
[논문 리뷰] Databases in the Era of Memory-Centric Computing
![[논문 리뷰] Databases in the Era of Memory-Centric Computing](https://images.unsplash.com/photo-1461354464878-ad92f492a5a0?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDJ8fHNoYXJlfGVufDB8fHx8MTc1MjM4NTI4Mnww&ixlib=rb-4.1.0&q=80&w=2000)
CPU의 성능 발전 속도에 비하여 메모리의 용량 발전 속도는 계속해서 느려지고 있습니다. 이러한 문제점에서 출발한 Databases in the Era of Memory-Centric Computing은 상대적으로 점차 비싸지고 있는 메모리를 효율적으로 활용하기 위한 아키텍처를 제시하였으며 이 구조가 특히 Database에 효율적이라고 말합니다.
해당 논문은 2025년 출판되었으며 비교적 신기술인 CXL을 memory-centric computing을 구현하기 위한 핵심 기술로 다루고 있습니다.
이번 리뷰에서는 먼저 CXL이 무엇인지 간단히 다루고, 해당 논문이 제시한 아키텍처를 살펴보겠습니다.
1. CXL Overview
1.1 CXL이 무엇인가?
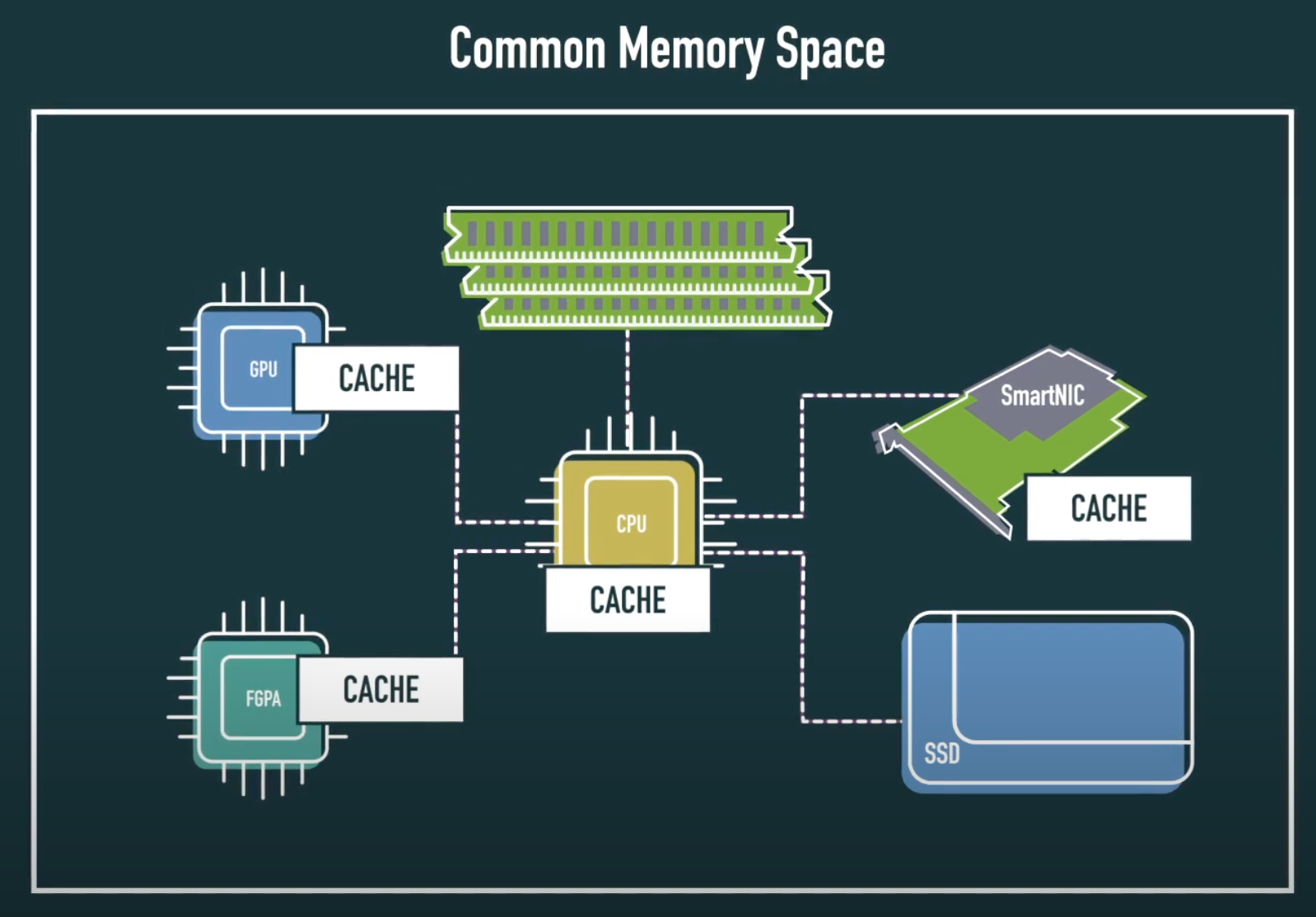
CXL(Compute Express Link)은 고속 인터커넥트 표준으로, CPU와 가속기(accelerator), 메모리 장치 간에 저지연, 고대역폭, 캐시 일관성을 유지한 채 데이터를 주고받을 수 있도록 설계된 기술입니다.
CXL은 PCI Express(PCIe) 5.0의 물리 계층을 기반으로 동작하며, 기존 PCIe의 호환성과 연결성을 유지하면서도, 메모리 공유와 일관성 유지라는 핵심 기능을 추가로 제공합니다. 즉, CXL을 통해 호스트 CPU는 외부 장치의 메모리를 마치 자신의 메모리처럼 접근하고 사용할 수 있으며, 반대로 가속기는 CPU의 메모리를 직접 접근하여 데이터를 읽고 캐시할 수 있습니다.
1.2 CXL 아키텍처: 3개의 프로토콜
CXL은 단일 물리 링크에서 세 가지 프로토콜을 동시에 운용하는 멀티 프로토콜 구조를 갖습니다.
CXL.io
CXL.io는 PCIe와 동일한 방식으로 장치를 초기화하고, DMA 전송, 레지스터 접근, 인터럽트 처리 등의 표준 I/O 작업을 수행합니다. 시스템이 CXL을 지원하지 않더라도, CXL 장치는 PCIe 장치로서 동작할 수 있으며, 양쪽이 CXL을 모두 지원할 경우 CXL 프로토콜로의 전환할 수 있습니다.
CXL.cache
가속기나 스마트 NIC 등의 장치가 호스트 CPU의 메모리를 직접 접근하고 캐시할 수 있도록 하는 프로토콜입니다. 하드웨어 수준의 캐시 일관성 메커니즘을 통해, 장치가 읽고 쓰는 메모리 내용이 CPU 캐시와 자동으로 동기화됩니다. 이를 통해 소프트웨어 복사 없이도 데이터를 공유할 수 있게 하며, 지연 시간을 줄이고 처리 속도를 크게 향상시킵니다.
CXL.mem
호스트 CPU가 CXL 장치에 탑재된 메모리(DRAM 또는 비휘발성 메모리 등)를 자신의 메모리처럼 직접 load/store 방식으로 접근할 수 있습니다. 장치 메모리는 CPU의 물리 주소 공간에 매핑되며, NUMA 영역처럼 인식됩니다. 이를 통해 시스템의 메모리 용량을 유연하게 확장할 수 있고, 기존 PCIe 기반 메모리 접근보다 훨씬 낮은 레이턴시를 제공합니다.
1.3 CXL 장치 유형
CXL은 장치를 세 가지 유형으로 분류합니다. 각 유형은 메모리 보유 여부 및 접근 방식에 따라 나뉩니다.
Type 1
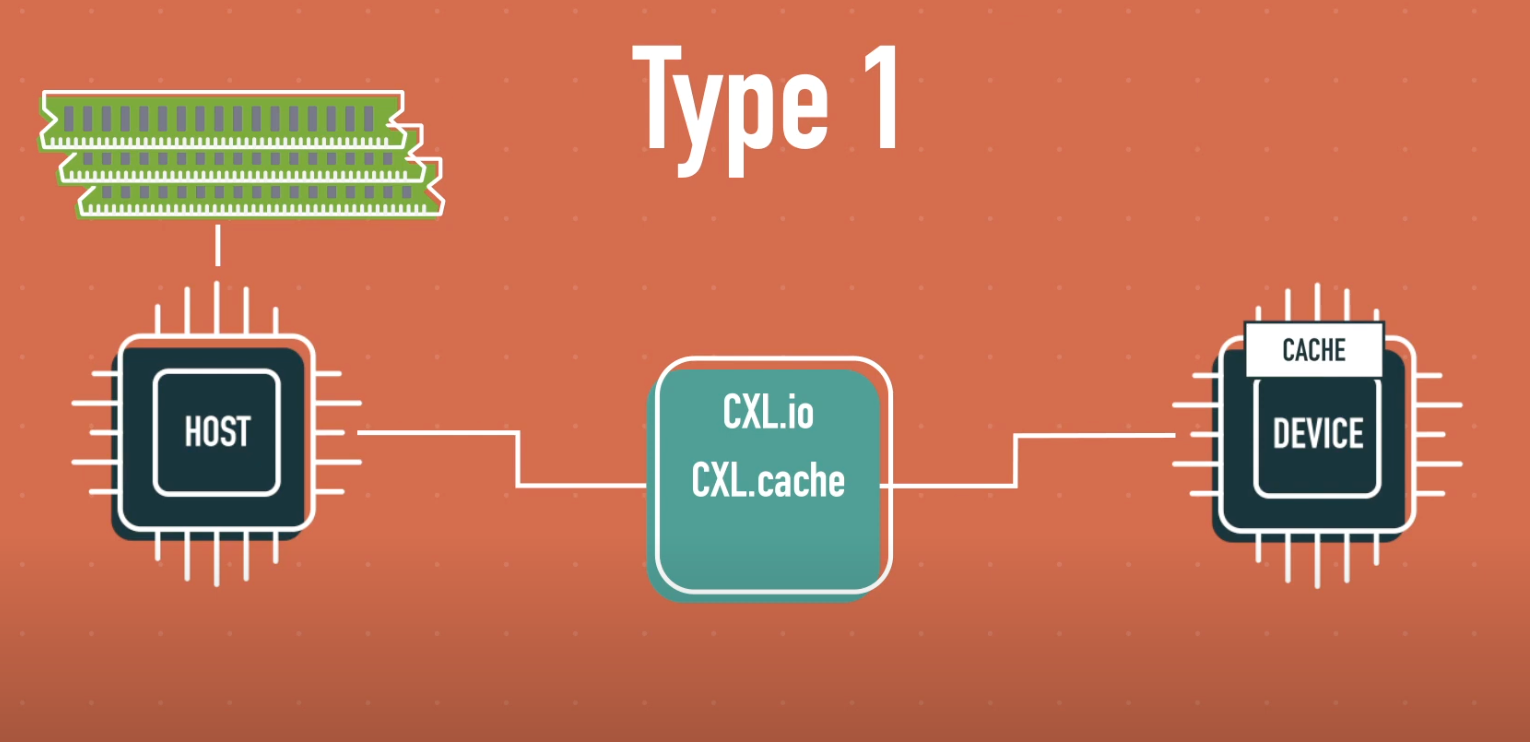
Type 1 장치는 로컬 메모리를 갖지 않은 가속기 또는 네트워크 장치로, 호스트의 메모리를 일관성 있게 접근하여 사용합니다.
대표적인 예로 PGAS NIC이나 NIC Atomics 같은 네트워크 가속기가 있으며, 호스트의 DDR 메모리를 직접 버퍼 풀로 활용하면서도 캐시 일관성을 유지합니다.
Type 2
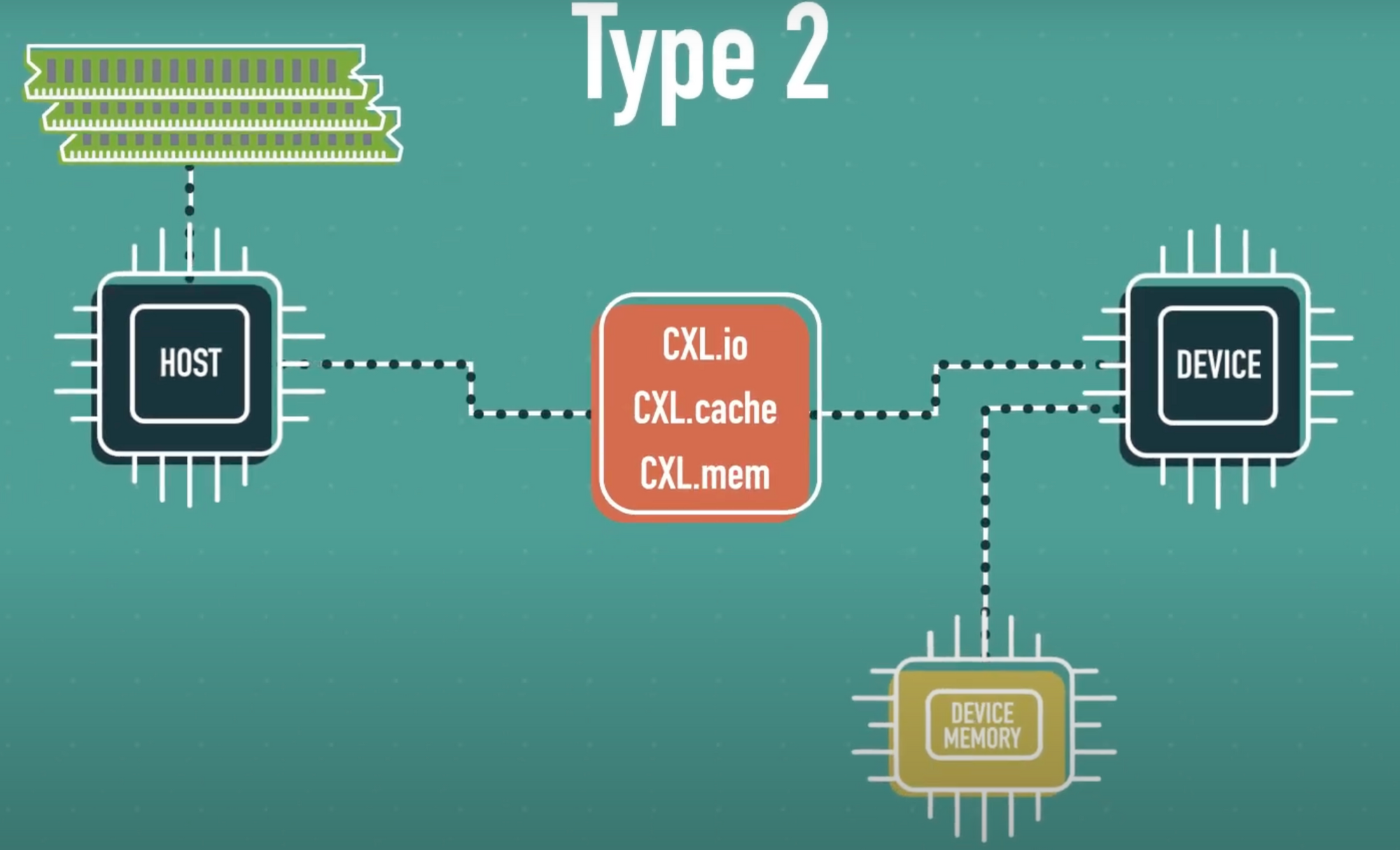
Type 2 장치는 GPU, FPGA, AI ASIC처럼 로컬 고속 메모리(HBM, GDDR 등)를 보유하고 있으며, 호스트의 메모리와 장치 메모리 간 양방향 일관성 접근이 가능합니다.
CPU와 가속기가 동일한 데이터 구조를 공유하고 조작할 수 있어, 시스템 전체의 메모리 공간을 통합된 하나의 구조로 활용할 수 있습니다. 예를 들어, GPU가 호스트 RAM에 있는 데이터를 직접 조작하거나, CPU가 GPU의 HBM에 저장된 모델 파라미터를 직접 읽고 쓸 수 있습니다.
Type 3
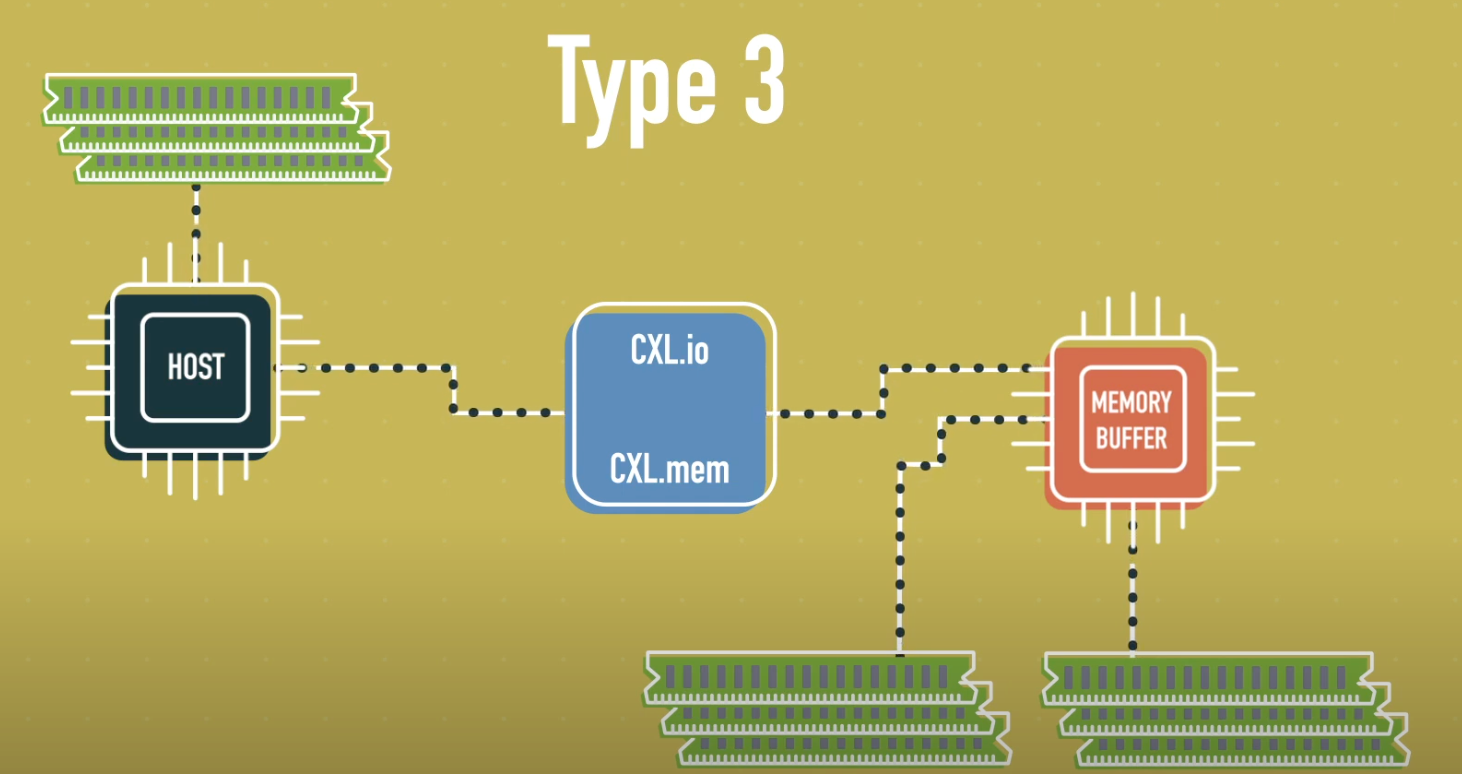
Type 3 장치는 메모리 확장을 위한 용도로 설계된 장치로, 로컬 메모리만 보유하며, 호스트는 해당 메모리를 직접 load/store 방식으로 접근합니다. 반면 장치는 호스트 메모리를 접근할 필요가 없습니다.
주로 DRAM 또는 NVM 기반의 메모리 확장 모듈로 활용되며, 시스템에 메모리 용량과 대역폭을 추가하는 역할을 합니다. 마치 PCIe 기반 메모리 컨트롤러처럼 동작하지만, CXL의 하드웨어 일관성 보장 덕분에 더 낮은 레이턴시 및 간단한 소프트웨어 스택으로 동작합니다.
1.4 CXL vs PCIe
CXL은 PCIe와 동일한 물리 슬롯과 전송 라인을 사용하지만, 작동 방식과 제공 기능 면에서 근본적으로 다릅니다.
PCIe는 장치 초기화, 레지스터 접근, 데이터 전송 등을 위한 표준 인터페이스로 오랫동안 사용되어 왔으나, 캐시 일관성을 지원하지 않습니다. 따라서 CPU와 장치 간의 데이터 공유에는 DMA 엔진이 필요하며, 복잡한 버퍼 복사 및 명시적 캐시 관리가 필수적입니다.
반면 CXL은 하드웨어 수준의 캐시 일관성을 지원합니다. CXL을 사용하는 시스템에서는 가속기나 장치가 CPU 메모리를 직접 접근하고 캐시할 수 있으며, CPU 또한 장치 메모리를 직접 읽고 쓸 수 있다. 모든 접근은 캐시 일관성을 유지한 채 이루어지므로, 프로그래머는 마치 CPU 내부 자원을 다루듯이 장치 메모리를 사용할 수 있습니다.
대역폭 측면에서도 CXL은 PCIe와 동일한 수준의 성능을 제공한다. CXL은 기존 PCIe 인프라를 그대로 활용하면서도, 데이터 일관성, 메모리 공유, 성능 향상 등 다양한 이점을 동시에 제공합니다.
이번 논문에서는 CXL Type 3 장치 유형으로 서버의 메모리를 확장하는 방법을 소개합니다.
2. Memory-Centric 시스템의 필요성
현대 데이터베이스 시스템은 점점 더 많은 데이터를 처리해야 하고, 이를 위해 더 많은 코어와 메모리 리소스가 필요합니다.
하지만 기존 프로세서 중심의 시스템 아키텍처로 이를 만족하기 점점 힘들어졌습니다. 특히, 메모리 대역폭의 병목과 낮은 메모리 활용률은 시스템 효율성과 비용 측면에서 심각한 문제였습니다.
2.1 Processor-Centric 시스템의 한계
지금까지 대부분의 시스템은 Processor-Centric 시스템(CPU 중심)으로 설계되었습니다. 하지만 저자들은 다음의 이유들로 이제 Memory-Centric 시스템을 고려해야한다고 주장합니다.
- 코어 수 증가 vs 정체된 메모리 대역폭
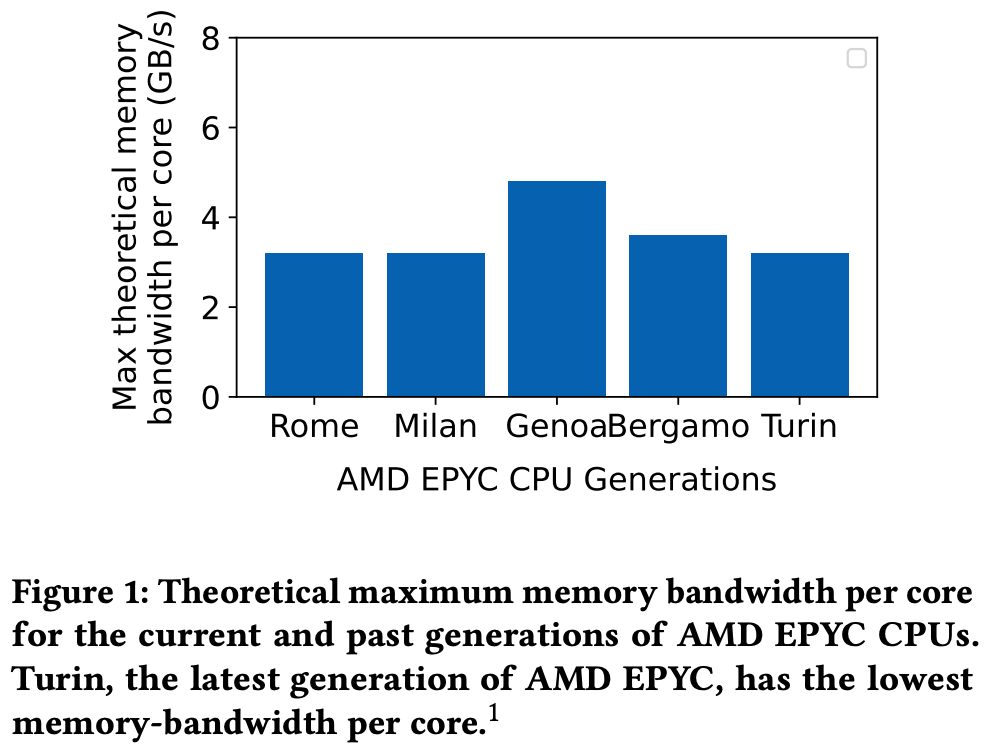
최신 CPU는 더 많은 코어를 탑재하고 있지만, 메모리 대역폭은 그 속도를 따라가지 못하고 있습니다. 이로 인해 memory-bound 작업은 오히려 성능 저하를 겪게 되며, 전체 시스템 리소스의 활용률이 떨어집니다.
2. 메모리의 높은 비용과 낮은 활용률
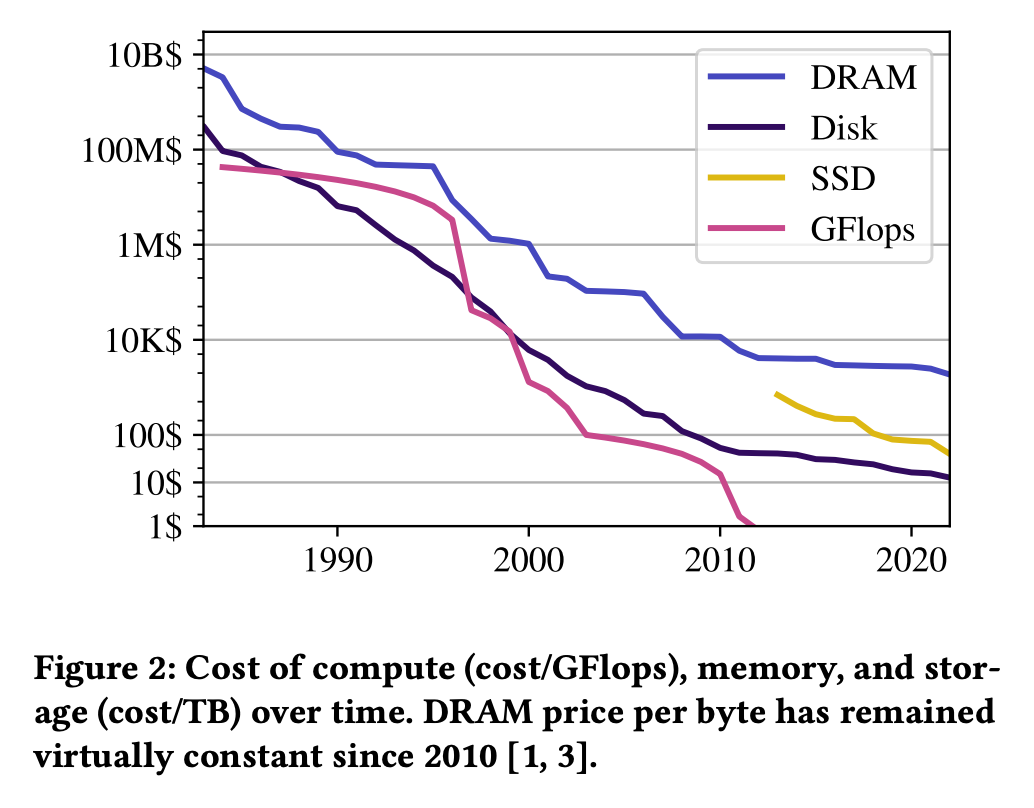
메모리는 이미 서버 비용의 상당 부분을 차지하고 있으며, 바이트당 비용이 더 이상 빠르게 떨어지지 않고 있습니다. 특히 클라우드에서는 vCPU 중심의 리소스 할당 때문에, 메모리는 고정된 상태로 묶여 비효율적으로 사용되고 있습니다. (CPU당 고정된 개수로 묶여서 할당)
2.2 Memory-Centric Computing
이를 극복하기 위한 Memory-Centric Computing의 핵심 아이디어는 다음과 같습니다.
- 메모리를 중심으로 시스템을 재설계
CPU를 중심으로 리소스를 묶는 기존 방식 대신, 메모리 풀(pool)을 중심으로 구성하여 컴퓨팅 파워를 주변 자원으로 취급합니다. CPU, GPU, FPGA 등 다양한 프로세서들이 네트워크를 통해 메모리 풀에 접근하게 됩니다.
2. 메모리가 분리된(disaggregated) 구조로 유연한 확장
로컬 DRAM을 가진 노드를 유연하게 추가함으로써, 메모리 대역폭과 용량을 독립적으로 스케일링합니다.
3. 데이터베이스 시스템에 적합한 구조
데이터베이스는 본래 메모리와 데이터 이동을 효율적으로 관리하고 있으며, out-of-core 알고리즘과 분산 쿼리 처리를 사용합니다. 메모리 풀을 활용하면 더 안정적인 성능 및 간결한 프로그래밍 모델을 사용할 수 있습니다. 특히, CXL(shared memory)과 같은 기술은 메모리 추상화를 단순화시켜 개발 편의성도 높여줍니다.
out of core 알고리즘은 데이터가 메인 메모리에 다 들어가지 않을 때 디스크를 활용해 데이터를 처라하는 알고리즘을 말합니다.
2.3 메모리 기술 병목으로 인한 DBMS 문제
무어의 법칙이 한계에 다다르면서, 칩 제조사들은 성능 향상을 위해 코어 수를 늘리는 방향으로 선회했습니다. 하지만 여전히 core당 메모리 대역폭은 이를 따라가지 못하고 있습니다. 이처럼 프로세서 속도와 메인 메모리 접근 시간 갭이 커지는 현상을 Memory Wall이라고 합니다.
Memory Wall로 인하여 대부분의 어플리케이션, 특히 데이터 중심의 워크로드는 점점 memory-bound가 되어가고 있습니다.
DNN(Deep Nueural Network)과 같은 특정 분야에서는 TPU나 Azure의 Maia 같은 도메인 특화 아키텍처(DSA)로 이를 극복하고 있습니다. 하지만 DBMS는 다양한 기능을 제공하다 보니 Amdahl's Law로 인해 한계가 분명합니다. 파싱, 최적화, 트랜잭션 처리, 디스크/메모리 관리, 네트워크 처리 등 다양한 서브시스템이 얽혀 있으니 DSA가 해결할 수 있는 작업은 일부인 것이죠.
DRAM은 가장 비싼 자원인데도 클라우드 환경에서는 CPU 단위로 고정 할당되어 실제 메모리 사용률이 낮아(Microsoft의 경우 DRAM의 25%만 활용) 자원 낭비로 이어지고 있습니다.
Memory Wall은 단순한 레이턴시 문제가 아니라 대역폭, 용량, 비용이라는 다차원적인 문제로 진화하고 있습니다. 기존 구조로는 이 벽을 넘기 위해 서버 수를 늘려야 하고, 이는 곧 DB 시스템의 스케일링 비용 폭증으로 이어지기 때문입니다.
3. 데이터베이스를 위한 Memory-Centric 아키텍처
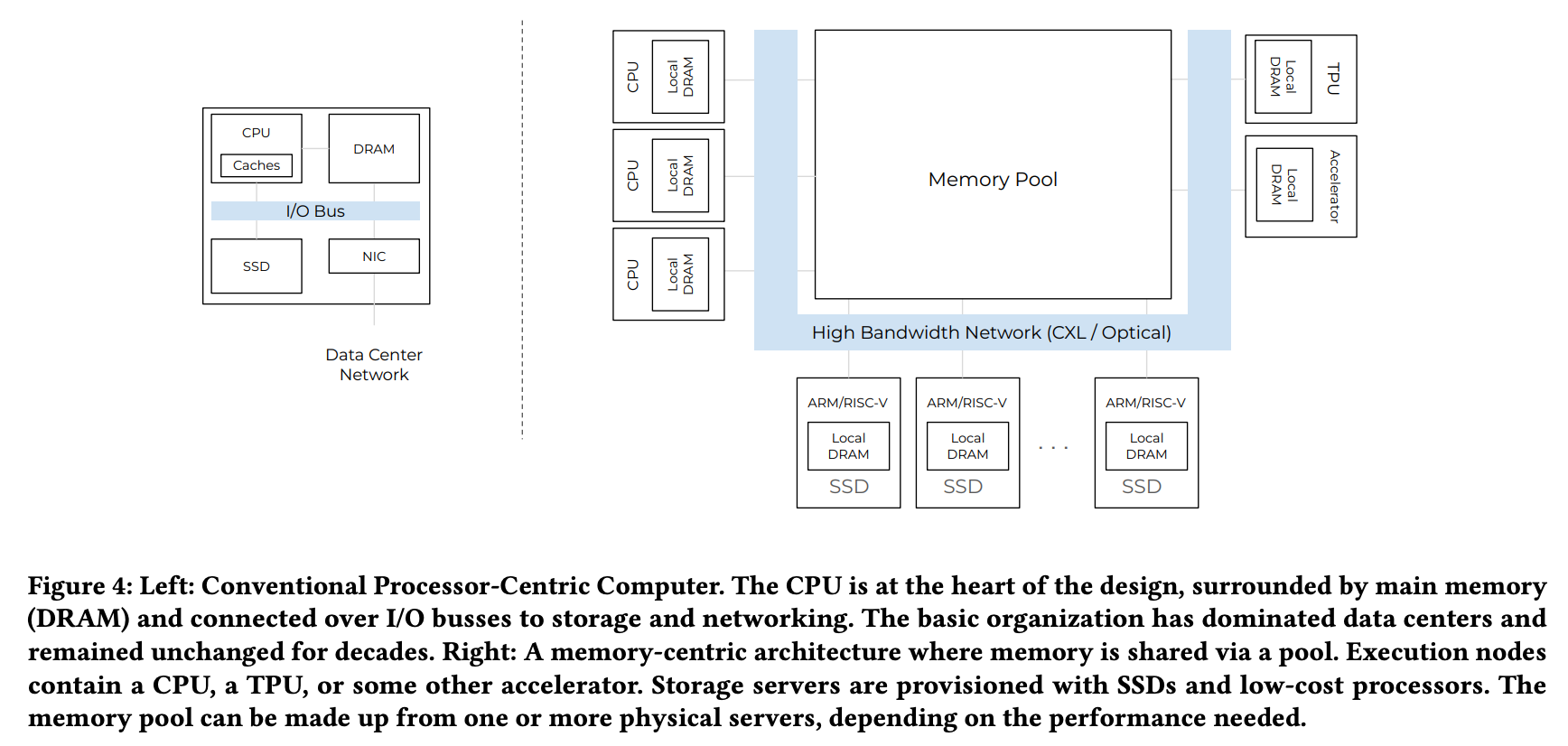
3.1 Memory Pooling
기존 서버 아키텍처에서는 각 CPU 코어가 고정된 메모리를 갖는 방식이 일반적이었습니다. 하지만 Memory-Centric Design 은 다릅니다. 대부분의 메모리가 네트워크를 통해 공유되는 풀(Pool) 형태로 존재하며, 개별 compute 노드는 작은 로컬 DRAM만을 갖고, 실제 데이터는 중앙 메모리 풀에 위치합니다.
메모리 풀은 고성능 프로세서(Figure 4 좌측)뿐 아니라 ARM, RISC-V 같은 저전력 코어(Figure 4 하단), 다양한 하드웨어 가속기들(Figure 4 우측)과 함께 공유될 수 있어 클라우드 환경에서 메모리 낭비(Stranding)를 줄이고 복잡한 워크로드에 대응할 수 있습니다.
애플리케이션 입장에서는 이 메모리 풀을 통해 로컬 DRAM을 보완하거나, 분산 시스템에서 메모리를 분리(disaggregate) 하여 시스템 전체의 메모리 효율성을 높이고, 대용량 데이터 교환을 더 쉽게 처리할 수 있습니다.
예를 들어 Google BigQuery는 분산 메모리 서비스를 기반으로 빠르고 대규모의 shuffle을 수행하고 있으며, Microsoft는 RDMA를 활용해 원격 노드에서 메모리를 빌려 디스크 I/O를 줄이고 있습니다.
메모리 풀은 비용 측면에서도 유리합니다. 하드웨어 세대가 바뀔 때마다 클라우드 업체들은 메모리 수명이 25년 넘는데도 불구하고, 메모리를 교체해왔습니다(ex DDR4 -> DDR5). 메모리를 CPU에 고정시키는 기존 모델에서는 불가피했지만, CXL 기반의 메모리 풀 구조에서는 이전 세대 메모리를 재활용할 수 있어 비용을 크게 아낄 수 있습니다.
3.2 DB와 메모리 풀
대부분의 애플리케이션은 메모리 계층을 직접 다루기 어렵지만, 데이터베이스는 다릅니다. DBMS는 자체적으로 데이터 이동을 제어하고, out-of-core 알고리즘을 통해 메모리 계층 간 최적화합니다. 특히 분산 쿼리 처리에서 워킹 셋(working set)이 로컬 메모리를 넘어서면 성능 저하가 생기는데, 메모리 풀을 사용하면 초과된 데이터를 유연하게 처리할 수 있고, 데이터 분배도 더 단순하게 만들 수 있습니다.
3.3 메모리 풀은 데이터 이동 비용을 줄인다
분산 쿼리에서 가장 큰 비용 중 하나는 데이터 이동입니다. 원격 스토리지에서 데이터를 불러오거나, 노드 간 데이터를 주고받는 데에는 압축, serialization, 버퍼 복사, 포맷 전환 등 다양한 오버헤드가 수반됩니다.
스토리지 레이어를 사용하는 대신 메모리 풀을 사용하면 이러한 과정을 네트워크 접근 수준으로 단순화할 수 있습니다. 특히 CXL 등의 기술로 데이터 이동 구현을 단순하게 만들 수 있습니다.
현대 데이터 파이프라인은 CPU, GPU, TPU 등 다양한 장치가 관여합니다. 기존에는 각 장치의 로컬 메모리 한계로 인해 데이터 복사와 이동이 병목이 되었지만, memory-centric 디자인에서는 모든 연산 장치가 메모리 풀을 통해 같은 거리에서 데이터를 접근합니다(Figure 4 참고). 이를 통해 서로 다른 종류의 연산 장치 간 데이터 공유를 단순화하고, 메모리 크기 차이로 인한 병목을 줄일 수 있습니다.
4. memory-centric 시스템 사용 예시: Distributed Join
해당 논문에서는 분산 환경에서 자주 사용되는 equi-join을 processor-centric 환경에서 수행할 때와 memory-centric 환경에서 수행했을 때 걸리는 시간 및 자원을 비교하였습니다.
equi-join을 간단하게 SQL 문으로 표현하면 아래와 같습니다.
SELECT *
FROM table1
JOIN table2
ON table1.common_column = table2.common_column;실험에는 R(20GB)과 S(100GB) 두 개의 테이블을 사용했고, 두 테이블 모두 분산 스토리지에 저장되어 있습니다.
상대적으로 작은 크기의 R을 이용해 해시 테이블을 만들고, 해시 테이블의 join key로 S의 row들을 순회하여 매치하여 join을 수행합니다.
실험 조건
- compute 노드 수: 10개
- 네트워크 대역폭: 200 Gbit RDMA (25 GB/s)
- 로컬 DRAM 대역폭: 100 GB/s
- CXL Memory Pool: Memory-Centric 구조에서만 사용
- DRAM Join 연산 처리 속도: 8 GB/s
- CXL 메모리 Join 연산 처리 속도: 5 GB/s
실험 시나리오
- 분산 스토리지에서 R과 S를 fetch
2. 두 테이블을 파티셔닝하여 compute 노드에 배치
3. R의 각 파티션에 대해 해시 테이블 생성
4. S의 각 튜플에 대해 해시 테이블을 탐색(probe)
4.1 Processor-Centric 구조에서 Join 성능
- 파티셔닝: 10개의 compute 노드가 R을 파티션하여 2GB씩 가집니다. 걸리는 시간은 2GB/100GB = 0.02s
2. 셔플링: 2GB 중 0.2GB만 남기고 나머지 데이터는 다른 노드로 셔플링합니다. 걸리는 시간은 1.8GB/25GB = 0.072s
3. 데이터 분산이 skew되어 서버 1이 테이블 R중 5GB 파티션을 가지고 서버 2는 2GB, 나머지 서버들은 각각 1.625GB를가진다고 가정합니다.
4. 해시 테이블을 만드는 시간: 5GB/8GB = 0.625s (가장 큰 파티션을 가진 서버1에 의해 결정)
5. S를 probing 하는 시간: 10GB/8GB = 1.25s
총 걸리는 시간은 0.092 + 0.625 + 1.25 = 1.967s 입니다.
필요한 메모리는 10개의 노드에 대해 각각 5.5GB(가장 큰 R 파티션 5GB + 추가 버퍼 0.5GB) 필요하므로 55GB입니다.
4.2 Memory-Centric 구조에서 Join 성능
Processor-centric과 동일하게 10개의 노드를 가정합니다. 하지만 3GB의 로컬 메모리를 가지고 있고, 메모리 풀 서버가 CXL로 연결되어 있다고 합시다.
- 파티셔닝: 4.1과 비슷하게 0.092s
- 데이터 skew가 되었을 때 서버 1에 할당되는 R 파티션 5GB를 3GB의 로컬 메모리로 저장할 수 없습니다. 그래서 서버 1은 CXL 메모리 2.5GB를 빌려 R 해시테이블을 저장합니다
- 해시테이블 생성 시간(working set 절반은 로컬 메모리, 절반은 CXL 메모리 처리): 2.5GB/8GB + 2.5GB/5GB = 0.8125s
- Probe 시간(절반은 로컬 메모리, 절반은 CXL 메모리 접근): 5GB/8GB + 5GB/5GB = 1.625s
총 걸리는 시간은 0.092 + 0.8125 + 1.625 = 2.5295s 입니다.
필요한 메모리는 10개의 노드에 대해 각각 3GB + 메모리 풀(2.5GB) = 32.5GB 입니다.
5. 마무리
4.1, 4.2를 비교하면 Memory-Centric 구조는 20% 정도의 시간을 희생하지만 사용하는 메모리를 약 70% 정도 아꼈습니다. 성능은 약간 손해보더라도 클라우드 환경 및 대규모 데이터 처리 환경에서는 더 안정적일 수 있습니다.
실제 배포되는 서비스들이 일시적인 메모리 스파이크를 막기 위해 보통 사용되는 메모리 대비 훨씬 많은 메모리를 미리 할당하는 것을 생각하면 이처럼 메모리 풀을 이용하는 것이 훨씬 경제적일 것입니다.
이 논문에서 Memory-Centric 구조는 여러 방법으로 구현될 수 있으며 메모리 풀은 구현 방법 중 하나라고 말합니다. 앞으로 후속 연구가 진행되면 이보다 더 발전된 설계가 나올 것이라 기대하게 되었습니다.
이 논문을 살펴보면서 생각보다 Memory-Centric 설계가 빠르게 보급될 수도 있겠다는 생각이 들었습니다. 논문에서도 언급되었지만, Memory-Centric 설계는 논리적으로 기존 Processor-Centric 설계의 컴포넌트를 재배치한 것입니다. 새로운 컴포넌트가 추가된 것이 아니기 때문에 기업의 입장에서 설계 변경시 비용 부담이 덜할 수 있습니다.
물론 제대로 이를 활용하려면 논문에서도 여러번 언급되었던 CXL 같은 기술들이 데이터 센터에 적용되어야 할 것입니다. 글로벌 클라우드 업체들이 논문에서 나온 것처럼 CXL 적용으로 비용을 줄일 수 있다는 것을 확인한다면 생각보다 빠르게 퍼질 수 있다는 생각이 들었습니다.
앞으로 후속 논문들을 지켜보면서 해당 아키텍처가 어떻게 더 발전할지, 그리고 어플리케이션 개발자는 이를 어떻게 반영해야할 지 고민을 계속 해볼 것 같습니다.
Reference
Databases in the Era of Memory-Centric Computing (2025)