
[k8s] 개발자가 꼭 알아야 할 k8s DNS, iptable 업데이트 타이밍
![[k8s] 개발자가 꼭 알아야 할 k8s DNS, iptable 업데이트 타이밍](https://images.unsplash.com/photo-1477466535227-9f581b3eec21?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDJ8fHJvbGxpbmd8ZW58MHx8fHwxNzM1NjU3MDcwfDA&ixlib=rb-4.0.3&q=80&w=2000)
k8s 환경에서 어플리케이션을 이중화했음에도 rollout restart할 때 서비스가 일시적으로 사용 불가할 수 있습니다. 이는 k8s의 pod의 DNS, ip 업데이트시 CoreDNS와 iptable에 업데이트 시차가 존재할 수 있어 발생합니다.
이번 글에서는 pod을 statefulset으로 배포하는 경우와 deployment로 배포하는 경우를 나누고, 각각의 케이스에서 어떻게 이슈가 발생할 수 있는지 알아보겠습니다.
[요약]
- k8s + grpc에서 pod들을 rollout restart할 때 실패할 수 있는 지점들이 있습니다
- pod이 headless 서비스를 가진 statefulset이냐, 일반적인 서비스를 가진 deployment이냐에 따라 케이스가 다릅니다.
- grpc backoff 문제: backoff 간격을 줄여야 합니다.
- k8s CoreDNS, iptable 업데이트 시차 문제: k8s의 Prestop 훅을 설정해 iptable 업데이트가 pod 종료보다 먼저 될 수 있도록 유도할 수 있습니다.
Prerequisite: k8s의 kube-proxy와 CoreDNS
이번 글을 진행하기에 앞서 알고 있어야 하는 내용을 정리합니다.
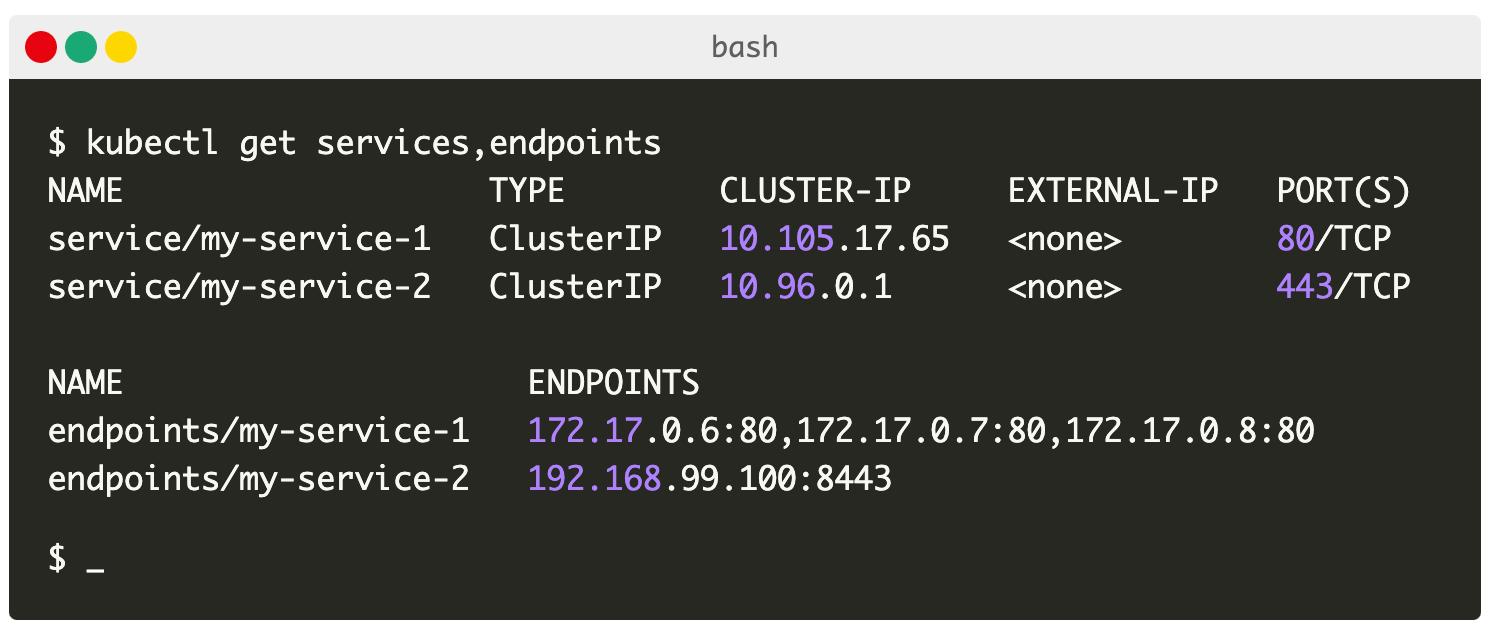
서비스(service)
k8s의 서비스는 pod의 주소들을 담고 있는 엔드포인트(k8s 리소스) 오브젝트들을 가지고 있습니다. pod의 주소들은 control plane이 가지고 있고, 엔드포인트 오브젝트는 이 주소들이 변경되면 이를 반영합니다.
kube-proxy
kube-proxy는 서비스의 엔드포인트 변경을 감지하여 서비스 ip 주소와 엔트포인트 간 rule을 생성하여 각 노드의 iptable에 반영합니다. 그래서 서비스 ip로 요청을 보내도 서비스가 구독하고 있는 엔드포인트의 pod으로 요청이 라우팅될 수 있는 것입니다.
CoreDNS
CoreDNS도 엔드포인트 변경을 감지하는 컴포넌트입니다. 만약에 headless 서비스를 사용하면 CoreDNS가 pod의 엔드포인트 변경에 따라 DNS 엔트리를 업데이트합니다.
여기서 기억해야할 점은 서비스가 headless냐 아니냐에 따라 pod의 DNS 엔트리 사용 여부가 달라진다는 것입니다. 서비스를 사용할 경우 pod의 DNS 엔트리로 통신할 필요가 없습니다. 반면 원하는 pod과 통신하고 싶을 때 서비스를 headless로 설정하고 pod의 DNS 주소로 통신하는 경우가 있습니다(statefulset + headless 서비스 조합). 이 경우 pod의 DNS 업데이트 시차 때문에 문제가 발생할 수 있습니다.
k8s에서 gRPC 서버 재시작시 gRPC 커넥션 변화
이중화된 어플리케이션을 보기 전에 단순히 한 어플리케이션을 종료하고 다시 시작하는 예제를 먼저 살펴봅시다.
이 예제에서는 ip주소가 아닌 도메인 이름으로 grpc 클라이언트가 gRPC 서버와 커넥션을 맺은 상황입니다. 예를 들어 k8s에서 headless 서비스를 가진 statefulset에 클라이언트가 FQDN으로 커넥션을 맺는 상황 등이 있을 것입니다. 간단히 말하면 서비스로 요청을 하는 것이 아닌, pod의 DNS로 직접 요청을 보내는 경우입니다.
gRPC 서버가 shutdown시 다음과 같은 순서로 커넥션 재연결이 진행됩니다.
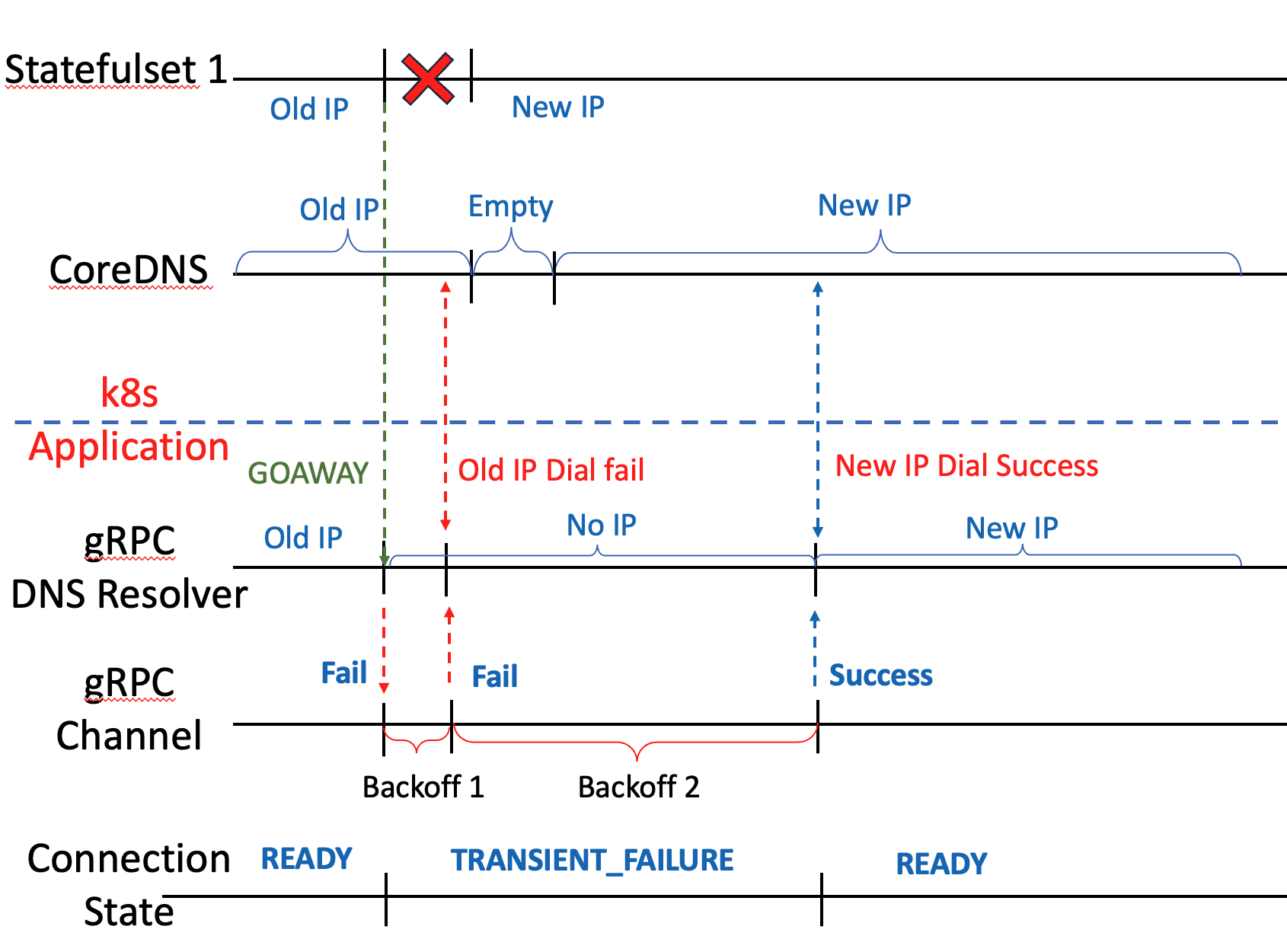
- gRPC 서버가 shutdown될 때 GOAWAY 프레임을 보냅니다.(GOAWAY 프레임은 HTTP2 명세에 정의된 것으로 커넥션을 끝낼 때 보내는 프레임입니다)
- GOAWAY 프레임을 받은 클라이언트는 기존에 저장한 ip를 지우고 새로운 ip를 얻으려 재시도합니다.
- 서버가 GOAWAY 프레임을 보내지 못하고 shutdown되면, 클라이언트는 커넥션이 끊어진 것을 인지한 뒤 기존에 저장한 ip를 지웁니다.
- CoreDNS로부터 ip를 얻습니다. 이때 ip가 업데이트가 안되었을 수 있습니다.
- ip dial 시도 후 타임 아웃이 발생하면 backoff 주기를 기다린 뒤 다시 ip를 얻습니다
- 성공할 때까지 3,4를 반복합니다
위 과정은 로그로 확인이 가능합니다. (로그에서는 ip와 port를 가렸습니다)
1. 처음 gRPC 채널을 만들면 resolver가 Endpoint에 ip 주소를 저장합니다.
2024/11/21 19:01:20 INFO: [core] [Channel #1]Resolver state updated: {
"Addresses": [
{
"Addr": "{ip1}:{port}",
"ServerName": "",
"Attributes": null,
"BalancerAttributes": null,
"Metadata": null
}
],
"Endpoints": [
{
"Addresses": [
{
"Addr": "{ip1}:{port}",
"ServerName": "",
"Attributes": null,
"BalancerAttributes": null,
"Metadata": null
}
],
"Attributes": null
}
],
"ServiceConfig": null,
"Attributes": null
} (resolver returned new addresses)2. 연결된 pod이 shutdown되면 GOAWAY를 보냅니다.
2024/11/21 19:01:34 http2: Framer 0xc0003ba000: read GOAWAY len=21 LastStreamID=2147483647 ErrCode=NO_ERROR Debug="graceful_stop"
2024/11/21 19:01:34 INFO: [core] [Channel #1 SubChannel #6]Subchannel Connectivity change to IDLE
2024/11/21 19:01:34 INFO: [transport] [client-transport 0xc0002a4000] Closing: connection error: desc = "received goaway and there are no active streams"
2024/11/21 19:01:34 http2: Framer 0xc0003ba000: wrote GOAWAY len=33 LastStreamID=1 ErrCode=NO_ERROR Debug="client transport shutdown"
2024/11/21 19:01:34 INFO: [transport] [client-transport 0xc0002a4000] loopyWriter exiting with error: connection error: desc = "received goaway and there are no active streams"
2024/11/21 19:01:34 INFO: [pick-first-lb] [pick-first-lb 0xc000988c90] Received SubConn state update: 0xc000988cf0, {ConnectivityState:IDLE ConnectionError:<nil>}
2024/11/21 19:01:34 INFO: [core] [Channel #1]Channel Connectivity change to IDLE
2024/11/21 19:01:34 http2: Framer 0xc0003ba000: read PING len=8 ping="\x01\x06\x01\b\x00\x03\x03\t"3. GOAWAY를 받은 gRPC resolver는 자신이 가지고 있는 address를 비웁니다
2024/11/21 19:01:50 INFO: [core] [Channel #1]Resolver state updated: {
"Addresses": null,
"Endpoints": [],
"ServiceConfig": null,
"Attributes": null
} (resolver returned an empty address list)
2024/11/21 19:01:50 INFO: [core] [Channel #1 SubChannel #6]Subchannel Connectivity change to SHUTDOWN
2024/11/21 19:01:50 INFO: [core] [Channel #1 SubChannel #6]Subchannel deleted
2024/11/21 19:01:50 INFO: [pick-first-lb] [pick-first-lb 0xc000988c90] Received error from the name resolver: produced zero addresses
2024/11/21 19:01:50 INFO: [core] [Channel #1]Channel Connectivity change to TRANSIENT_FAILURE
2024/11/21 19:01:50 INFO: [core] error from balancer.UpdateClientConnState: bad resolver state
2024/11/21 19:01:50 INFO: [pick-first-lb] [pick-first-lb 0xc000988c90] Received SubConn state update: 0xc000988cf0, {ConnectivityState:SHUTDOWN ConnectionError:<nil>}4. 이때부터 gRPC 클라이언트는 재시도를 시작합니다(backoff). CoreDNS가 아직 old ip를 가지고 있을 수 있어 old ip로 요청(Dial)을 하는 경우, 타임 아웃 이후 에러를 반환받습니다. (아래 로그에서 같은 IP로 재시도한 것을 확인할 수 있음)
2024/11/21 19:01:50 INFO: [core] Creating new client transport to "{Addr: \"{ip1}:{port}\", ServerName: \"{pod-name}.{service-name}:{port}\", }": connection error: desc = "transport: Error while dialing: dial tcp {ip1}:{port}: operation was canceled"
2024/11/21 19:01:50 WARNING: [core] [Channel #1 SubChannel #6]grpc: addrConn.createTransport failed to connect to {Addr: "{ip1}:{port}", ServerName: "{pod-name}.{service-name}:{port}", }. Err: connection error: desc = "transport: Error while dialing: dial tcp {ip1}:{port}: operation was canceled"
5. resolver는 유효한 ip로 dial이 성공할 때까지 반복합니다.
2024/11/21 19:01:59 INFO: [core] [Channel #1]Resolver state updated: {
"Addresses": [
{
"Addr": "{ip2}:{port}",
"ServerName": "",
"Attributes": null,
"BalancerAttributes": null,
"Metadata": null
}
],
"Endpoints": [
{
"Addresses": [
{
"Addr": "{ip2}:{port}",
"ServerName": "",
"Attributes": null,
"BalancerAttributes": null,
"Metadata": null
}
],
"Attributes": null
}
],
"ServiceConfig": null,
"Attributes": null
} (resolver returned new addresses)
위 로그에서는 gRPC 커넥션이 다시 연결되기까지 총 25초가 걸렸습니다.(19:01:34 → 19:01:59)
3. statefulset + headless 서비스 rollout restart 문제
위에서 다루었던 문제는 단순히 한 statefulset만 고려했을 때의 문제입니다.
보통 서비스를 운영할 때는 한 pod으로의 요청이 실패하면 다른 pod으로 요청을 합니다(이중화). 그렇기 때문에 rollout restart를 한다면 다른 pod이 요청을 수행해 유저의 요청이 최종적으로는 성공할 것이라 생각할 수 있습니다.
하지만 rollout restart를 하는 경우에도 실패하는 경우가 있습니다.
먼저 CoreDNS의 변화만 살펴봅시다.
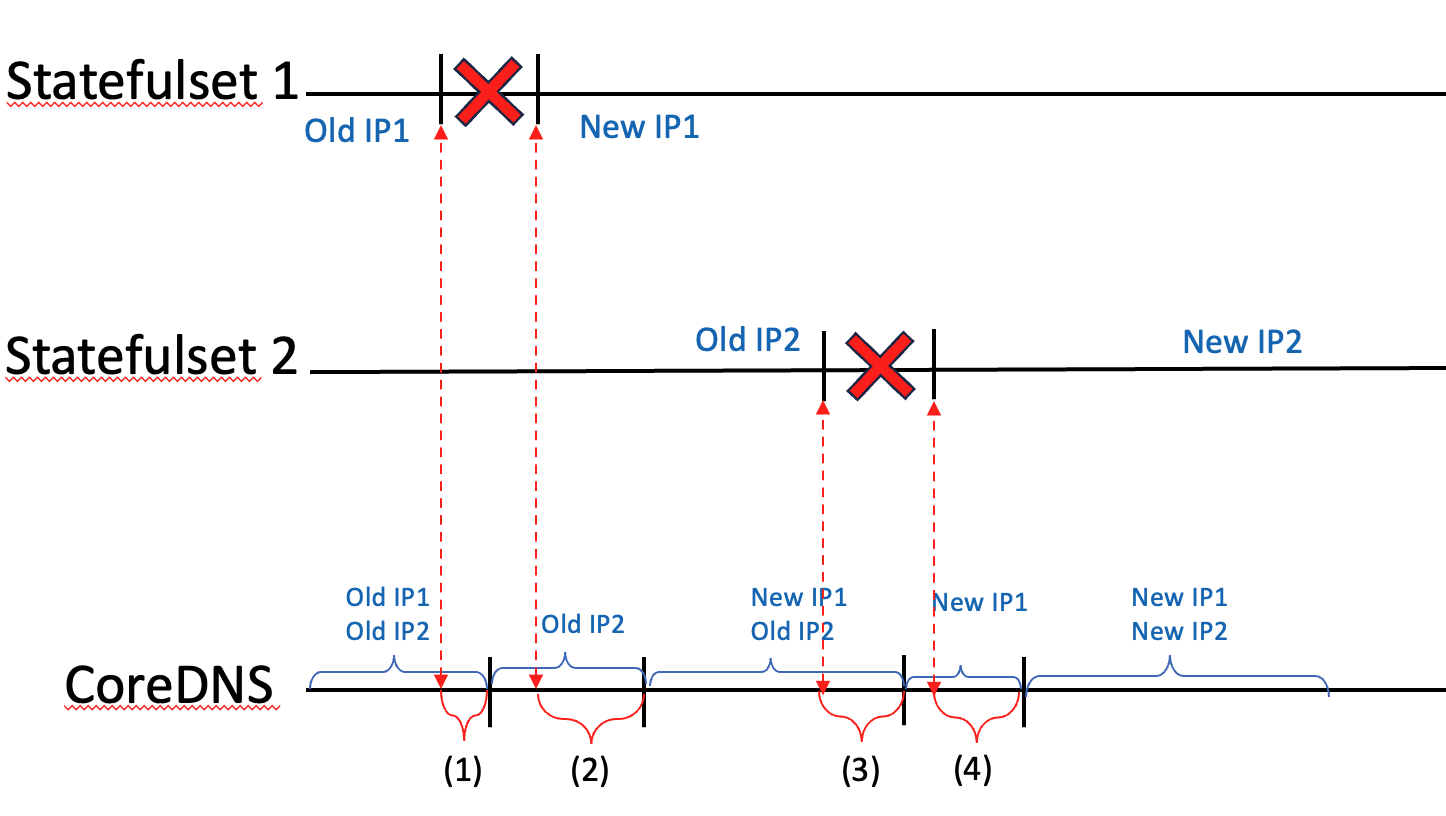
Pod이 생성되고 삭제될 때 CoreDNS의 엔트리포인트는 그보다 조금씩 늦게 업데이트될 수 있습니다.
(1) k8s가 pod 생성시 ( 구간 (2), (4) )
k8s는 pod이 ready가 된 것을 확인하고 엔트리포인트를 업데이트합니다. 따라서 pod 생성 이후 CoreDNS가 업데이트됩니다.
(2) k8s가 pod 삭제시 ( 구간 (1), (3) )
k8s는 pod 삭제와 엔트리포인트 삭제를 동시에 수행합니다. 경우에 따라서 엔트리포인트가 늦게 삭제될 수 있습니다
이 때문에 rollout restart시 사용자가 두 statefulset에 대한 요청이 전부 실패하는 경우가 생깁니다.
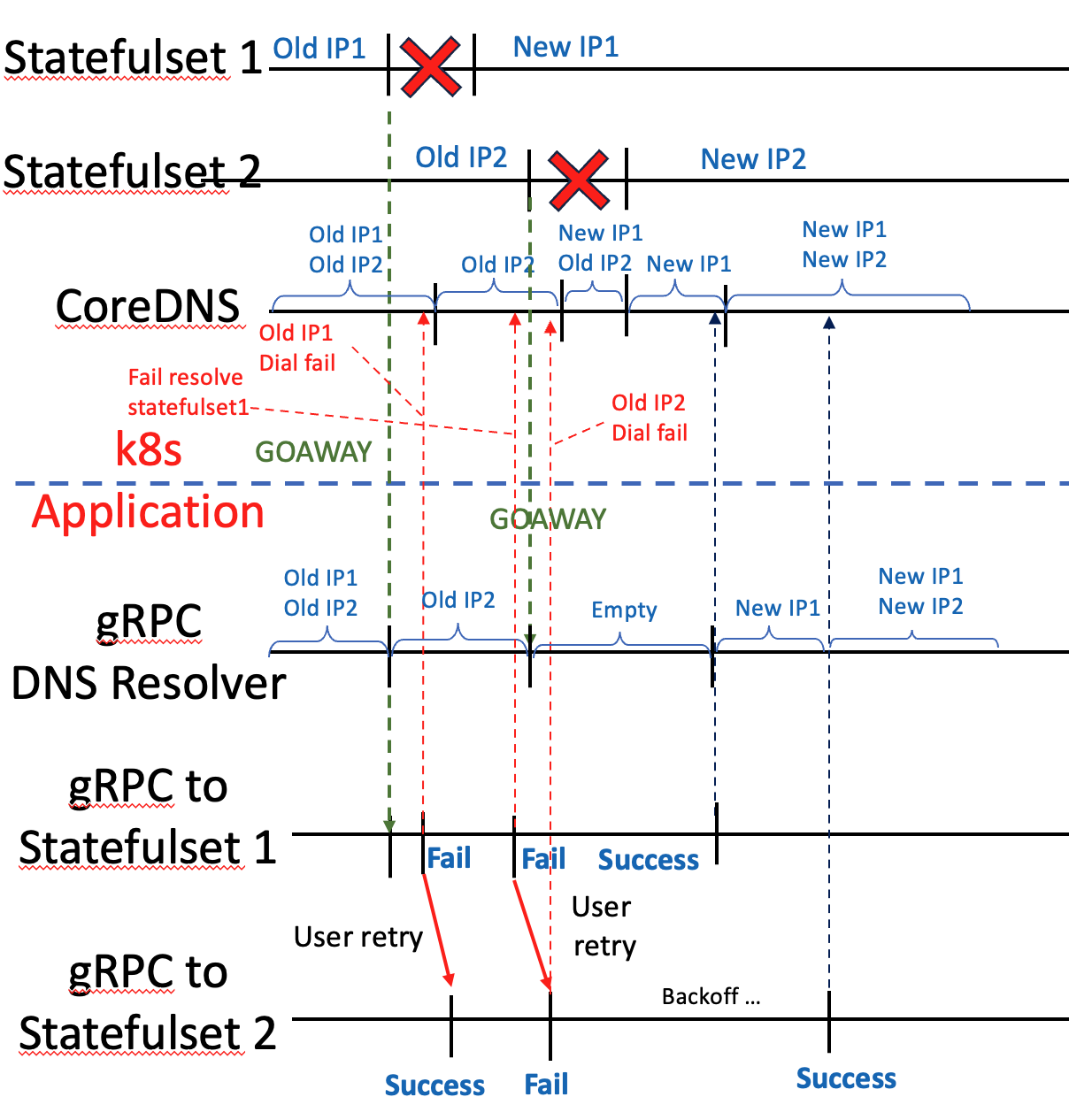
- Statefulset1이 종료 직후 statefulset1으로의 요청이 실패합니다.
- 사용자는 Statefulset2로 요청을 재시도하여 성공합니다.
- statefulset1이 재시작 완료하였습니다.
- statefulset2가 종료합니다.
- 사용자가 statefulset1으로 요청을 보냈으나 CoreDNS가 ip를 업데이트하지 않았거나, resolver가 backoff를 기다리느라 CoreDNS로부터 ip를 업데이트하지 못해 실패합니다. (timeout)
- 사용자는 statefulset2로 요청을 재시도했으나 statefulset2는 종료 중입니다.
- 4-6 구간에서 사용자의 요청들은 전부 실패합니다.
- statefulset1, 2로의 backoff가 반복되며 gRPC DNS resolver의 ip가 업데이트되면 성공합니다.
문제 구간은 4-6 구간입니다.
원인
- pod이 내려갔지만 CoreDNS가 오래된 IP를 여전히 가짐
- 새로운 pod이 떠있지만 CoreDNS가 IP를 업데이트하지 못함
- DNS resolver가 업데이트 재시도하는 구간(Backoff)의 요청들은 실패
해결 방법
첫 번째 원인: prestop 훅으로 pod의 삭제를 미루면 엔드포인트 삭제가 먼저 되도록 유도할 수 있습니다. pod의 삭제가 완료되야 그 다음 pod의 삭제가 이루어지기에, 엔드포인트 삭제로 사용자의 첫번째 pod 요청이 실패해도, 두번째 pod으로의 요청이 성공합니다.
두 번째 원인: k8s는 항상 pod의 상태를 확인하고 엔드포인트를 업데이트하여 막을 수 없습니다. 다만 첫 번째 방법을 적용하면 두 번째 원인으로 실패하지 않습니다.
세 번째 원인 : gRPC 클라이언트의 BaseDelay 및 Multiplier를 작게 설정해 Backoff 간격을 줄이는 방법이 있습니다.
서비스 + deployment rollout restart 문제
서비스를 통해 pod과 통신하면 pod의 DNS를 참조하지 않아도 됩니다. 또한 statefulset과 달리 정해진 pod에 통신하지 않아도 되기 때문에 발생할 수 있는 문제가 적습니다. 하지만 rollout restart시 문제가 없는 것은 아닙니다.
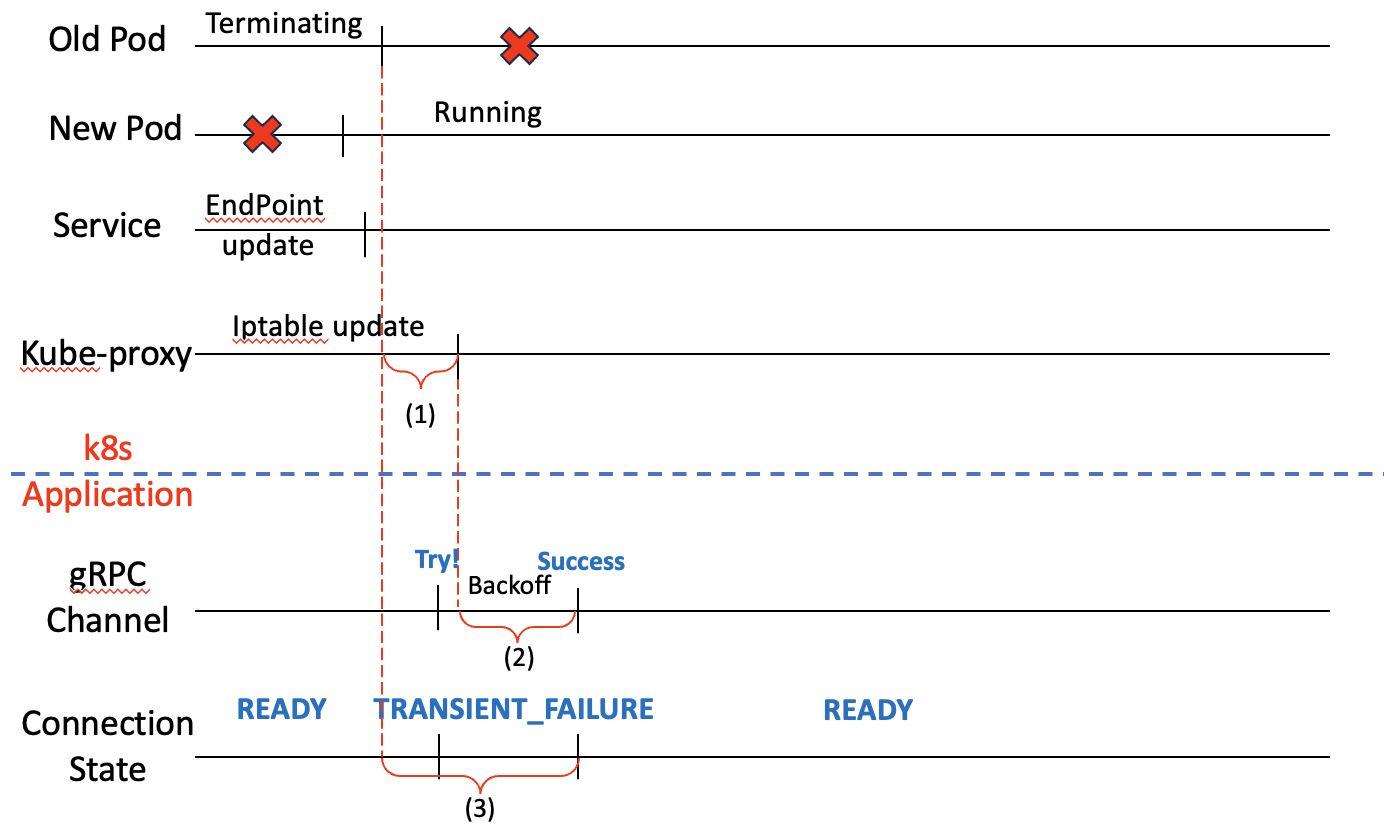
- 오래된 pod이 종료 전 새로운 pod이 실행됩니다.
- 서비스의 엔드포인트가 업데이트됩니다.
- 오래된 pod이 종료됩니다.
- kube-proxy가 업데이트된 주소를 iptable에 반영합니다.
- 3과 4사이 시차가 있어 성공해야할 요청이 실패합니다 ( (1) 구간)
- (1) 구간 사이 요청이 실패해 backoff만큼 쉬고 다시 재시도합니다. ( (2) 구간)
- 최종적으로 성공해야하지만 실패하는 구간 (3) 이 생깁니다.
문제 구간은 그림의 (1), (2) 구간입니다.
원인
구간 (1) : 이미 종료한 pod의 ip를 Iptable이 이미 갖고 있음으로써 생깁니다.
구간 (2) : backoff 주기 동안 들어오는 요청은 실패합니다.
해결 방법
구간 (1) : preStop 훅을 설정하여 pod의 종료를 미룹니다. pod이 Iptable 업데이트 이후 종료한다면 방지할 수 있습니다.
구간 (2) : BaseDelay 및 Multiplier를 작게 설정해 Backoff 간격을 줄이는 방법이 있습니다.
k8s에서 pod을 삭제시 엔드포인트 업데이트와 Pod의 종료는 병렬적으로 이루어집니다. preStop 훅으로 Pod의 종료를 늦추면 엔드포인트 업데이트가 pod 종료보다 빠르게 만들 수 있습니다.
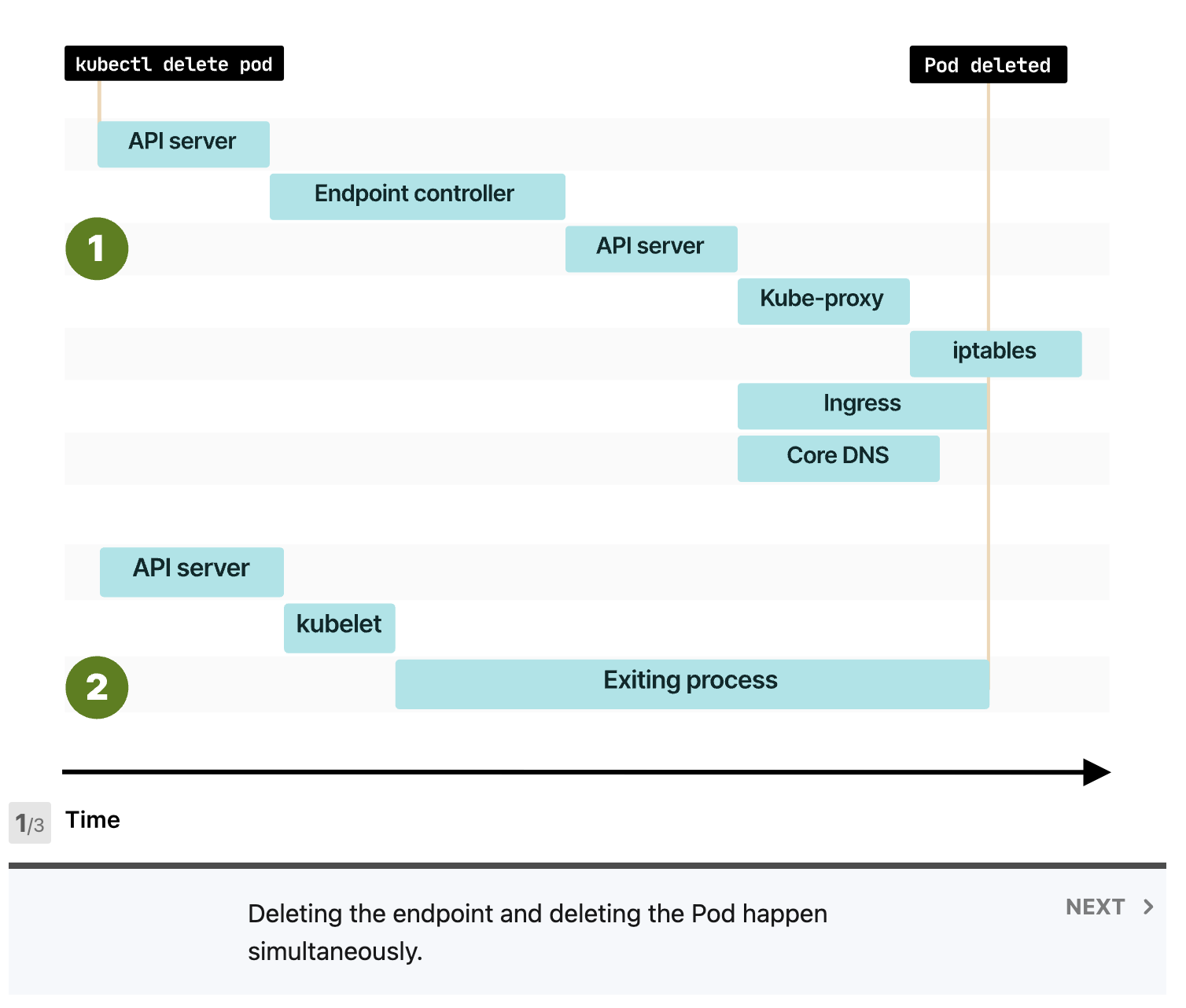
마무리하며
statefulset이던 deployment던 preStop 훅을 설정하여 엔드포인트 업데이트보다 pod의 종료를 미루면 문제가 해결됩니다.
gRPC 클라이언트처럼 요청 실패시 재시도를 자동으로 해주는 네트워크 라이브러리를 이용한다면 backoff 주기를 줄여주는 것도 큰 도움이 될 수 있습니다.
만약 당신의 어플리케이션이 문제가 없음에도 rollout restart시 일부 요청이 실패한다면, 이 글에서 말한 엔드포인트 업데이트 타이밍 문제일 수 있습니다.