
벡터 검색 알고리즘 살펴보기(2): HNSW, SPANN

벡터 검색 알고리즘 중 HNSW와 SPANN에 대해 알아봅니다.
들어가며
이전 “Similarity Search와 HNSW”라는 글에서 Voronoi diagram, Product Quantization, HNSW에 대해 간단히 다뤄보았다.
해당 글에서 HNSW을 자세히 다루지 못하였고 다른 ANN 알고리즘과 비교를 하지 못하여 아쉬웠었다.
이번 글은 현재 가장 많이 쓰이는 벡터 검색 알고리즘 HNSW(2016)을 살펴보고 Microsoft에서 발표한 SPANN(2021)을 살펴보며 두 알고리즘이 어떤 차이가 있는지 알아볼 것이다.
Introduction
어떤 벡터 q가 들어왔을 때, 현재 데이터베이스가 가지고 있는 벡터들 중 가장 가까운 벡터 k개를 반환하는 알고리즘들을 K-NN(K-nearest neighbor search)이라고 한다. 가장 가까운 벡터 k개를 반환하려면 q와 모든 벡터의 거리를 계산해야 하기 때문에 K-NN 알고리즘은 시간이 오래 걸리는 단점이 있다.
그래서 널리 사용되는 벡터 검색 알고리즘은 ANN(approximate nearest neighbor search)이다. ANN은 가장 가까운 벡터 k개를 반환하는 것은 보장하지 못하지만 최대한 반환하려고 노력하는 알고리즘이다. ANN의 정확도는 반환한 k개 중 정말 가장 가까운 벡터들은 몇 개 들어있는지(recall)로 평가할 수 있다.
벡터 검색 알고리즘은 메모리만 사용하느냐, 디스크도 같이 사용하느냐(Hybrid)에 따라서 달라진다. 디스크 접근이 많아질 수록 성능이 하락하기 때문에 디스크를 사용하는 알고리즘들은 디스크 접근을 최소화해야 한다. 반면 메모리만 사용하는 알고리즘은 그런 제약사항이 없다.
메모리만 사용하는 알고리즘들은 수백, 수천만(M) 단위 개수의 벡터에서 적합하다. 해시 기반 알고리즘, 트리 기반 알고리즘, 그래프 기반 알고리즘 등이 있다.
디스크를 같이 사용하는 알고리즘은 수십억(B) 단위 개수의 벡터를 다룰 수 있다. Inverted Index(역색인) 기반 알고리즘과 그래프 기반 알고리즘 등이 있다.
이번 글에서 다룰 HNSW는 그래프 기반 + 메모리만 사용하는 알고리즘이고, SPANN은 Inverted Index + 디스크를 같이 사용하는 알고리즘이다.
HNSW
HNSW는 그래프 기반 ANN 알고리즘이다. 가장 큰 특징은 이 그래프가 멀티 레이어라는 것이다. 각각의 레이어는 NSW(Navigable small world) 그래프이기에 알고리즘 이름이 HNSW(Hierarchical Navigable Small World)인 것이다.
Navigable small world는 특정 포인트를 잘 찾을 수 있도록 짜여진 그래프 구조이다. 이상적인 그래프로 알려진 들로네 그래프(delaunay graph)의 특성을 최대한 모사한 그래프 구조라고 생각하면 된다.
HNSW와 NSW에 대한 대략적인 설명은 이전 글에서 다룬바 있으므로 바로 구체적인 알고리즘 설명으로 넘어가겠다. (미리 해당 글을 읽고 오는 것을 추천한다)
HNSW: 튜닝 파라미터
HNSW에서 사용하는 파라미터는 다음과 같다.
- M: 노드가 새로 레이어에 입력될 때 M개의 edge를 다른 노드들에 연결한다.
- Mmax: 노드가 가질 수 있는 최대 edge 개수다. 만약 새로운 노드가 연결되어 Mmax보다 edge 개수가 많아지면 다른 edge를 버린다.
- ef(efSearch): 검색시 이웃 노드들을 선발할 때 사용하는 후보 개수
- efConstruction: 입력시 이웃 노드들을 선발할 때 사용하는 후보 개수
- mL: 새 노드 입력시 해당 노드가 입력되는 가장 높은 레이어를 결정하는 파라미터
HNSW: 입력 알고리즘
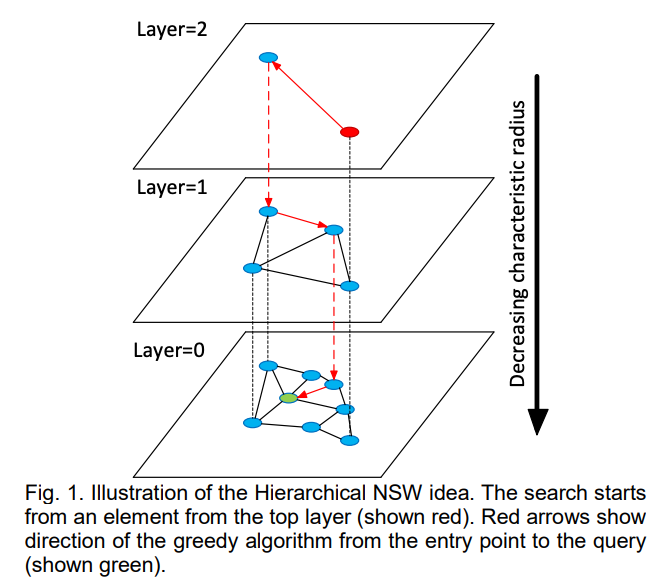
어떤 노드가 입력될 때 노드가 입력되는 가장 높은 레이어(L)는 랜덤하게 정해진다(-ln(unif(01))*mL). 그리고 해당 노드의 입력은 L부터 최하위 레이어까지 반복된다.
각 레이어에 노드가 입력될 때 해당 노드와 edge로 연결될 이웃 노드들을 골라야 한다.
이웃 노드를 고르는 과정은 그래프를 타고 이동하는 과정이다.
- 레이어의 엔트리포인트에서 시작한다. (레이어는 L부터 시작)
- 이동한 노드의 모든 이웃 노드들과 입력된 노드와의 거리 계산을 한다.
- 가까운 노드를 efConstruction 개수만큼 리스트로 유지한다.
- 가까운 노드로 이동한 후 2-3을 반복한다. 리스트가 더 이상 업데이트되지 않으면 멈춘다.
- 입력된 노드를 efConstruction개 노드와 모두 연결하지 않고 이 중 M개를 골라 입력된 노드와 연결한다.
- M개를 고르는 방법은 휴리스틱한 방법을 사용한다.
- edge들을 연결한 후 edge가 Mmax개를 넘은 노드들은 다시 이웃들을 골라 edge 개수를 Mmax개로 맞춰준다.
- 이 작업을 최하위 레이어까지 반복한다.
6번에서 사용하는 M개를 고르는 방법은 여러 가지가 있을 수 있다.
가장 간단한 방법은 가까운 노드 M개를 연결하는 방법이다. 그러나 이렇게 연결하면 이상적인 그래프 모양이 나오지 않는다. 예를 들어 노드들이 여러 클러스터로 뭉치고 클러스터간 edge가 희박한 경우가 발생할 수 있다. 이 경우 검색시 entrypoint와 먼 쿼리 벡터가 들어오면 검색 효율이 크게 떨어진다.
논문에서는 이웃 노드들간 edge 길이보다 입력된 노드와의 edge가 더 짧은 경우만 연결하는 휴리스틱을 예로 제시하였다.
예를 들어 입력된 노드를 a, 후보 이웃 노드를 n1, n2라고 하자. 먼저 a와 가장 가까운 노드 n1을 연결한다. 그리고 a와 n2의 거리가 n1과 n2의 거리보다 짧다면 n2와 a를 연결하고, 그렇지 않으면 연결하지 않는다. 이 휴리스틱은 단순한 예이고 확장할 수 있다. 논문에서는 extendCandidates와 keepPruneConnection을 추가 flag로 넣는 알고리즘을 소개하였다.
HNSW: 검색 알고리즘
검색은 최하위 레이어로 가는 과정과 최하위 레이어에서 검색을 하는 과정 2가지로 나눌 수 있다.
최하위 레이어로 가는 과정
먼저 최상위 레이어의 entrypoint에서 시작한다. 이때 efSearch를 1로 세팅한 상태로 그래프에서 이동한다. 이동할 후보 노드를 1개로 세팅하는 것이다.
efSearch가 1이므로, 후보 노드를 1개만 유지한다. 현재 노드의 이웃 중 가장 쿼리 노드와 가까운 노드로 이동하는 것을 반복하는 것이다. 더 이상 이동할 수 없으면 다음 하위 레이어로 이동한다.
최하위 레이어에서 검색
efSearch를 사용자 설정 값으로 사용한다.
현재 노드의 이웃들과 쿼리 벡터의 거리를 계산하고, 쿼리 벡터와 가까운 노드 efSearch개를 업데이트하며 이동한다. 이를 반복하여 greedy하게 이동하게 되면 최종적으로 완벽하지 않지만 쿼리 벡터와 가까운 노드 efSearch개를 얻을 수 있다.
HNSW: 알고리즘 복잡도
검색 복잡도는 O(logN)이다.
논문에서는 이 복잡도 계산을 각 레이어가 들로네 그래프라고 가정하고 계산한다. 들로네 그래프는 greedy하게 이동해도 가장 가까운 노드를 찾을 수 있다(local minimum과 global minimum이 같음).
HNSW의 각 레이어가 들로네 그래프의 성질을 가지고 있다고 가정하자. 어떤 레이어에서 노드로 이동한다는 것은 쿼리 벡터에 조금 더 가까워졌음을 의미한다. 그런데 들로네 그래프의 특성상 도착한 노드는 상위 레이어에 존재하지 않는다. 만약 상위 레이어에 존재했다면 상위 레이어에서 이동하면서 해당 노드를 이미 방문했을 것이기 때문이다.
어떤 레이어에서 s번 이동을 했다면 이번 레이어에 방문한 s개의 노드가 상위 레이어에 없다는 것을 의미한다. HNSW에서 노드가 배정되는 레이어 레벨은 지수함수로 결정된다. 따라서 s번 이동을 할 확률은 e^(-s*mL)만큼의 확률을 갖는다.
어떤 레이어에서 순회하는 코스트는 e^(-s*mL)의 무한 등비급수 합으로 계산할 수 있다(1번 이동, 2번 이동 ... 무한번 이동). 이 코스트는 상수가 되므로 O 복잡도 계산에 영향을 미치지 않는다.(1/(1-exp(-mL)))
레이어의 개수가 logN에 비례하고 각 노드가 가지는 edge 개수도 상수로 제한되므로 최종적으로 검색 복잡도는 O(logN)이다.
인덱스 생성 복잡도는 O(N*logN)이다.
원소 입력은 결정된 상위 레이어 L부터 최하위 레이어까지 K-ANN 검색을 하고, 선발된 노드들에 대해 edge를 연결하는 과정이다.
원소들이 가지는 평균 레이어 개수는 E[-ln(unif(0,1))*mL] + 1 = mL + 1로 상수이다.
따라서 원소 개수(N) * 레이어 개수 * K-ANN(logN) = O(N*logN)이다.
SPANN
SPANN은 Microsoft에서 2021년 발표한 메모리-디스크 하이브리드 ANN이다.
메모리-디스크 하이브리드 ANN 중 하나가 같은 Microsoft에서 2019년에 발표한 DiskANN이다.
DiskANN은 메모리에 PQ(Product Quantization. 이전 글 참고)로 압축한 벡터들을 저장하고 디스크에 원본 벡터를 저장한다.
DiskANN에서 검색은 메모리 내 생성된 그래프를 이용해 ANN을 한 뒤 해당하는 벡터들을 디스크에서 로드 후 다시 reranking한다. 하지만 PQ로 인한 재현율(recall) 이슈가 있었다.
SPANN은 역색인 방식과 비슷하게 벡터를 클러스터로 나누는 방식을 취했다. 메모리에 클러스터의 centroid들을 보관하여 인덱스를 구성하고 디스크에는 centroid에 대응되는 벡터들로 구성된 포스팅 리스트(posting list)가 존재한다.
SPANN은 압축을 하지 않은 벡터들로 검색을 하기 때문에 recall이 DiskANN에 비하여 개선이 되었다.
SPANN의 구체적인 구현은 논문에 나와있지는 않지만, 구현체는 공개되어 있다.
이번 글은 구현체는 참고하지 않았고, 논문에서 공개한 아키텍처가 흥미로운 부분들이 있어 살펴보고자 한다.
SPANN: 인덱스
SPANN은 메모리가 저장하고 있는 centroid로 구성된 인덱스가 coarse grained index로서 기능하고 디스크에 저장된 포스팅 리스트가 fine grained index로서 기능한다.
포스팅 리스트가 다시 인덱스로 기능한다고 한 이유는 디스크 안에서 클러스터가 다시 계층화가 되기 때문이다.
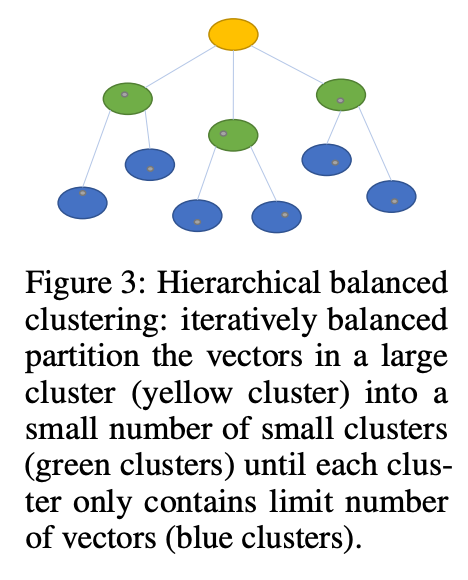
만약 메모리에서만 클러스터를 나누면 각 클러스터가 가지고 있는 포스팅 리스트가 너무 길어져 검색 효율이 떨어질 수 있다.
SPANN은 포스팅 리스트 길이를 제한하기 위해 디스크 내 저장되는 포스팅 리스트들을 계층화 구조로 저장하였다.
이때 디스크에서 포스팅 리스트를 대표하는 벡터는 centroid가 아니라 centroid에 가장 가까운 실제 벡터를 사용한다. 이는 벡터 거리 검색 계산 코스트를 아끼는 효과가 있다.
포스팅 리스트를 대표하는 벡터들은 메모리에 올라가면 SPTAG 인덱스(Microsoft의 그래프 기반 ANN)로 구성된다.
정리하면, 디스크 내에서 레이어 + 그래프 기반 인덱스를 사용하는 것이다. 이러한 접근법은 HNSW와 비슷하다고 느낄 수 있다.
SPANN: 경계 이슈
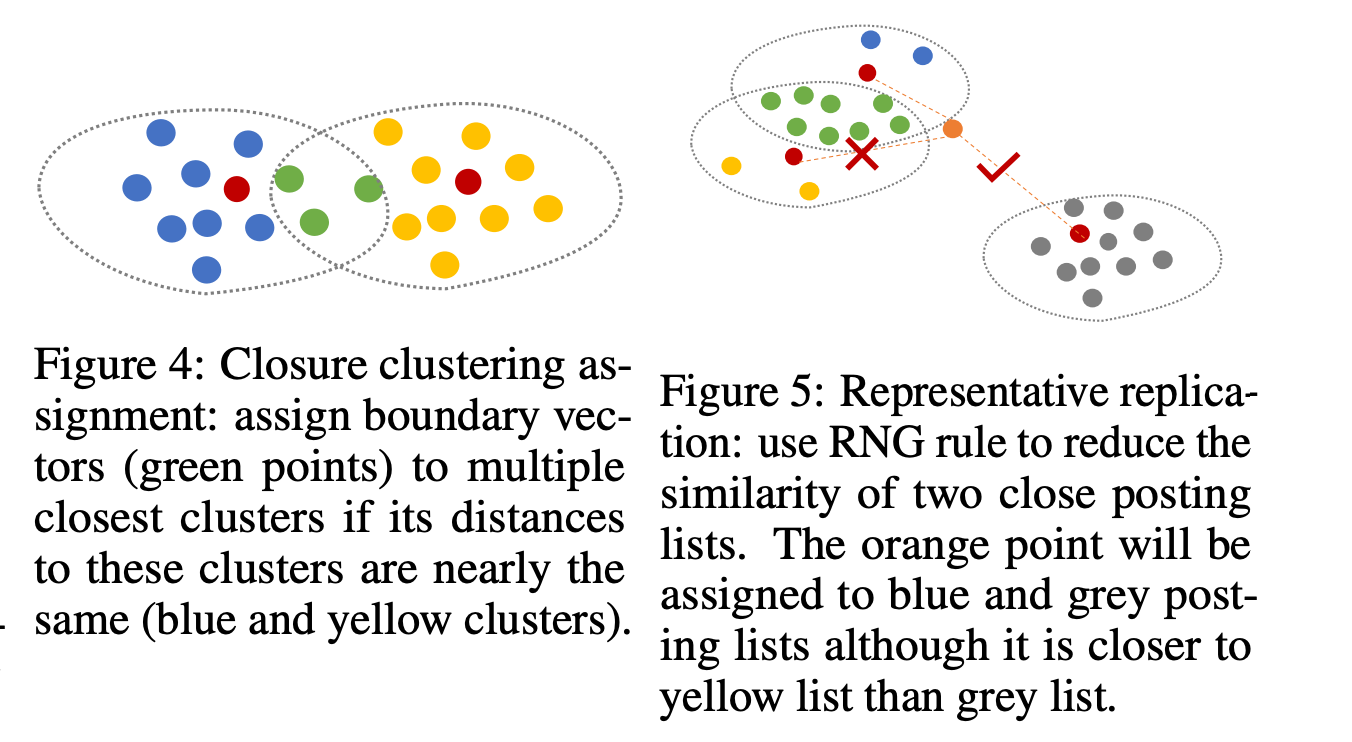
클러스터로 벡터들을 나누어 저장할 때 발생할 수 있는 이슈는 경계 근처에 있는 벡터들이 검색이 되지 않을 수 있다는 것이다.
예를 들어 쿼리 벡터가 경계 근처이면 쿼리 벡터가 속해 있는 클러스터뿐만 아니라 경계에 맞닿은 클러스터 내 벡터들도 정답 셋에 포함될 수 있다.
이러한 점을 방지하기 위해 SPANN에서는 경계 근처에 있는 벡터들은 여러 클러스터에 중복 저장한다. 구체적으로 가장 가까운 centroid와의 거리를 기준으로 하여 거리 차이가 크지 않을 때 해당 클러스터에도 벡터를 저장한다.
만약 포스팅 리스트의 길이를 짧게 유지한다면 너무 많은 중복 벡터들이 생길 수 있는데, 이를 최적화하기 위해 RNG rule을 사용하여 비슷한 포스팅 리스트에는 한번만 들어가게 한다. Figure 5를 보면 파란 원소 클러스터와 노란 원소 클러스터가 이미 중복 원소가 많아 유사도가 높으므로 새로 입력된 주황색 원소가 파란 원소 클러스터와 회색 원소 클러스터에 입력된다.
SPANN: 검색
쿼리가 들어오면 고정된 개수의 포스팅 리스트를 검색 후보에 두는 것이 아니라 동적으로 결정한다. 간단히 생각해도 쿼리가 어떤 centroid에 굉장히 근접해 있으면 다른 centroid에 해당되는 포스팅 리스트 내 벡터가 정답으로 포함될 가능성은 굉장히 희박할 것이다.
따라서 가장 가까운 centroid와의 거리를 기준으로 하여 비슷한 거리를 가진 centroid들만 검색 후보로 포함시켜 검색을 진행한다.
SPANN: Evaluation
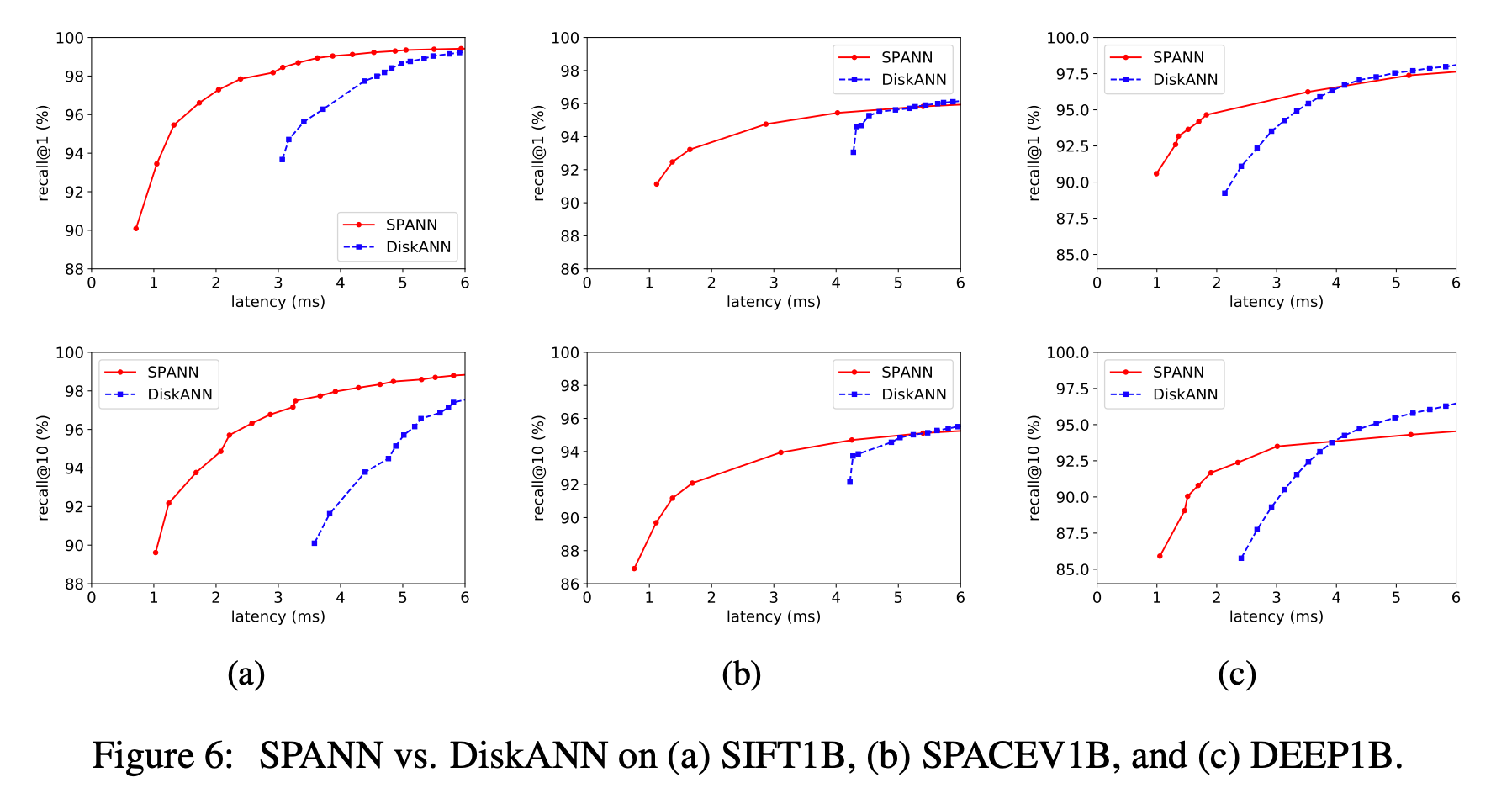
비교군으로 삼은 메모리-디스크 하이브리드 알고리즘 DiskANN에 비해 월등한 latency를 보여준다.
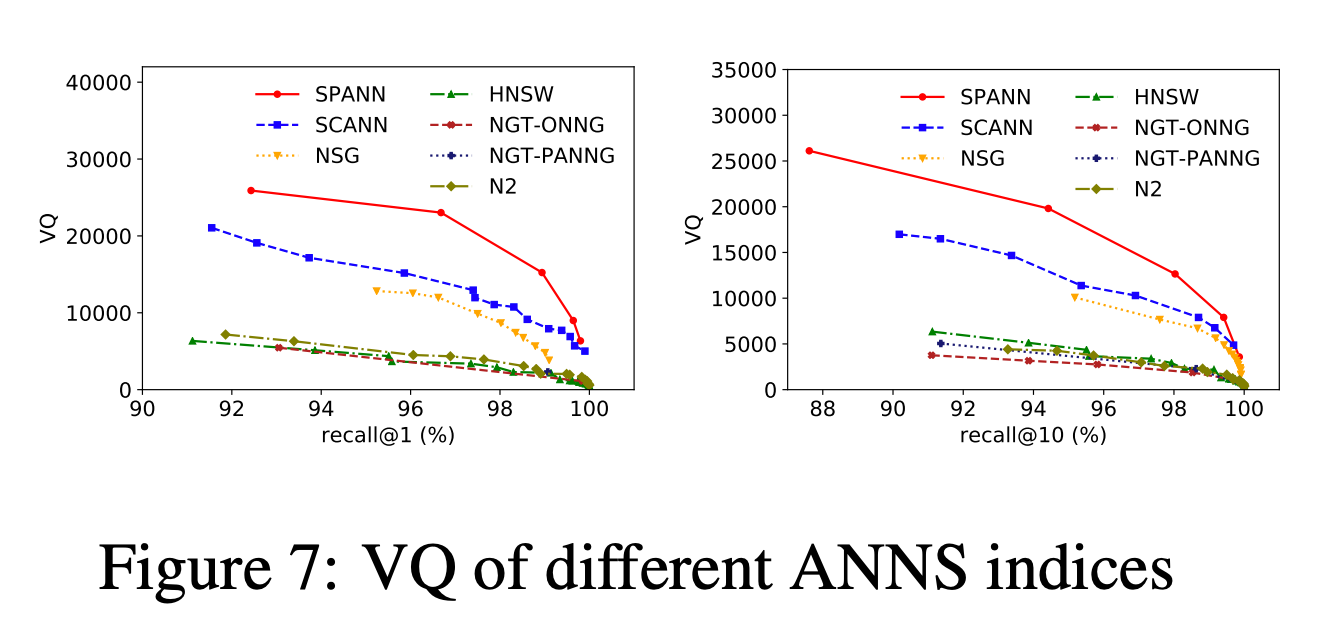
HNSW와 같이 메모리만 사용하는 알고리즘과 비교할 때는 VQ(Vector-Query)를 지표로 사용하였다. VQ는 한 머신이 초당 서빙할 수 있는 벡터와 쿼리의 곱을 의미한다. 쿼리 레이턴시와 메모리 비용을 모두 고려하였기 때문에 이 지표를 선택했다고 한다.
해당 지표에서는 SPANN이 메모리 기반 알고리즘보다 뛰어난 성능을 보여줬다.
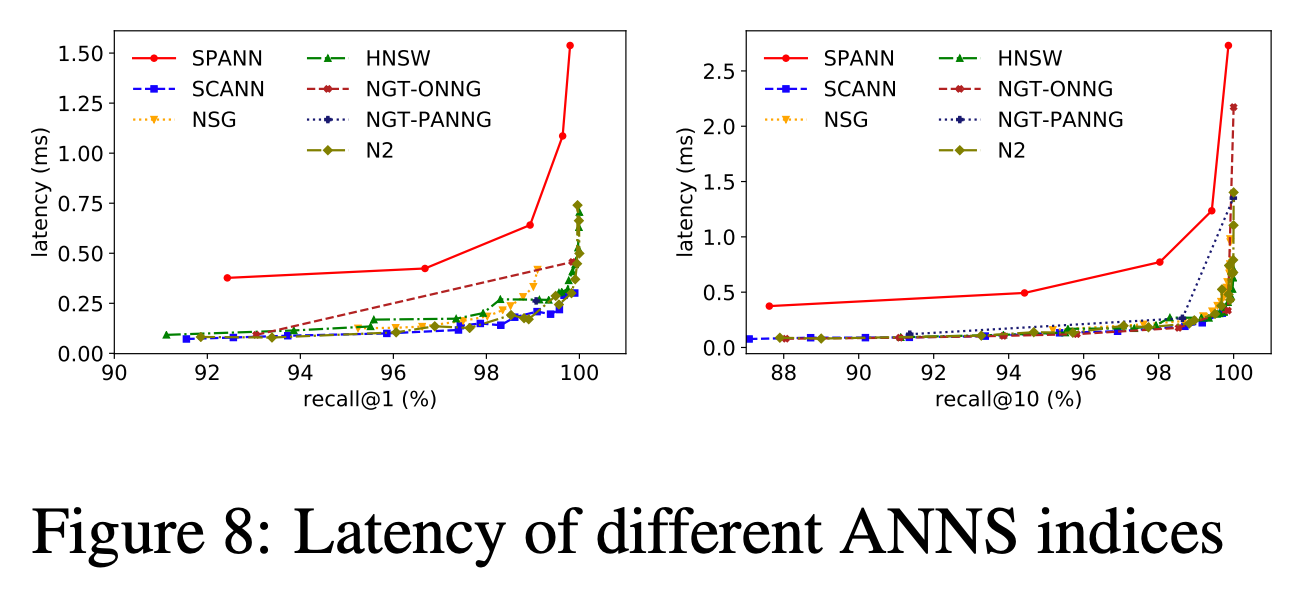
레이턴시 측면에서는 디스크를 사용하는 알고리즘 특성상 타 알고리즘에 비해 느렸다.