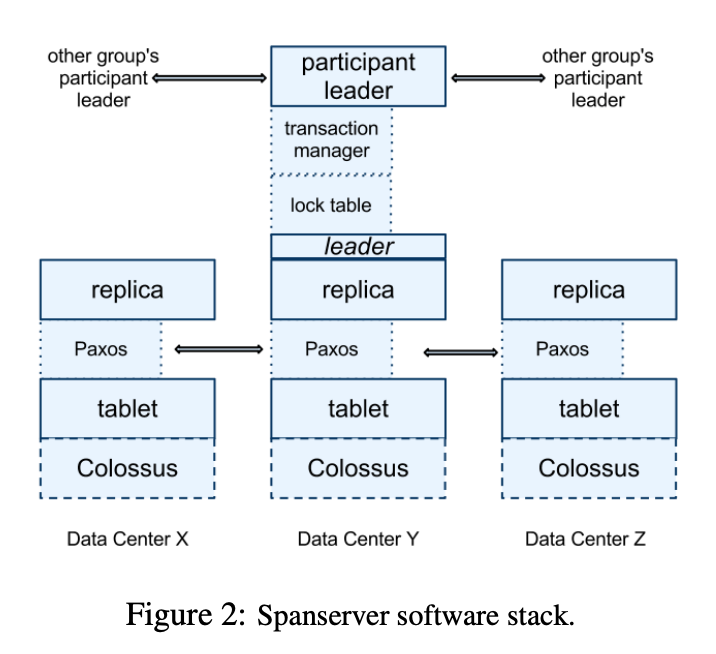
각 zone은 수 백~ 수 천 개의 spanserver를 가지고 각 spanserver는 다시 100~1000개의 tablet을 가집니다. Tablet은 (key: string, timestamp: int64) -> string 매핑을 구현한 자료구조입니다.
Replication을 지원하기 위해 spanserver는 각 tablet에 Paxos state machine을 구현합니다. Replica set은 하나의 paxos group으로 관리됩니다.
분산 트랜잭션을 처리할 때 트랜잭션이 두 개 이상의 paxos group을 포함하면 각 그룹의 리더는 2PC를 수행합니다. 2PC는 모든 참여자가 작동해야 정상적으로 진행됩니다. Spanner는 참여자의 단위를 paxos group으로 설정함으로써 일부 노드가 죽더라도 2PC가 진행될 수 있도록 하였습니다.
앞서 paxos를 살펴볼 때 proposer가 여러 개인 경우로 설명하였으나 효율을 높이려면 proposer는 한 개인 것이 좋습니다. 충돌이 발생할 수 있기 때문이죠. Proposer를 한 개를 사용할 때 해당 proposer를 리더라고 합니다. 리더가 트랜잭션을 도맡으면 identifer를 통해 이벤트의 순서를 정하는 phase 1 생략도 가능합니다. 리더가 순차적으로 요청을 할 수 있기 때문입니다.
Spanner도 리더 기반의 paxos를 사용합니다. 여기서 lease라는 개념이 나옵니다. 리더 후보는 참여자들에게 timed lease votes 요청을 보냅니다. 정족수 이상의 vote를 받으면 후보는 자신이 lease를 받았다고 인지하고 리더가 됩니다. 이 lease의 만료가 다가오면 참여자들에게 lease 기한을 늘리는 요청을 보내 리더 역할을 연장합니다. 참고로 Spanner의 lease 기한은 10초라고 합니다.
리더 기반의 paxos를 사용하면 리더 간 트랜잭션의 단조증가를 보장하는 것이 중요합니다. 모든 참여자들에 대하여 현재 리더가 보낸 트랜잭션이 이전 리더가 보낸 트랜잭션 이후에 적용되는 것을 보장해야 한다는 것이죠. 그래서 리더가 실패했을 때 할 수 있는 옵션은 2가지가 있습니다.
1) lease가 만료될 때까지 기다리고 새 리더를 뽑는다
2) 실패한 리더를 재시작한다.
최적화로 특정 실패 시 "last gasp" UDP 패킷을 참여자들에게 보내 lease의 만료 시간을 앞당기기도 합니다.
이로써 lease는 리더 간 단조성을 보장하고 리더가 없더라도 참여자들이 읽기를 수행할 수 있도록 만듭니다.
Paxos에 lease를 도입할 만큼 단조성은 중요합니다. 이벤트의 순서를 정할 수 없다면 현재의 값을 이전 값으로 덮어쓰거나 이전 값을 읽는 등 여러 문제가 발생할 것입니다. 이런 문제의 해결 방법 중 하나는 각 이벤트에 정확한 타임스탬프를 매기는 것입니다. 다음 챕터에서는 spanner의 타임스탬프를 정하는 TrueTime에 대해서 알아보겠습니다.
Spanner의 TrueTime 및 MVCC
앞서 본 Paxos는 합의 알고리즘입니다. 분산 시스템을 이루는 서버들이 동일한 상태를 갖게 만드는 알고리즘인 것이죠.
분산 시스템에서 주요 이슈 중 하나는 이벤트의 순서를 결정하는 것입니다. 변수 x를 1로 설정하는 요청 A와 변수 x를 2로 설정하는 요청 B가 있다고 해봅시다. 서버 1은 A - B 순서로 받고, 서버 2는 B - A 순서로 요청을 받았다면 서버 1과 서버 2의 x 값은 달라질 수 있습니다.
만약 각 트랜잭션의 커밋 시각을 정확하게 알 수 있다면 항상 트랜잭션의 순서를 올바르게 정할 수 있을 것입니다. 하지만 각 서버가 보는 시각은 정확하지 않습니다.
데이터 중심 어플리케이션 설계에 나온 몇 가지 예를 살펴보겠습니다.
- 서버의 시계는 drift 현상(더 빠르거나 느리게 실행)이 생깁니다. drift는 장비의 온도에 영향을 받습니다. 구글은 자신들의 서버에 200ppm drfit가 있다고 가정합니다(30초마다 6ms 정도)
- NTP 동기화는 잘해봐야 네트워크 지연만큼만 좋을 수 있어 정확도에 한계가 있습니다.
- 윤초가 발생하면 윤초를 고려하지 않은 시스템에서는 시계를 완전히 망가뜨릴 수도 있습니다
- 가상 장비에서 하드웨어 시계는 가상화되어 추가적인 어려움이 생깁니다
Spanner는 TrueTime이라는 오차가 제한되는 전역 동기화 시계를 사용합니다. TrueTime API를 호출하면 가능한 타임스탬프 범위 중 가장 이른 것과 가장 늦은 것을 가리키는 [earliest, latest]를 받습니다.

만약 두 트랜잭션의 타임스탬프 범위가 겹치지 않는다면 순서를 정할 수 있습니다. 물론 겹친다면 순서를 알 수 없어 완벽한 해결책은 아닙니다. 하지만 간단하게 해결할 수 있는데, paxos의 리더가 트랜잭션의 구간이 겹치지 않도록 기다리고 커밋을 수행하면 됩니다.
TrueTime의 Time Source

TrueTime은 모든 구글 데이터 센터에 배포되어 있는 GPS와 atomic clock을 기반으로 합니다. 두 기반이 실패 조건이 다르므로 안정적으로 비교적 정확한 시간을 제공할 수 있습니다. GPS의 경우 안테나, 지역 radio, GPS 시스템 등에 영향을 받을 수 있는 반면 atomic clock은 frequency error가 일어날 수 있습니다.
각 데이터 센터는 time master 머신 세트를 가지고 있습니다. 대부분의 마스터는 GPS 수신기와 안테나를 가지고 있고 서로 영향을 줄이기 위해 물리적으로 분리되어 있습니다. 나머지 마스터 노드(아마겟돈 노드)는 atomic clock을 가집니다. 각 마스터는 자신의 로컬 시계와 나머지 마스터 노드들을 비교하고 차이가 심하면 스스로 마스터 세트에서 제외합니다.
서버들은 가까운 센터에서 선택한 GPS 마스터, 멀리 떨어진 데이터 센터의 GPS 마스터, 아마겟돈 마스터 등 다양한 마스터로부터 시간을 제공받습니다. 서버는 Marzullo 알고리즘의 변형을 이용하여 잘못된 시간을 거부하고 로컬 시계를 동기화합니다. 서버의 동기화 인터벌은 평균 30초 정도이며 구글이 가정한 drift rate가 200us/s이므로 6ms까지 오차가 날 수 있습니다.
External Consistency와 MVCC
External consistency는 가장 엄격한 트랜잭션의 동시성 제어입니다. External consistency를 만족하는 분산 시스템은 여러 서버에서 트랜잭션을 실행하더라도 모든 트랜잭션이 순차적으로 실행되는 것처럼 작동합니다. Spanner는 external consistency를 만족하며 따라서 사용자는 단일 머신 DB와 구별을 할 수 없습니다.
External consistency를 만족하는 기존 DB는 단일 버전 스토리지와 2단계 잠금(2PL)을 사용합니다. 2PL은 쓰기 트랜잭션이 진행 중인 객체에 대한 읽기 트랜잭션을 막는다는 단점이 있습니다.
MVCC는 다중 버전을 관리하여 쓰기 트랜잭션과 상관없이 읽기 트랜잭션이 가능합니다. 만약 단조 증가하는 타임스탬프가 없다면 MVCC 구현은 어렵습니다. 은행 시스템에서 입금 트랜잭션 - 출금 트랜잭션 - 잔고 읽기 트랜잭션을 진행하는 예를 생각해 봅시다. 출금 트랜잭션을 처리한 머신의 타임스탬프가 입금 트랜잭션 타임스탬프보다 빠르다면 잔고를 읽었을 때 출금 트랜잭션만 보일 수도 있습니다.
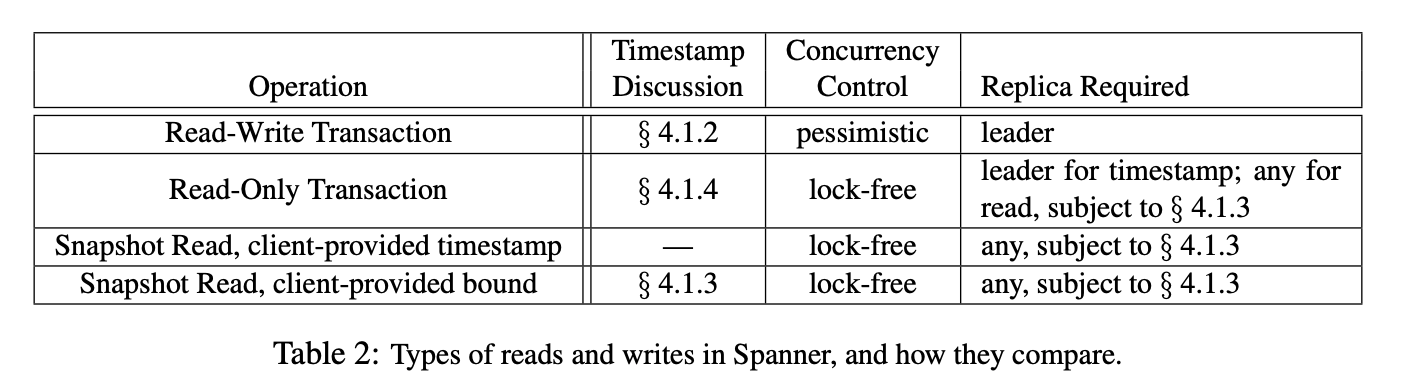
Spanner는 TrueTime이 제공하는 단조 증가 타임스탬프로 MVCC(Multi-version concurrency control)까지 지원합니다. 따라서 spanner의 읽기 트랜잭션은 잠금이 필요 없습니다. 쓰기 트랜잭션은 자신의 타임스탬프를 버전으로 하여 새로운 스냅샷을 생성합니다. 읽기 트랜잭션에 부여된 타임스탬프 이전의 버전 중 최신 버전을 읽습니다. 대신 읽기 트랜잭션이 수행되는 레플리카는 충분히 업데이트 되었음이 보장돼야 합니다.
Spanner는 레플리카의 업데이트된 타임스탬프를 확인하여 해당 레플리카가 읽기 트랜잭션이 수행될 수 있는지 판단합니다. 읽기 트랜잭션의 타임스탬프가 레플리카의 타임스탬프보다 작다면 읽기 트랜잭션이 수행될 수 있습니다.
마치며
이번 글은 Spanner 그 자체보다는 Spanner가 사용한 paxos, 2pc, mvcc 등을 위주로 알아보았습니다. Spanner의 자세한 구현에 대해서 알아보고 싶으신 분들은 Spanner: Google's Globally-Distributed Database을 보시는 것을 추천합니다.
분산 시스템을 다루거나 관심 있으신 분들에게 이번 글에서 다룬 개념이 조금이나마 도움이 되었으면 좋겠습니다.
Reference
Spanner: Google's Globally-Distributed Database
Spanner, TrueTime and the CAP Theorem
데이터 중심 어플리케이션 설계