
평범한 개발자들을 위한 LLM 에이전트 프레임워크 가이드

사방에서 AI와 LLM에 대한 얘기가 나오는 요즘입니다.
LLM을 잘 사용하기 위해 LLM 모델을 공부하거나 서빙을 공부할 필요성은 점점 줄어들 거라 생각합니다. LLM API를 제공하는 서비스들은 점점 많아지고 있고 그 가격도 시간이 갈수록 떨어지고 있으니까요.
기업들도 LLM 모델을 공개하는 것을 넘어 AI를 활용한 서비스들을 내놓고 있습니다. AI 에이전트는 그 중 하나로 AI를 활용해 유저 대신 업무를 수행하는 소프트웨어 시스템을 말합니다. 예로는 최근에 충격을 안겨주었던 Manus 등이 있습니다.
이번 글에서는 LLM을 활용한 에이전트에 대해서 다룹니다. 언론에서 얘기하는 AI 에이전트는 시스템 단위의 큰 개념이지만 이번 글은 그 시스템을 구성하는 아주 작은 단위의 에이전트를 얘기하고자 합니다.
먼저 간단한 서베이 논문을 살펴보며 LLM 에이전트에 대한 개념을 잡을 것입니다. 이후 메타에서 발표한 LLM 에이전트를 활용한 테스트 생성 시스템을 살펴봅니다. 마지막으로 여러 LLM 에이전트를 다루는 프레임워크들을 살펴보고 필자가 이를 활용하는 방식을 얘기할 것입니다.
1. LLM 에이전트 동향
A Survey on Large Language Model based Autonomous Agents 의 내용을 기반으로 정리하였습니다.
이 논문에서는 LLM 에이전트를 LLM based Autonomous Agent(LLM 기반 자율 에이전트)로 얘기하지만 이 글에서는 통일성을 위해 LLM 에이전트로 용어를 대신 사용하겠습니다.
해당 페이퍼에서는 두 가지 문제에 초점을 맞추어 에이전트 연구 동향을 정리하였습니다.
- LLM을 더 잘 쓰기 위해 어떻게 에이전트 아키텍처를 디자인하였나
- 다른 태스크들을 수행하기 위해 에이전트의 능력을 어떻게 향상시켰나
차례대로 두 관점으로 정리를 해보겠습니다.
1.1 에이전트 아키텍처 디자인
LLM은 발전을 통해 Question - Answer 형식의 다양한 작업을 할 수 있게 되었습니다.
하지만 우리가 이야기하고자 하는 LLM 에이전트는 LLM이 잘하는 Question - Answer 문제와는 거리가 멉니다. 에이전트는 사람처럼 주변의 환경을 인식 및 배우고 그를 통해 특정 역할을 수행해야 합니다.
기존 LLM이 에이전트의 역할을 수행하려면 아키텍처를 잘 설계하여 LLM의 기능을 극대화하는 것이 중요합니다. 기존 연구들은 LLM의 기능을 향상시키기 위해 다양한 모듈들을 발전시켜왔습니다.
이 논문에서는 이런 연구들을 통합하여 에이전트 아키텍처 설계를 위한 프레임워크를 제시했습니다.
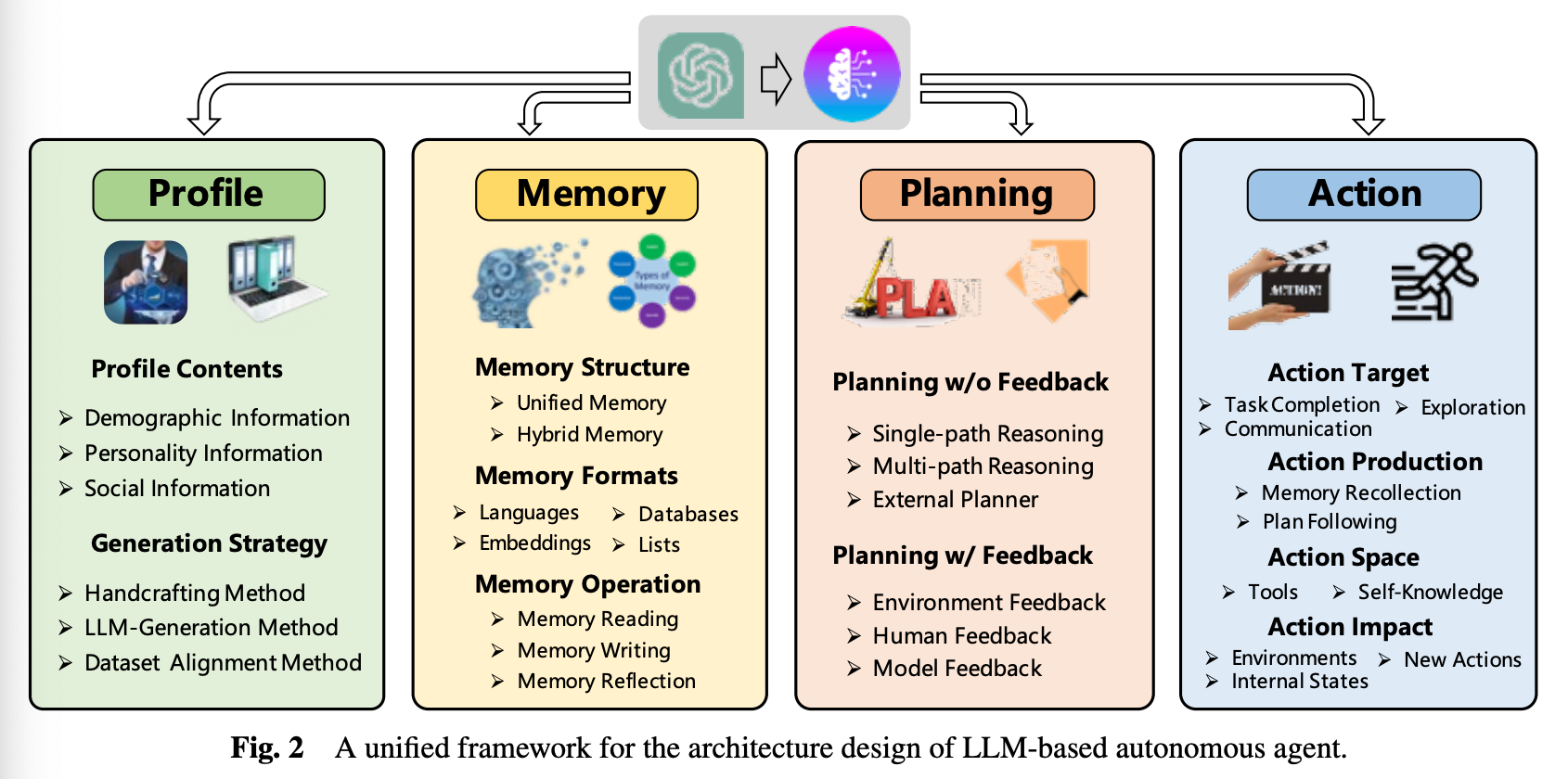
이 프레임워크에서는 모듈을 4가지로 분류합니다.
- profiling: 에이전트의 역할 파악
- memory: 에이전트의 지난 행동을 기억
- planning: 미래 행동을 계획
- action: 에이전트의 결정을 아웃풋으로 변환
쉽게 말해 에이전트가 사람처럼 동작하려면 위 4가지 모듈이 전부 필요합니다.
각 모듈들이 어떤 역할을 하는지 간단히 알아보겠습니다.
1.1.1 Profiling module
어떤 에이전트 역할의 프로필을 지정해주는 역할을 합니다.
나이, 성별, 커리어, 성격 등을 지정하거나 에이전트 간 소셜 정보등을 가지기도 합니다.
예를 들어 에이전트 프로필에 “너는 활발한 사람이야” 등을 적어두고 에이전트의 LLM 실행시 프롬프트에 이를 포함하는 방식입니다.
보통 프로필은 사람이 직접 정의하는 경우가 많지만 사람이 다 지정해주기 힘들 경우에는 LLM이 프로필을 생성하도록 하거나 실제 데이터 세트에 있는 사람의 정보를 프롬프트로 적는 경우도 있습니다.
1.1.2 Memory Module
메모리는 short term 메모리와 long term 메모리로 나눌 수 있습니다.
short term 메모리는 트랜스포머 아키텍처의 context window 내 인풋 메모리를 사용하는 것이고 long term 메모리는 외부 벡터 스토리지를 사용하는 것이라 생각하면 됩니다.
short term 메모리만 사용하는 경우 LLM 프롬프트로 모든 상태가 서빙됩니다. 그렇기 때문에 메모리가 LLM의 컨텍스트 윈도우에 의해 제한되는 단점이 있습니다.
Long term 메모리는 자주 사용되지 않는 기억으로 벡터 DB에 저장하고 필요할 때 검색하여 사용합니다. 예를 들어 에이전트가 현재 상황에 대한 컨텍스트는 프롬프트에 담고, 이전에 했던 행동은 벡터 DB에 담는 경우가 있겠습니다.
에이전트가 환경과 상호작용을 하려면 메모리를 잘 활용하는 것이 중요합니다. 에이전트가 메모리를 다루는 방법은 읽기, 쓰기, 반영(reflection) 3가지로 분류할 수 있습니다.
읽기의 경우 메모리가 최신일수록, 요청과 연관이 높을수록, 중요할 수록 추출이 더 잘되어야 합니다. 연관도의 경우 LSH, HNSW 등의 벡터 검색 알고리즘을 활용하는 ANNOY, FAISS 등을 사용해서 적용합니다. 중요도의 경우 메모리 자체의 성격을 반영합니다. 대부분의 연구에서는 아직 연관도만 반영합니다.
쓰기의 경우 에이전트가 자각하는 환경에 대한 정보를 메모리에 저장하는 것입니다. 여기서 중복된 정보를 어떻게 저장할지, 저장 공간이 부족할 때 어떤 메모리를 지울지가 문제가 됩니다. 메모리 중복 해결은 비슷한 메모리를 모아 일정 크기 이상이 되면 합치고 정제하는 방식으로 해결할 수 있습니다. 저장 용량 초과는 유저 커맨드로 지우게 하거나(ChatDB), FIFO를 사용하는 경우도 있습니다(RET-LLM)
반영(reflection)은 에이전트가 독립적으로 요약하고 추론할 수 있는 능력을 부여하는 것입니다. 예를 들어 Generative Agent의 경우 과거 경험을 추상화된 인사이트로 요약합니다. 이때 순차적으로 최근 메모리에 기반한 3가지 질문을 생성하고 이 질문으로 메모리로부터 정보를 추출합니다. 그리고 이 정보들로 에이전트는 다시 5개의 인사이트를 생성합니다.
에이전트에게 메모리 모듈을 부여함으로써 에이전트는 동적인 환경에서 task를 배우고 완료할 수 있습니다.
1.1.3 Planning Module
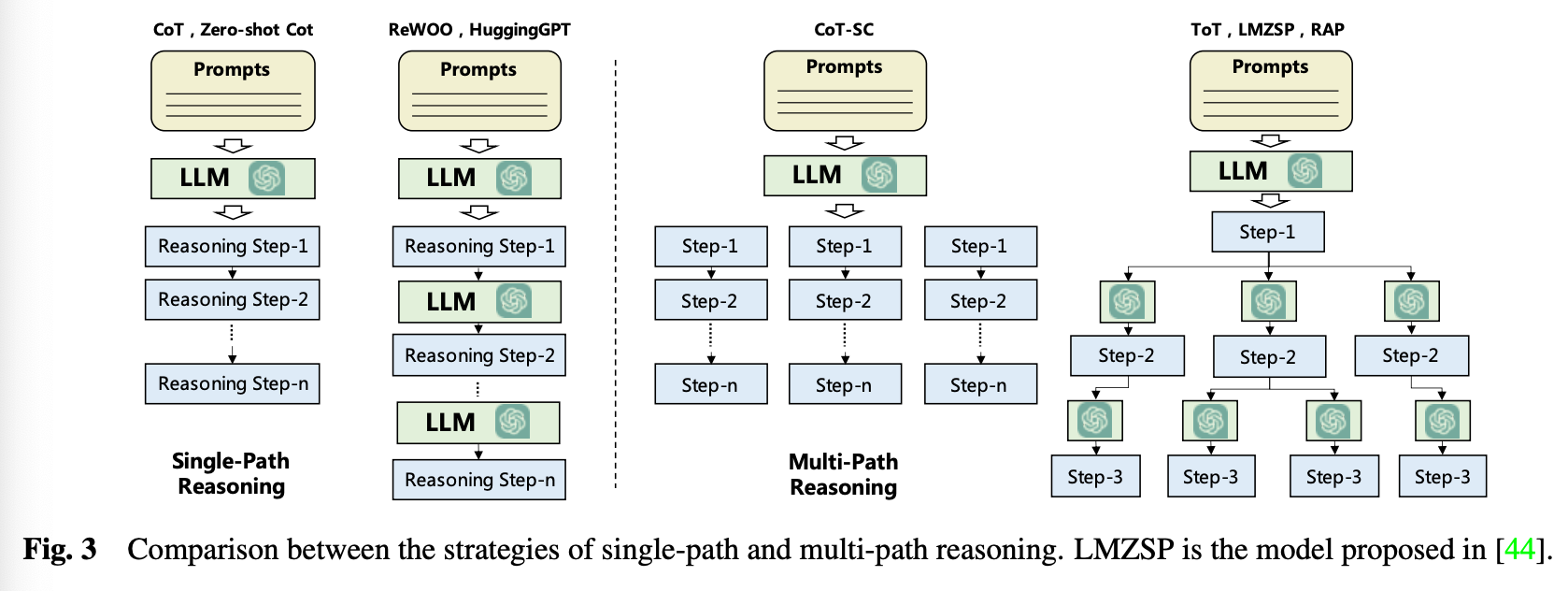
사람이 업무를 단순한 하위 업무로 나누어 푸는 것처럼 Planning Module도 비슷한 역할을 합니다.
Planning은 피드백을 받는 것과 받지 않는 것으로 종류를 구분할 수 있습니다.
위 그림(Fig 3)은 전부 피드백을 받지 않는 Planning 입니다.
Single Path Reasoning은 CoT(Chain of Thought)로 프롬프트에 예제 등을 넣어줘 LLM이 여러 단계로 업무를 나누어 풀게합니다.
Multi Path Reasoning은 각 중간 단계마다 여러 답변을 생성합니다. Self consistent CoT(CoT-SC)는 여러 개의 CoT들로부터 답변을 받고 가장 나은 답변을 선택하고, ToT(Tree of Thoughts)는 각각의 노드가 다시 스스로 플랜을 만들어냅니다.
피드백을 받는 경우는 에이전트가 플랜을 따라 수행한 뒤 피드백을 받을 수 있도록 합니다.
ReAct의 경우 검색 엔진 등으로 수행 뒤에 피드백을 받고, Voyager는 생성한 프로그램을 실행하여 발생한 에러를 통해 피드백을 받습니다. 학습된 모델을 평가자로 사용해 피드백을 주는 경우도 있습니다.
1.1.4 Action Module
액션은 목표(goal), 수행(production), 배경(space), 효과(impact) 4개로 나눌 수 있습니다.
액션의 목표에는 특정한 업무를 수행하거나 다른 에이전트 혹은 사용자에게 정보 공유 그리고 익숙하지 않은 환경 탐색 등이 있습니다.
수행은 에이전트 메모리로부터 정보를 추출하여 수행하는 것과 전달받은 계획에 의해 수행하는 방식이 있습니다. 예를 들어 이전에 비슷한 업무가 있었으면 이전 수행 방식을 그대로 적용하고 없다면 계획에 따라 수행하는 전략이 있을 수 있습니다.
배경(space)은 외부 도구와 LLM 내재 지식으로 구분할 수 있습니다. 외부 도구는 API, 데이터베이스, 외부 모델 등을 말합니다.
효과(impact)는 주변 환경 상태 변경(게임에서 이동하거나 아이템 수집 등), 에이전트 상태 변경(메모리 업데이트, 계획 세우기), 새로운 액션을 발생(게임에서 필요한 자원을 다 모으면 건물을 짓기) 등이 있습니다.
1.2 에이전트 능력 향상
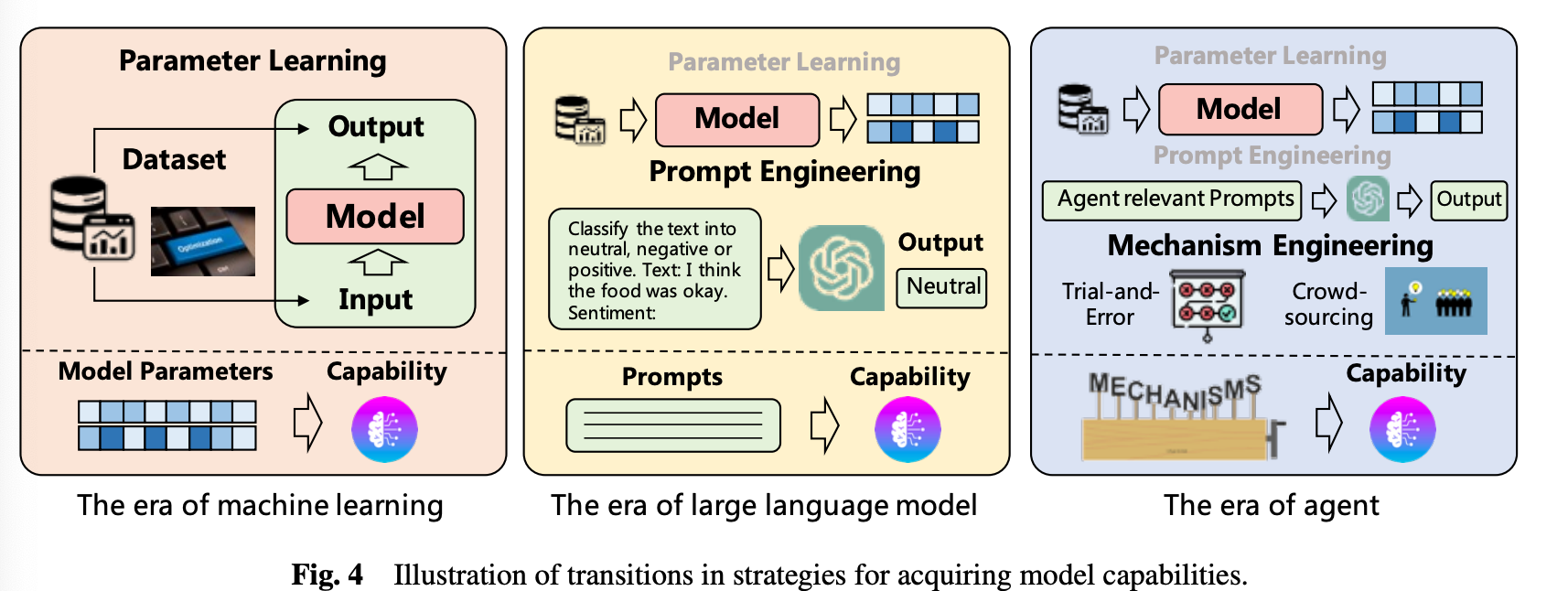
위 그림을 보면 시대에 따라 모델의 능력을 강화하는 방법이 추가되었습니다.
전통적인 머신러닝에서는 데이터를 모델의 파라미터로 녹이는 파인 튜닝 방법이 주로 사용되었습니다. LLM 시대에 들어오면서 데이터를 직접 학습시키지 않고 프롬프트 엔지니어링을 활용해 LLM의 능력을 키울 수 있었습니다.
에이전트 시대에는 위 두가지 방법에 더해 메커니즘 엔지니어링이 추가되었습니다.
메커니즘 엔지니어링의 종류 일부를 소개해보겠습니다
(1) Trial-and-error: 에이전트가 액션을 먼저 해보고 피드백을 받습니다.
(2) Crowd sourcing: 다른 에이전트들과 함께 주어진 문제에 대해 답변을 생성한다. 만약 에이전트들의 답변이 일치하지 않으면 다른 에이전트의 답변을 포함해 다시 응답을 한다. 최종 일치되는 답이 나올 때까지 이를 반복한다. 이 방법을 수행하려면 각 에이전트들이 다른 에이전트들의 답변을 이해하고 합칠 수 있어야 합니다.
(3) 경험 축적: GITM(Ghost in the Minecraft)는 에이전트가 탐험을 하면서 성공한 액션들을 메모리에 저장합니다. 이후 비슷한 업무를 만나면 성공했던 액션을 가져와 해결합니다.
(4) Self-driven Evolution: 보상 함수를 설정하거나 멀티 에이전트 시스템에 피드백을 주는 LLM을 통합함으로써 피드백을 주고받으며 스스로 발전을 할 수 있도록 합니다.
2. Meta에서 Agent를 사용하여 만든 테스트 생성기
LLM 에이전트에 대해 간단히 알아보았습니다. 그러면 LLM 에이전트를 사용해 어떤 서비스를 만들 수 있을까요?
메타는 LLM 에이전트를 활용해 Mutation(돌연변이) 테스트 생성기를 만든 사례를 테크 블로그에 공유했습니다.
Mutation 테스트는 현재 갖추어진 테스트 코드들이 소스 코드가 변경되었을 때 잘못된 점을 얼마나 감지할 수 있는지 확인하는 것이 목적입니다. 그래서 소스 코드를 일부 변경해 mutation을 생성하고 테스트 코드가 이를 감지하는지 측정합니다.
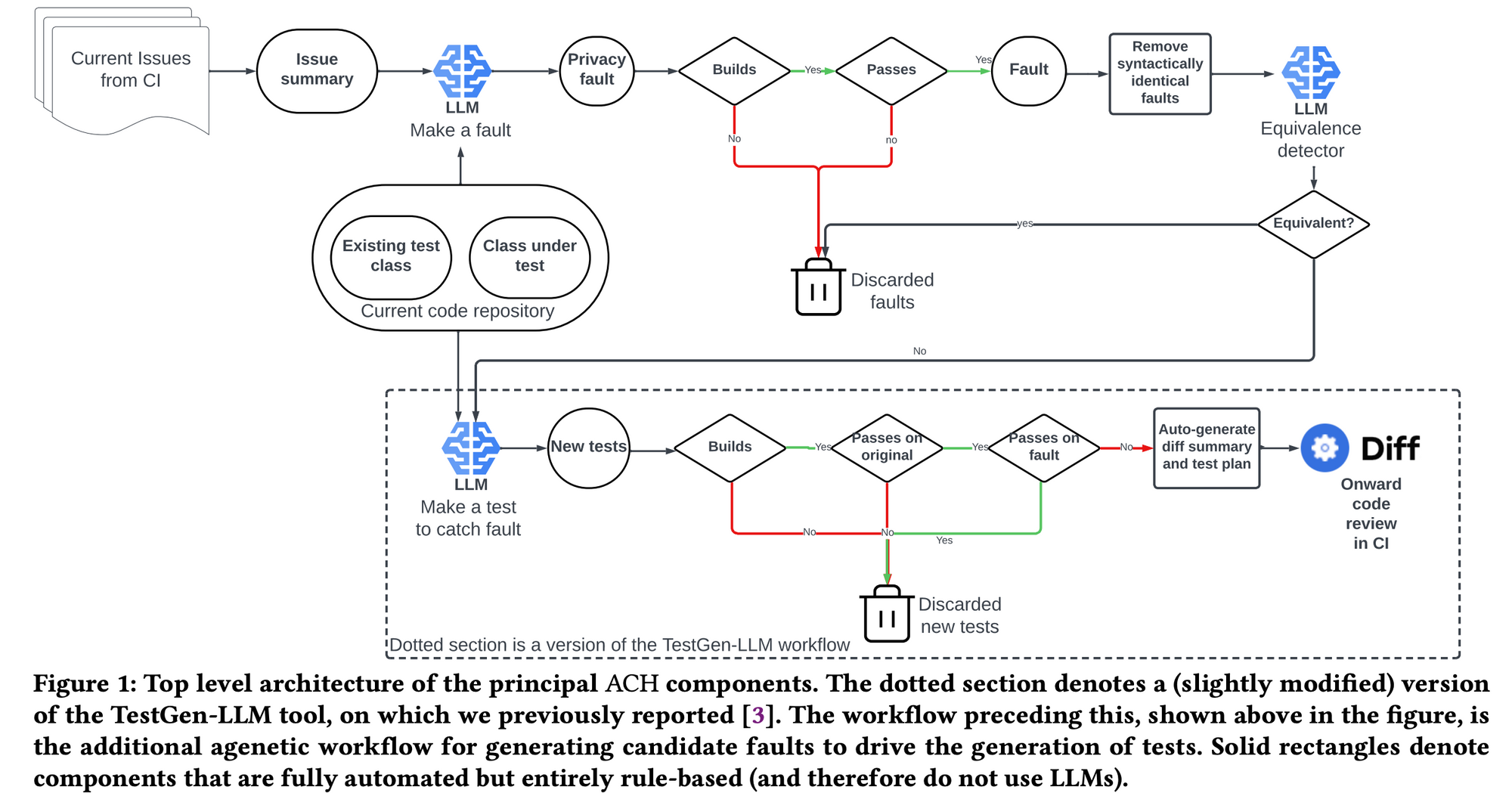
메타는 mutant를 생성하는 시스템을 만들었고 이를 ACH(Automated Compliance Hardening)이라 소개했습니다.
ACH의 컴포넌트들을 잘 보면 중간에 LLM이 들어가있는 것을 볼 수 있습니다.
ACH에는 총 3개의 LLM 컴포넌트가 있습니다.
- Make a fault: mutant를 생성합니다
- Equivalence detector: 생성한 mutant가 논리적으로 기존의 코드와 같으면 폐기합니다
- Make a test to catch fault: 생성한 mutant를 감지할 수 있는 테스트를 생성합니다
이 컴포넌트들은 일종의 LLM 에이전트라고 할 수 있습니다. 논문을 보면 이 LLM 에이전트들에 사용한 프롬프트들을 확인할 수 있습니다.

ACH는 mutant를 생성하는 AI 에이전트 서비스라고 할 수 있고, ACH의 핵심 구성 요소로 3개의 LLM 에이전트가 있는 것입니다.
생각보다 구조가 간단하지 않나요?
3. 멀티 에이전트 프레임워크 소개: MetaGPT, Autogen
하나의 LLM 에이전트로 일을 수행하는 것보다 여러 에이전트가 협력하여 일을 수행하는 것이 훨씬 더 정확합니다. 앞서 “1. LLM 에이전트의 동향”에서 에이전트의 성능을 향상시키는 방법으로 에이전트끼리 피드백을 주고 받는 방식을 소개해드린 바 있습니다.
이를 위해 개발자들이 여러 LLM 에이전트를 관리할 수 있도록 도와주는 프레임워크들이 있습니다. 그 중 MetaGPT와 Autogen을 소개하고자 합니다.
3.1 MetaGPT
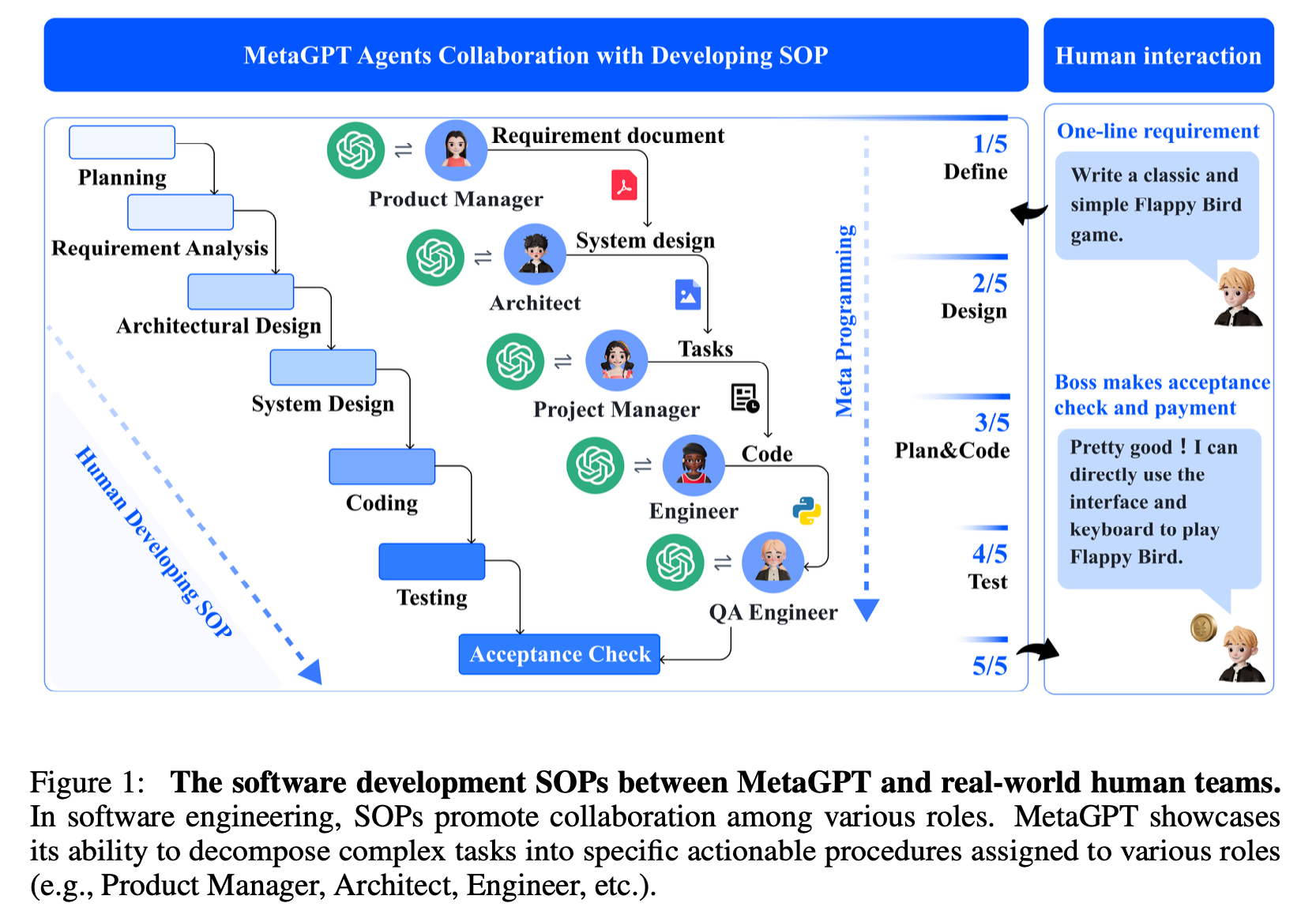
MetaGPT는 에이전트들에 역할을 분배하는 방식을 취하고 있습니다.
예를 들어 Figure 1을 보면 각 에이전트가 Product Manager, Architect, Project Manager, Enginner, QA Enginner의 역할을 맡고 있고 이는 소프트웨어 회사의 직군을 그대로 가져온 것입니다.
에이전트를 통해 소프트웨어를 만드는 것이 목적이니 실제 소프트웨어 회사의 구조를 그대로 가져온 것이죠.
import asyncio
from metagpt.roles import (
Architect,
Engineer,
ProductManager,
ProjectManager,
)
from metagpt.team import Team위처럼 MetaGPT에서 정의해놓은 역할을 사용하여 에이전트를 정의할 수 있습니다. 물론 역할을 직접 정의할 수도 있습니다.
class SimpleCoder(Role):
name: str = "Alice"
profile: str = "SimpleCoder"
def __init__(self, **kwargs):
super().__init__(**kwargs)
self._watch([UserRequirement])
self.set_actions([SimpleWriteCode])다시 Figure 1으로 돌아오면 실제 동작은 아래 Figure 2와 같은 방식으로 이루어집니다.
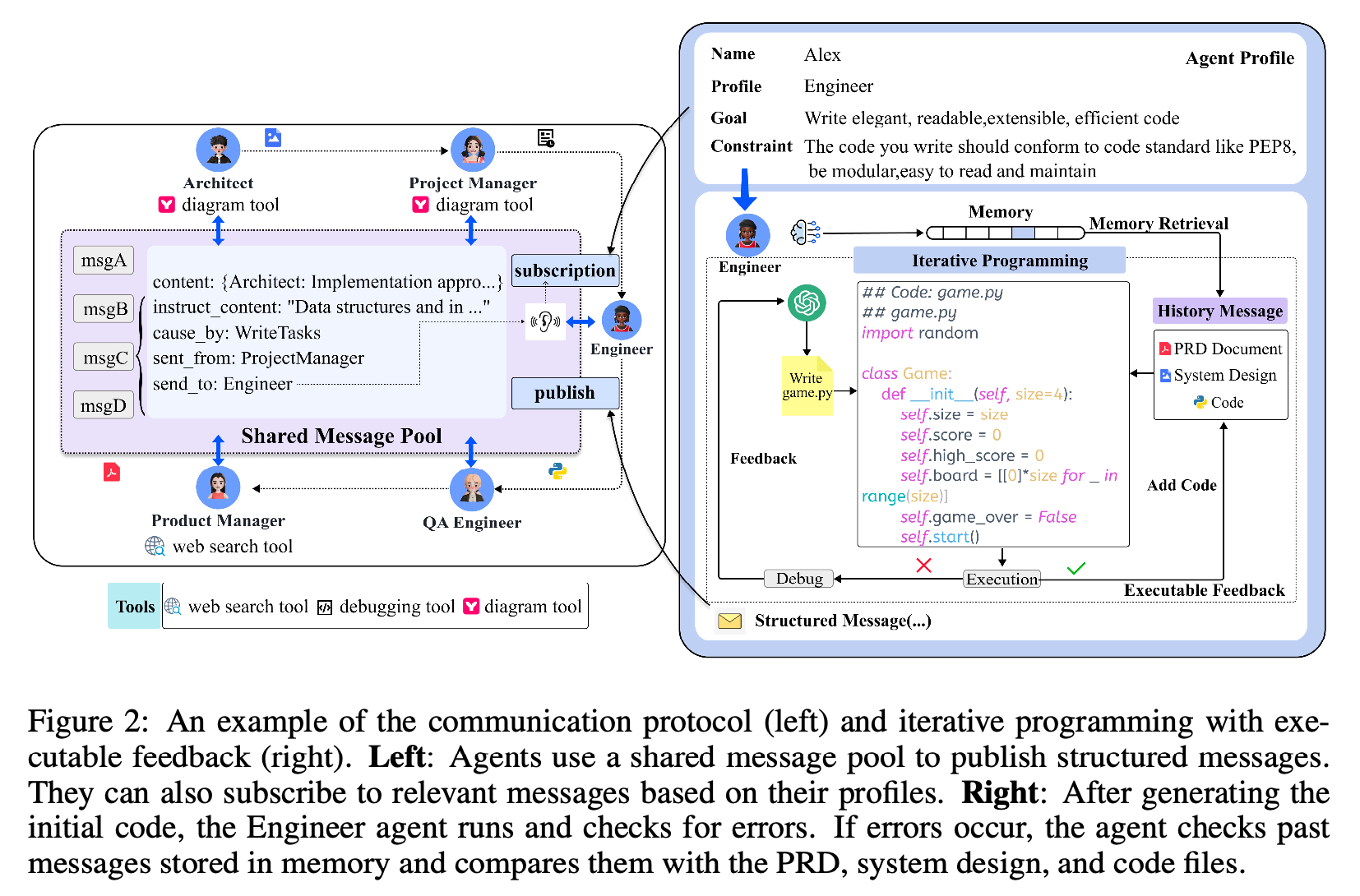
큰 흐름은 Architect가 시스템 디자인 컴포넌트를 구체화, Product Manager가 시스템 디자인으로부터 업무를 분배, Engineer는 클래스와 함수를 구현하는 단계가 순차적으로 수행됩니다.
이때 에이전트간 통신은 공유 메시지 풀을 통해 수행됩니다. 각 에이전트가 본인의 정보를 따로 저장하고 모르는게 생길 때마다 다른 에이전트에게 물어보는 방식은 비효율적일 것입니다. MetaGPT는 각 에이전트가 메시지 풀에 정보를 publish/subscribe 하는 방식이며 다른 에이전트에게 직접 정보를 가져오지 않습니다.
3.2 Autogen
Autogen은 마이크로소프트에서 만든 멀티 에이전트 프레임워크입니다.
큰 틀에서 MetaGPT와 크게 다르지 않으나 에이전트의 역할을 구별하는 방식이 조금 다릅니다.
예를 들어 MetaGPT의 역할은 추상화가 되어 Architect, Product Manager, Engineer 등을 지원합니다. Autogen은 조금 더 낮은 레벨에서 UserProxyAgent(유저의 입력을 전달하는 에이전트), WebSurfer(웹을 검색하는 에이전트), CodeExecution(코드 실행 에이전트) 역할을 지원합니다. 즉 프레임워크에서 주로 지원하는 추상화의 정도가 조금 다르다고 할 수 있습니다.
Autogen을 통해 직접 여러 에이전트들을 구성하여 멀티 에이전트 시스템을 만들 수도 있지만, Autogen이 지원하는 Magentic-One을 사용할 수도 있습니다. Magentic-One은 Autogen이 정의한 멀티 에이전트 팀이고 파일 탐색, 웹 검색, 코딩, 코드 실행 등을 수행할 수 있습니다. Magentic-One의 내부 구현은 당연히 Autogen을 사용한 것입니다.
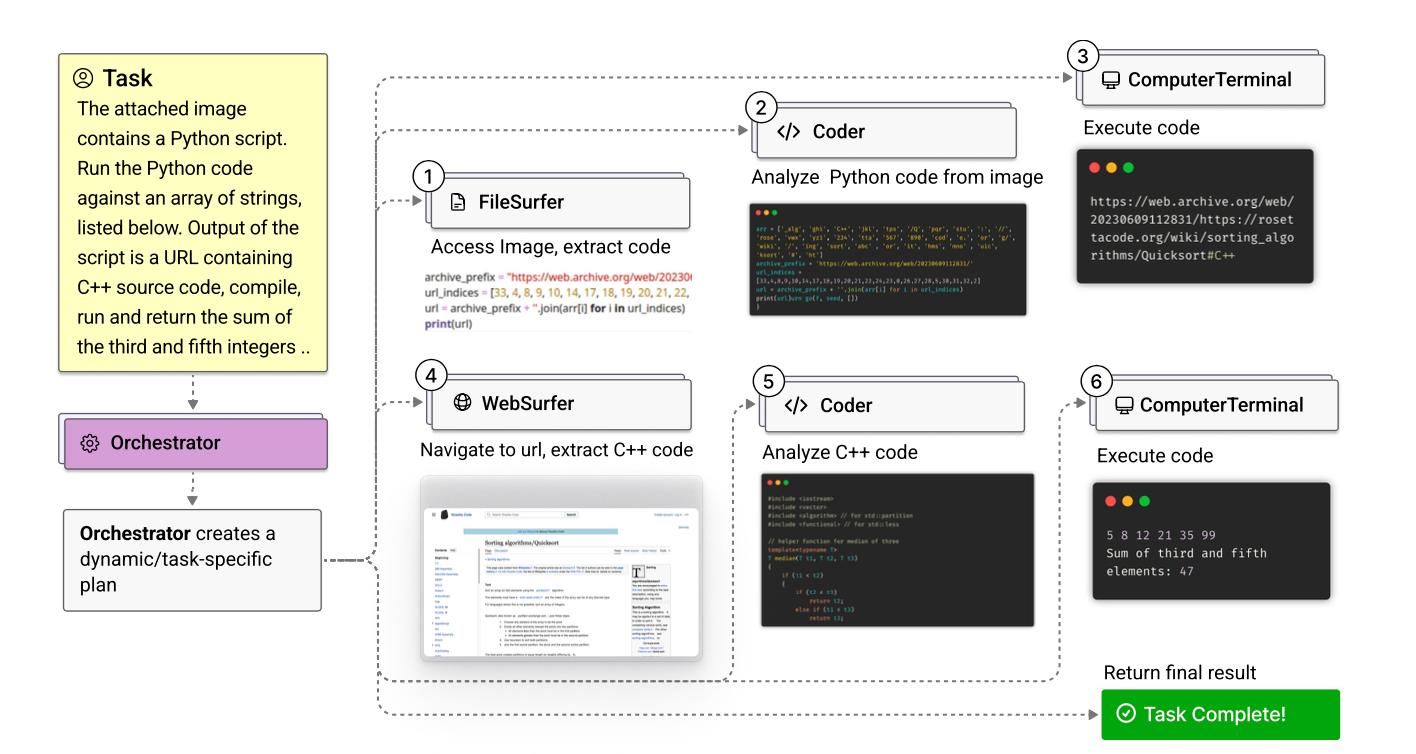
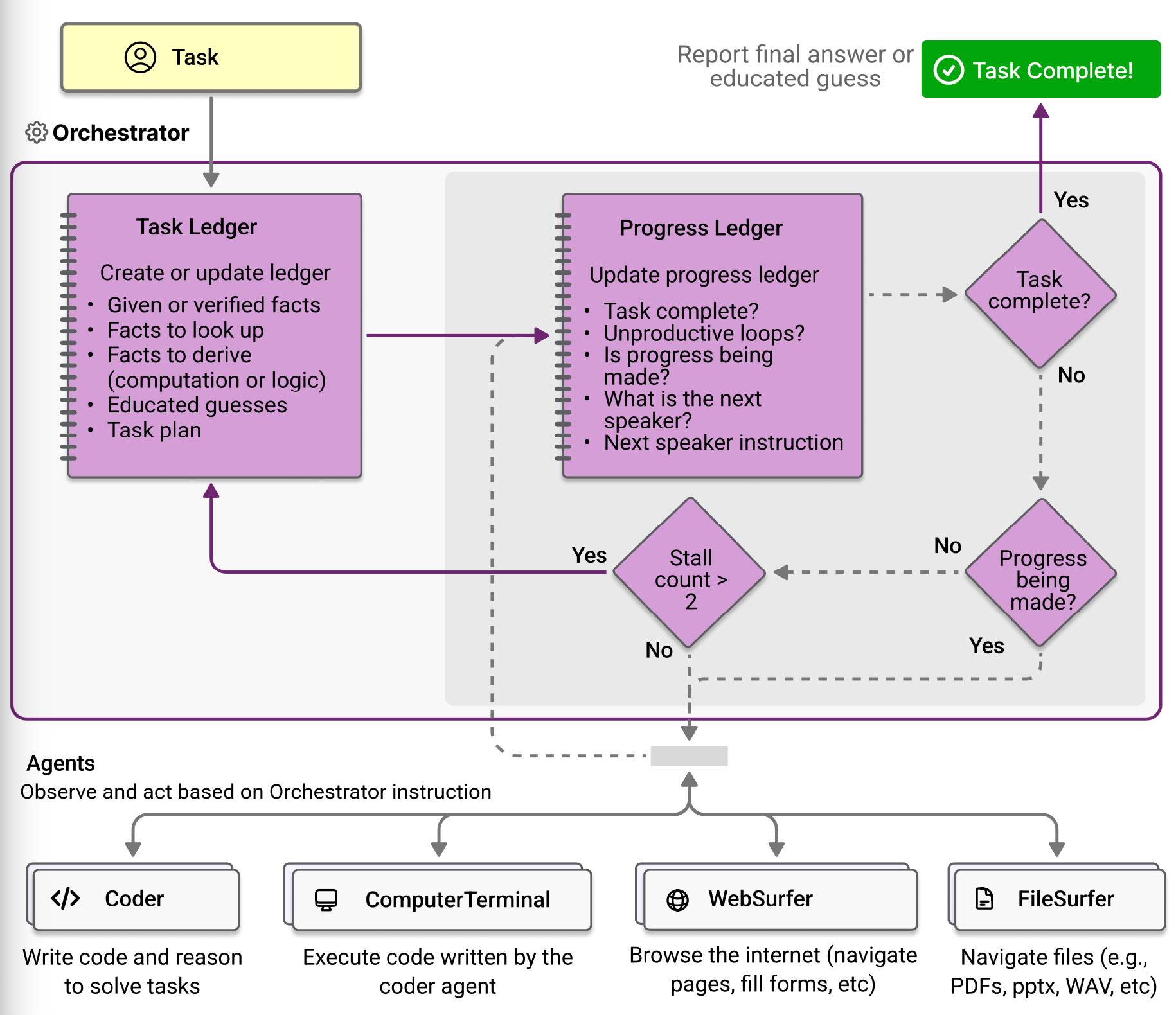
Magentic-One은 작업을 조율하는 Orchestrator 에이전트와 작업을 수행하는 Coder, ComputerTerminal, WebSurfer, FileSurfer로 구성됩니다.
Orchestrator는 두 루프를 가지고 있는데 task ledger를 사용하는 outer loop와 progress leder를 사용하는 inner loop를 가지고 있습니다.
Outer loop
Orchestrator는 task ledger를 short term 메모리로서 사용합니다. task를 받으면 orchestrator은 요청을 반영하여 주어진 정보, 확인해야 할 정보(웹 검색), 계산해야할 정보(프로그래밍 및 추론), 학습된 추측 등을 이용해 task ledger를 생성합니다.
task ledger가 채워지면 orchestrator는 어떻게 이를 수행할지 고민합니다. Orchestrator는 팀의 멤버 정보와 현재 task ledger를 사용해 step-by-step 플랜을 고안합니다. 이 plan은 자연어로 표현되고 각 에이전트들이 수행할 스텝들로 구성됩니다.
이 Plan은 chain of thought 프롬프트와 유사하기 때문에 오케스트레이터나 다른 에이전트들이 정확히 이를 따를 필요는 없습니다. Plan이 형성되면 inner loop가 시작됩니다.
Inner loop
Inner loop 반복마다 Orchestrator는 process ledger를 만들기 위한 다섯 질문을 답합니다.
- 태스크가 완료 되었는지
- 팀이 looping 중이거나 반복 중인지
- Forward progress가 만들어졌는지
- 어떤 에이전트가 다음에 말할 차례인지
- 그 팀 멤버에게 어떤 instruction 혹은 질문을 물어봐야하는지
질문에 답을 하면서 어떤 에이전트가 어떤 작업을 수행할지 결정하고 순서를 조율합니다.
Orchestrator는 내부적으로 업무의 진척도가 있는 지를 검사해 루프가 진행되어도 진행이 되지 않는다면 counter를 증가시킵니다. 이 counter가 임계값을 넘어가면 inner loop를 탈출해 outer loop를 진행하고 inner loop에서의 결과를 outer loop에 반영해 계획을 변경할 수 있도록 합니다.
에이전트의 종류
Magentic-One에서 사용하는 에이전트 종류를 간단히 소개하겠습니다.
WebSurfer
- WebSurfer는 요청을 받으면 액션 스페이스 중 하나의 액션으로 매핑하고 web page의 새로운 상태를 스크린샷과 설명으로 보고합니다.
- WebSurfer의 액션 스페이스는 naviagtion(URL 방문, web search 수행, web page내 스크롤링), web page action(클릭과 타이핑), reading action(요약 및 질문에 답하기)로 구성되어 있습니다.
- reading 액션은 WebSurfer가 전체 문서의 컨텍스트 내에서 문서 Q&A를 할 수 있게 해주어 orchestrator와의 라운드 트립을 줄이는 효과가 있습니다.
- Web page와 상호작용(클릭, 타이핑)할때는 WebSurfer는 현재 웹 페이지에서 동작합니다. 논문에서는 set of marks prompting을 사용했다고 합니다.
참고로 set of marks prompting은 입력 이미지를 의미있는 영역으로 분할하고 각 영역을 표식으로 덧씌우는 방식을 말합니다.

FileSurfer
- Websurfer랑 비슷하지만 커스텀 마크 다운 베이스 파일 프리뷰 어플리케이션을 사용한다는 것이 다릅니다.
- PDF, 오피스 문서, 이미지, 비디오, 오디오 처리가 가능합니다.
- 디렉토리를 리스팅하거나 폴더 구조를 navigate 하는 기능도 가능합니다
ComputerTerminal
- 프로그램을 실행할 수 있게 하는 console shell 제공합니다.
- ComputerTerminal은 shell command를 실행할 수 있고 프로그래밍 라이브럴리도 다운로드 및 설치가 가능합니다.
4. 필자의 활용법
필자는 사내에서 사이드 프로젝트로 멀티 에이전트를 활용한 E2E 테스트 자동화 시스템을 만들고 있습니다.
E2E 테스트는 유닛 테스트와 달리 어플리케이션의 상태에 따라 같은 API라도 결과가 다르게 반환되기 때문에 테스트 로직을 짜기 복잡합니다. 대략적인 구조는 다음과 같습니다.
(1) 어플리케이션 상태 확인
(2) 그에 따른 테스트 대상 API의 결과 예상
(3) 테스트 대상 API 호출 후 예상 결과 비교
필자는 (1), (2), (3)을 전부 수행하는 시스템을 Autogen을 통해 데모로 만들어보았습니다. 전부 밝힐 수 없지만 간단하게 구조를 소개하면 다음과 같습니다.
- Magentic-One의 orchestrator처럼 에이전트의 수행 순서를 결정하는 에이전트
- 전체적인 테스트 구조를 그리는 Planner
- 코드를 생성하는 Coder
- 코드의 퀄리티를 판단하는 Critic
- 코드를 수행하는 Executor
이 프로젝트는 현재 제가 메인으로 작업 중인 프로젝트의 테스트를 자동으로 생성하는 것까지 성공하였습니다. 작업 중 깨닫게 된 것들을 간단하게 공유하겠습니다.
- 각 에이전트의 역할은 최대한 잘게 쪼개야 합니다.
- 프롬프트는 최대한 구체적으로 써줄수록 좋습니다.
- 테스트 구조 설계와 같은 전체적인 계획을 짜는 에이전트는 OpenAI의 4o 모델 이상의 LLM 모델을 사용해야 제대로 계획을 생성합니다.
- 시스템 한번 사용할 때 수많은 LLM 호출이 발생하기에 9만, 10만 토큰을 사용하기도 합니다.
- 이 때문에 제대로 활용하려면 토큰 수를 줄이는 기술 적용이 반드시 필요합니다.
해당 프로젝트는 시간이 날 때마다 조금씩 개선하고 있고 나중에 공개할 수 있으면 좋겠습니다.
LLM 에이전트에 관심이 있다면 바로 Autogen 혹은 MetaGPT의 튜토리얼을 따라해보면서 어떻게 동작하는지 감을 익히시는 것을 추천합니다. 생각보다 어렵지 않다는 것을 알게 될 것입니다.
Reference
A Survey on Large Language Model based Autonomous Agents
Revolutionizing software testing: Introducing LLM-powered bug catch
METAGPT: META PROGRAMMING FOR A MULTI-AGENT COLLABORATIVE FRAMEWORK