
[논문 리뷰] On-demand Container Loading in AWS Lambda
![[논문 리뷰] On-demand Container Loading in AWS Lambda](https://images.unsplash.com/photo-1682686578615-39549501dd08?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wxfDF8YWxsfDF8fHx8fHwyfHwxNjk1ODA3MTQyfA&ixlib=rb-4.0.3&q=80&w=2000)
[요약]
- On-demand Container Loading in AWS Lambda는 Block-level loading, Deduplication 및 Tiered cache을 도입해 scalability 및 cold start latency를 줄이는 방법을 소개한다.
- Block-level loading은 이미지를 flattening process를 거쳐 하나의 파일 시스템으로 만든 뒤 chunk로 나누어 캐시에 올린다.
- 캐시에 이미지를 올릴 때 같은 내용의 이미지는 같은 key로 암호화하여 최대한 이미지를 deduplication한다. 이에 대한 리스크는 key에 추가 salt를 더하여 조절한다.
- AWS의 Tiered cache는 erasure coding, concurrency-limited system, LRU-K 등을 사용하고 있다.
[목차]
- 논문 간단 소개
- Prerequisite: overlayFS, virtio-blk
- AWS Lambda 기존 아키텍처
- Block-Level Loading
- 이미지 deduplication
- Tiered cache
1. 논문 간단 소개
On-demand Container Loading in AWS Lambda는 USENIX ATC 23에서 Award된 논문이다.
이 논문에서는 Block-level loading, Deduplication 및 Tiered cache을 도입해 scalability 증가 및 cold start latency를 줄이는 방법을 소개한다.
cold start latency란 로드가 증가할 때 scale up 하기까지 걸리는 시간을 말한다. cold start latency를 줄이기 위해서는 데이터 이동을 줄이는 것이 핵심이다. 사용자는 Lambda에 함수를 압축한 형태(.zip)로 배포하는데, 각 함수 인스턴스가 할당될 때마다 압축 해제한다. 사용자들은 Lambda가 이미지를 관리하는 것까지 요구하고 있다.
현재 AWS Lambda는 현재 사용자 한명당 초당 15000개 컨테이너 생성을 지원을 목표로 하고 있다. 만약 각 컨테이너의 이미지가 10GB라면 사용자 한명이 초당 150PB의 네트워크 bandwidth를 사용하는 것이다.
2. Prerequisite: overlayFS, virtio-blk
논문을 리뷰하기 전 overlay filesystem과 virtio-blk에 대해 간단히 설명하고 넘어가겠다.
Overlay Filesystem (overlayFS)
Overlay filesystem은 2개 이상의 디렉토리를 union할 수 있게 만드는 파일 시스템이다. Union이란 여러 개의 디렉토리를 합쳐 마치 한 개의 통합된 디렉토리처럼 보이게 만드는 것을 말한다.
Overlay filesystem이 만드는 union 디렉토리의 대상은 lower 디렉토리 리스트와 upper 디렉토리 1개로 나눌 수 있다. lower 디렉토리는 read only인 반면 upper 디렉토리는 read와 write이 둘 다 가능하다.
예시를 한번 살펴보자.
$ ls
lower merge upper work
$ mount -t overlay overlay-example -o lowerdir=lower/,upperdir=upper/,workdir=work/ merge예시에서 merge 디렉토리는 union된 통합 디렉토리이다. merge 디렉토리를 보면 lower 디렉토리와 upper 디렉토리의 파일들을 모두 볼 수 있다. work 디렉토리는 원자성을 보장하기 위한 중간 계층이다.
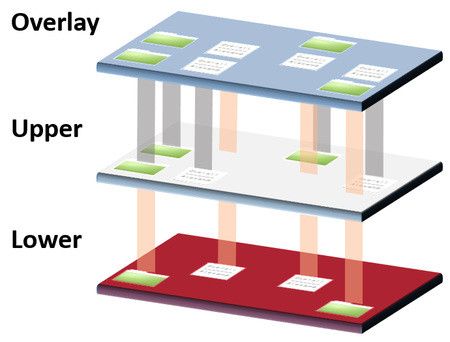
Overlay Filesystem은 컨테이너 이미지를 이해하기 위해 알고 있어야 한다.
컨테이너 이미지는 본질적으로 root file system과 메타 데이터를 가진 tar file이다. 컨테이너 이미지를 실행시키면 도커는 이미지에 대한 tarball을 다운로드 받고 각 레이어를 분리된 디렉토리에 푼다. 그리고 overlay filesystem은 비어 있는 upper 디렉토리와 이들을 마운트하여 union 디렉토리를 생성한다. 그렇기 때문에 컨테이너가 write하는 것들은 비어 있는 upper 디렉토리에 쓰여지고 각 레이어가 담겨있는 디렉토리는 변경이 되지 않는다.
virtio-blk
virtio는 virtual io, blk는 block을 의미한다.
virtio-blk는 VM의 block device에 표준 인터페이스를 제공하기 위해 디자인되었다. virtio-blk를 사용하면 near-native IO 성능을 얻을 수 있는데, 하이퍼바이저와 최적화된 인터페이스를 사용하여 통신하는 것이기 때문이다.
virtio-blk를 이해하려면 다음 2가지 개념을 알고 있어야 한다.
- Paravirtualization: full hardware device를 에뮬레이팅하는 것이 아니라 VM에 device의 단순한 추상화 버전을 제공하는 것. Full hardware device를 제공하는 것보다 빠르다.
- Block device: 고정 크기 chunk(block)에 대한 스토리지 및 retrieval을 허용하는 device. 하드 드라이브, SSD 등이 해당된다.
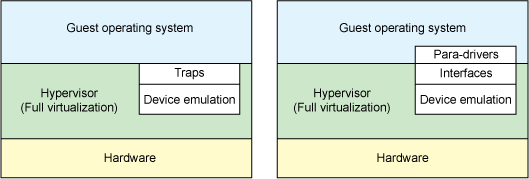
Full virtualization은 게스트 OS가 하이퍼바이저 위에서 돌고 게스트는 가상화되어 있는지 모를 뿐더러 설정할 필요도 없다.
Paravirtualization은 게스트 OS가 하이퍼바이저 위에서 돈다는 것을 알 뿐만 아니라 guest-to-hypervisor 트랜지션을 효율적으로 만드는 코드를 포함해야 한다.
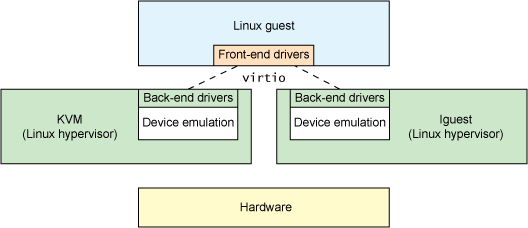
virtio는 paravirtualization 하이퍼바이저의 추상화 레이어이고, virtio-blk는 그 레이어의 block device를 말한다.
3. Aws Lambda 기존 아키텍처
위 논문에서 나온 기존 AWS Lambda의 아키텍처를 먼저 살펴보자.
기존 아키텍처
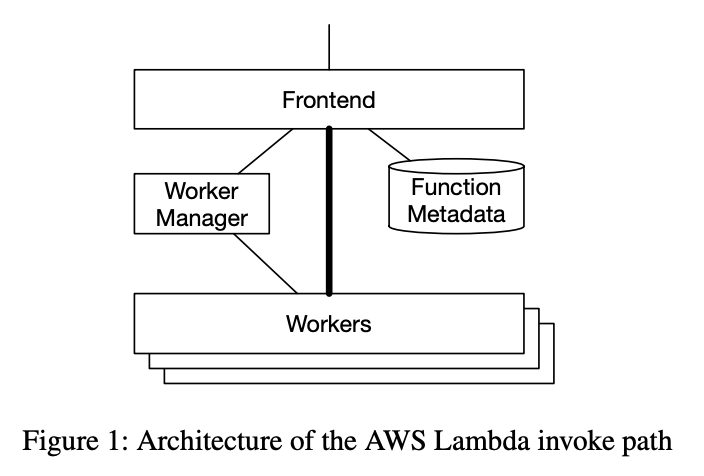
AWS Lambda에 대한 요청이 프론트엔드로 오면 인증을 거친 뒤 Worker Manager로 전달된다.
Worker Manager는 시스템의 모든 unique 함수에 대해 함수를 실행할 수 있는 capacity를 트래킹한다.
- Capacity가 충분하면 worker로 포워딩한다
- 충분하지 않다면 충분한 CPU와 RAM을 가진 worker를 찾아 함수를 실행할 수 있는 Sandbox를 시작하라고 요청한다. 이 작업이 완료되면 프론트엔드는 알림을 받고 함수를 실행시킨다.
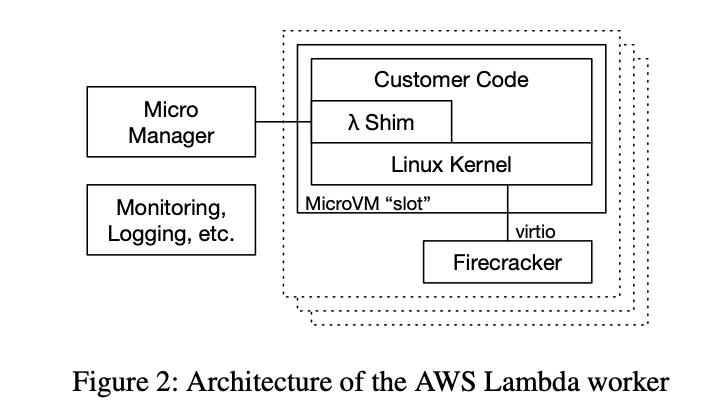
각 Lambda Worker의 구조는 위와 같다.
Micro Manager
- 로깅과 모니터링을 하는 agent
MicroVM
- 매우 많이 존재한다.
- 한 명의 소비자를 위한 single lambda function에 대한 코드를 가지고 있다.
- 최소화된 리눅스 게스트 커널을 가지고 있다. 이 커널은 작은 shim으로서 lambda의 프로그래밍 모델과 런타임(JVM, CoreCLR 등), 사용자의 코드 및 라이브러리를 제공한다.
- 사용자의 코드와 데이터는 믿을 수 없어 MicroVM 내부 workload와 Worker 컴포넌트의 커뮤니케이션은 단순하고 테스트가 잘 되어 있다. 보통 인증된 구현의 virtio이다.
새로운 MicroVM이 생성되면 Worker는 함수 이미지를 아마존 S3로부터 다운받고 이를 MicroVM의 게스트 파일 시스템에 푼다.
장점: 단순하고 작은 이미지에서 잘 작동
단점: MicroVM이 전체 아카이브를 다운 받고 푼 뒤 작업을 할 수 있음
4. Block-Level Loading
기존 아키텍처의 단점을 보완하기 위해 어플리케이션이 필요한 데이터만 시스템이 로드할 수 있게할 필요가 있었다.
이를 위해 block-level virtio-blk 인터페이스를 Micro VM 게스트와 게스트 내부의 파일 시스템 작업을 실행하는 하이퍼바이저 사이에 유지하도록 결정하였다. 이는 파일이 아닌 block의 sparse loading을 수행하도록 한다.
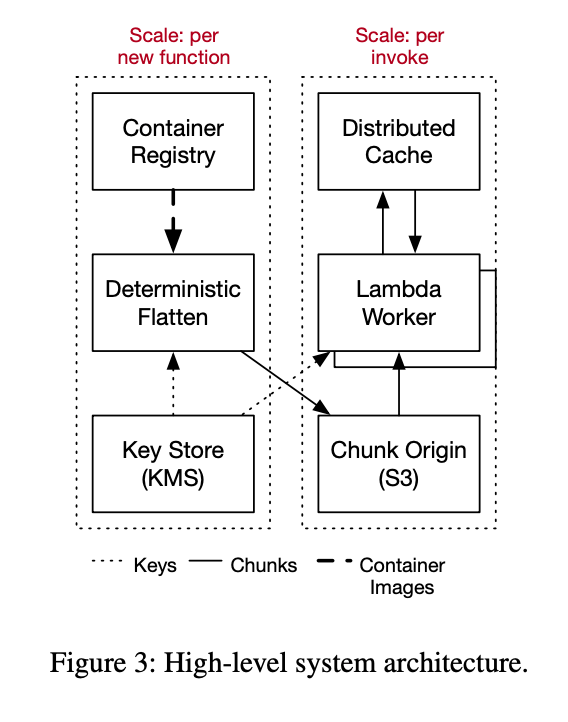
- Lambda worker: 사용자의 코드를 실행시킴
- Container Registry: 사용자의 컨테이너 이미지의 primary copy를 가짐
Block level loading을 지원하기 위해 컨테이너 이미지를 block device 이미지로 나눠 저장한다.
일반적으로 앞서 (2)에서 보았던 것처럼 컨테이너 스택에서 이미지 레이어들은 overlayFS를 런타임때 사용해 overlay가 된다.
그러나 이 논문에서 AWS는 overlay 오퍼레이션은 함수가 처음 만들어질때만 수행하고 각 레이어가 하나의 ext4 파일 시스템을 생성하도록 만들었다고 한다(flattening process). 함수 생성은 사용자가 코드, 설정, 아키텍처에 수정을 가할때만 트리거되어 낮은 비율로 발생한다.
Flattening process는 파일 시스템 block이 같고 common base 레이어를 공유하는 컨테이너간 flatten된 이미지를 블록 레벨에서 deduplication 할 수 있게 만든다. Flattening process는 각 레이어를 하나의 ext4 파일 시스템에 푼다. 이때 AWS는 파일 시스템을 수정하여 모든 오퍼레이션을 deterministic하게 수행하도록 변경하였는데, 이를 통해 수정 날짜와 같은 변수들을 serial하고 deterministic하게 선택할 수 있다(대부분의 파일 시스템 구현은 성능을 위해 concurrency를 도입한다).
Flattened된 파일 시스템은 고정 크기의 chunk들로 나누어지고 대부분의 chunk는 캐시로 업로드된다(이 논문에서는 S3를 사용했다). Chunk의 이름은 가지고 있는 content를 사용해 만들어지기 때문에 같은 content를 가진 chunk는 같은 이름을 갖는 것이 보장되고, 한번만 캐시가 된다.
Chunk의 고정 크기는 512KiB이다. 크기가 작아지면 false sharing을 줄이고 높은 random access 성능을 보인다. 크기가 커지면 메타데이터의 크기를 줄이고 데이터 로드 request가 줄어드는 효과가 있다.
Block level loading을 적용한 새로운 아키텍처는 아래와 같다.
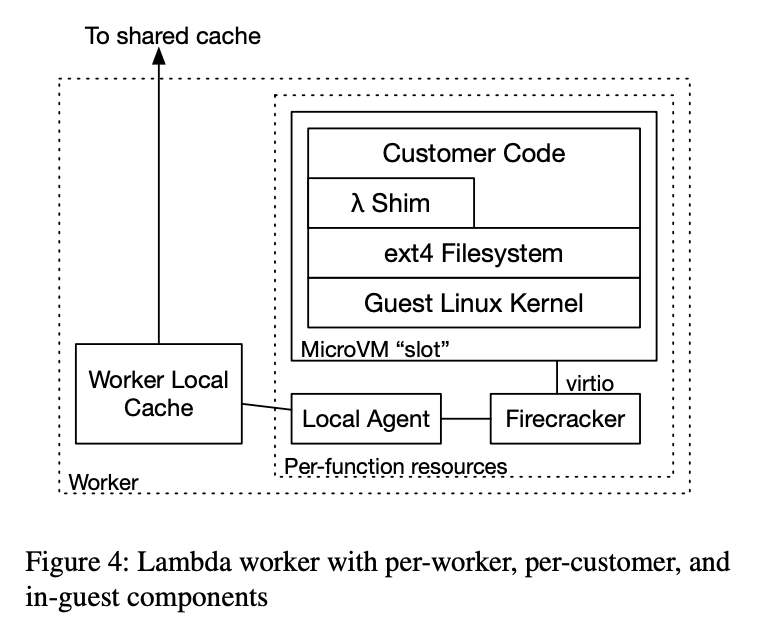
새로운 아키텍처에서 chunk에 접근하기 위해 2가지 컴포넌트가 추가되었다.
- per-function local agent: Firecracker 하이퍼바이저로의 block device를 나타낸다.
- per-worker local cache: worker에서 자주 사용되는 chunk를 캐시하고 remote cache와 상호작용한다.
Lambda 함수가 worker에서 새로 시작하면 Micro Manager는 새로운 local agent와 두 virtio block device를 가진 Firecracker MicroVM을 생성한다. 이 MicroVM이 부팅되면 supervisory 컴포넌트들과 컨테이너 이미지의 사용자 코드를 실행한다. 코드가 실행하는 각 IO는 virtio-blk 요청으로 들어가고 이는 Firecracker에 의해 실행되며 local agent로 전달된다.
local agent는 읽기 처리시 로컬 캐시에 chunk가 존재하면 직접 읽고 없다면 tiered cache에서 관련된 chunk를 가져온다. local agent는 쓰기 처리시 worker 스토리지의 block overlay에 write한다. 또한 데이터를 overlay 혹은 backing 컨테이너에서 읽어야할지 알려주는 bitmap을 유지한다.
5. 이미지 deduplication
대부분 비슷한 base 컨테이너 이미지를 사용하기 때문에 새로 업로드되는 Lambda 함수의 80%는 유니크한 chunk가 0개였으며 과거에 업로드된 이미지를 재업로드한 것이 확인되었다. 따라서 이미지를 deduplication하는 것이 큰 도움이 된다.
이미지를 암호화할 때 같은 내용에 대해 다른 키로 암호화하면 다른 결과가 나오기 때문에 deduplication하기 어렵다.
AWS는 flattening process시 각 chunk에서 SHA256 digest를 계산해 key를 구하고 AES-CTR을 사용해 block을 암호화하였다. AES-CTR은 암호화된 결과가 같으면 같은 plaintext인 것을 보장한다.
Deduplication은 비용과 성능에서 이점이 있어나 리스크 또한 존재한다.
- 특정 chunk가 많이 쓰이기 때문에 해당 chunk로의 접근이 실패하거나 느려질 수 있고 이는 전체 시스템에 영향을 미침
- 손상된 데이터가 있으면 감지할 수 있으나 고치지 못함
이러한 리스크를 해결하기 위해 key를 구하는 과정에서 다양한 salt를 포함시킨다. salt는 시간, chunk의 popularity, 인프라 위치에 따라 달라진다. 같은 chunk여도 다른 salt를 가지면 다른 ciphertext를 가지기 때문에 서로를 deduplicate하지 않는다. salt가 rotate되는 주기를 조절함으로써 트레이드 오프를 조절할 수 있다.
6. Tiered cache
AWS의 Tiered Cache
AWS는 캐시를 계층화하여 사용한다. 만약 local cache에 chunk가 없다면 worker는 remote AZ level shared cache로부터 chunk를 가져온다. 그곳에도 없으면 S3로부터 다운로드하고 cache로 업로드한다.
AWS가 사용하는 캐시 기법에는 어떤 것이 있는지 살펴보자.
(1) Til latency
단순한 레플리카가 없는 캐시 스킴은 크게 3가지 문제를 발생시킨다.
Til latency
- 하나의 느린 캐시 서버가 widespread impact를 일으킨다
Hit Rate Drops
- 아이템이 하나의 싱글 서버에만 있으면 서버가 실패되거나 배포시 Hit Rate가 급락한다.
Throughput Bounds
- item이 하나의 싱글 서버에 있으면 해당 서버의 bandwidth로 bound된다.
이 3가지 문제 중 Til latency가 가장 큰 문제였다. 1000개의 chunk를 fetch하면 캐시의 99.9th percentile tail latency가 전체 태스크의 63%를 차지했을 정도였다.
Replication을 사용하면 til latency를 낮추고 throughput 및 hit rate 문제도 풀 수 있다. 그러나 replicaiton은 비용이 증가하는 단점이 있다.
대신 AWS는 erasure coding을 선택하였다. Worker가 캐시 미스했을 때 원본으로부터 chunk를 fetch하고 erasure-coded chunk를 캐시에 업로드함. Worker가 chunk를 가져올 때 chunk를 재건하는데 필요한 stripe보다 더 많이 요청한다. 현재 production에서는 4 of 5 code를 사용해 25% 스토리지가 오버헤드고 이는 til latency의 큰 감소를 만들었다. 이를 통해 캐시 노드가 실패 혹은 배포시에 hit rate가 drop되는 것을 효과적으로 막았다.
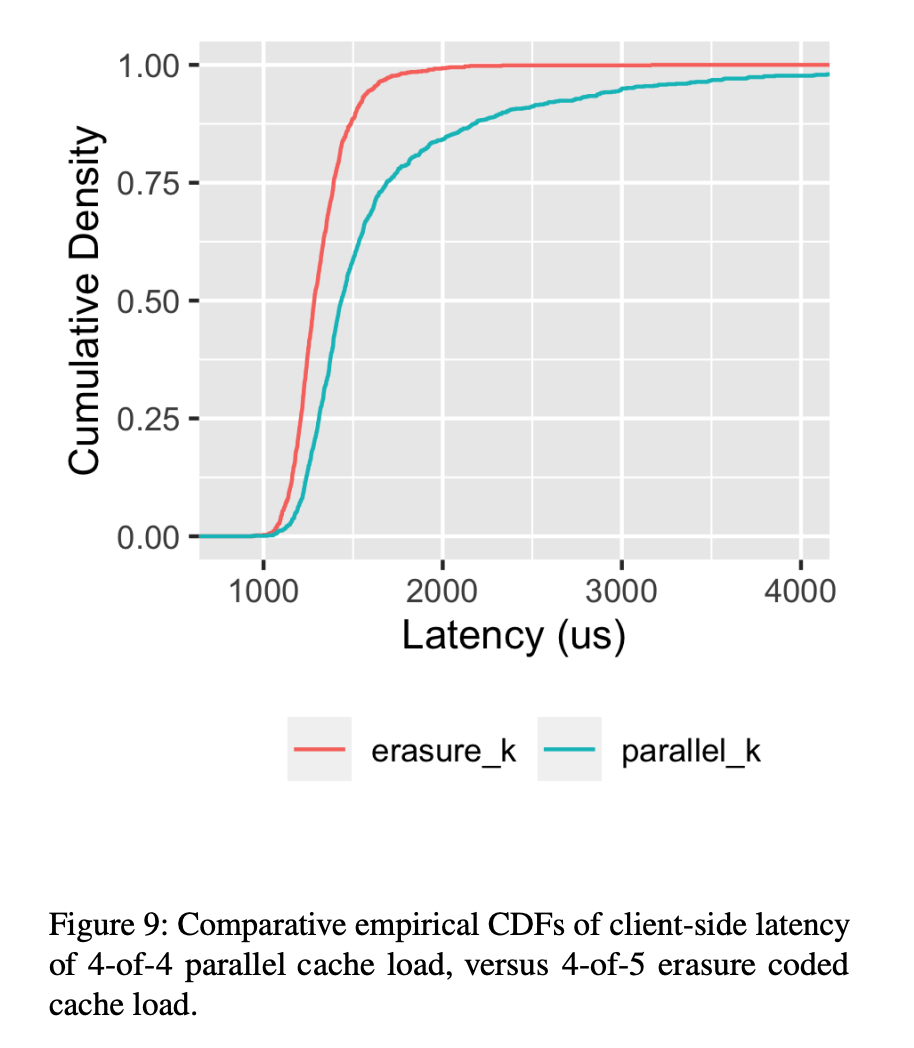
(2) 안정성(stability)
높은 캐시 히트율은 숨겨진 단점이 있다. 만약 캐시가 비어있을 때(poser loss나 운영 이슈 등으로)나 히트율이 갑자기 줄어들었을 때(사용자 행동 변화 등) downstream 서비스의 트래픽이 갑자기 치솟을 수 있다.
AWS의 경우 캐시 end-to-end 히트율이 99.8% 였으나 downstream 트래픽이 평소보다 500배 치솟을 수도 있었다. Downstream의 latency 증가는 높은 concurrency demand를 일으켜 lambda slot의 증가를 일으킨다.
concurrency-limited 시스템을 디자인하면 이를 어느정도 해결할 수 있다. concurrent task 개수가 제한을 넘길 때 새로 뜨는 컨테이너는 하나가 끝날때까지 거절된다.
(3) Cache eviction and sizing
전통적인 캐시 정책은 LRU나 FIFO 처럼 단순하고 구현하기 쉬운 것이다. 하지만 AWS의 경우 이를 적용시 문제가 있었다.
자주 사용되지 않는 함수들의 recently-used entry가 캐시의 hot entry를 전부 교체하여 캐시 히트율을 감소시키는 경우가 존재했기 때문이다. 이는 주기적인 cron job 함수로 인해 계속해서 발생하였고, 이러한 함수들은 매우 많지만 각각은 low scale로 실행되어 캐시의 역할을 크게 떨어뜨렸다.
이런 주기적인 작업에 의한 캐시 히트율 감소를 줄이기 위하여 LRU-k eviction 알고리즘을 사용하였다. LRU-K는 캐시에 존재하는 item의 최근 K번을 트래킹한다.
Reference