
[Paper review] Databases in the Era of Memory-Centric Computing
![[Paper review] Databases in the Era of Memory-Centric Computing](https://images.unsplash.com/photo-1461354464878-ad92f492a5a0?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDJ8fHNoYXJlfGVufDB8fHx8MTc1MjM4NTI4Mnww&ixlib=rb-4.1.0&q=80&w=2000)
Compared to the rapid advancement of CPU performance, the growth rate of memory capacity has been steadily slowing down. Stemming from this issue, Databases in the Era of Memory-Centric Computing proposes an architecture aimed at efficiently utilizing memory, which has become increasingly expensive relative to other system components. The paper argues that this architecture is particularly well-suited for databases.
Published in 2025, the paper highlights the relatively new technology, CXL, as a key enabler for implementing memory-centric computing.
In this review, we will first briefly explain what CXL is and then examine the architecture proposed in the paper.
1. CXL Overview
1.1 What is CXL?
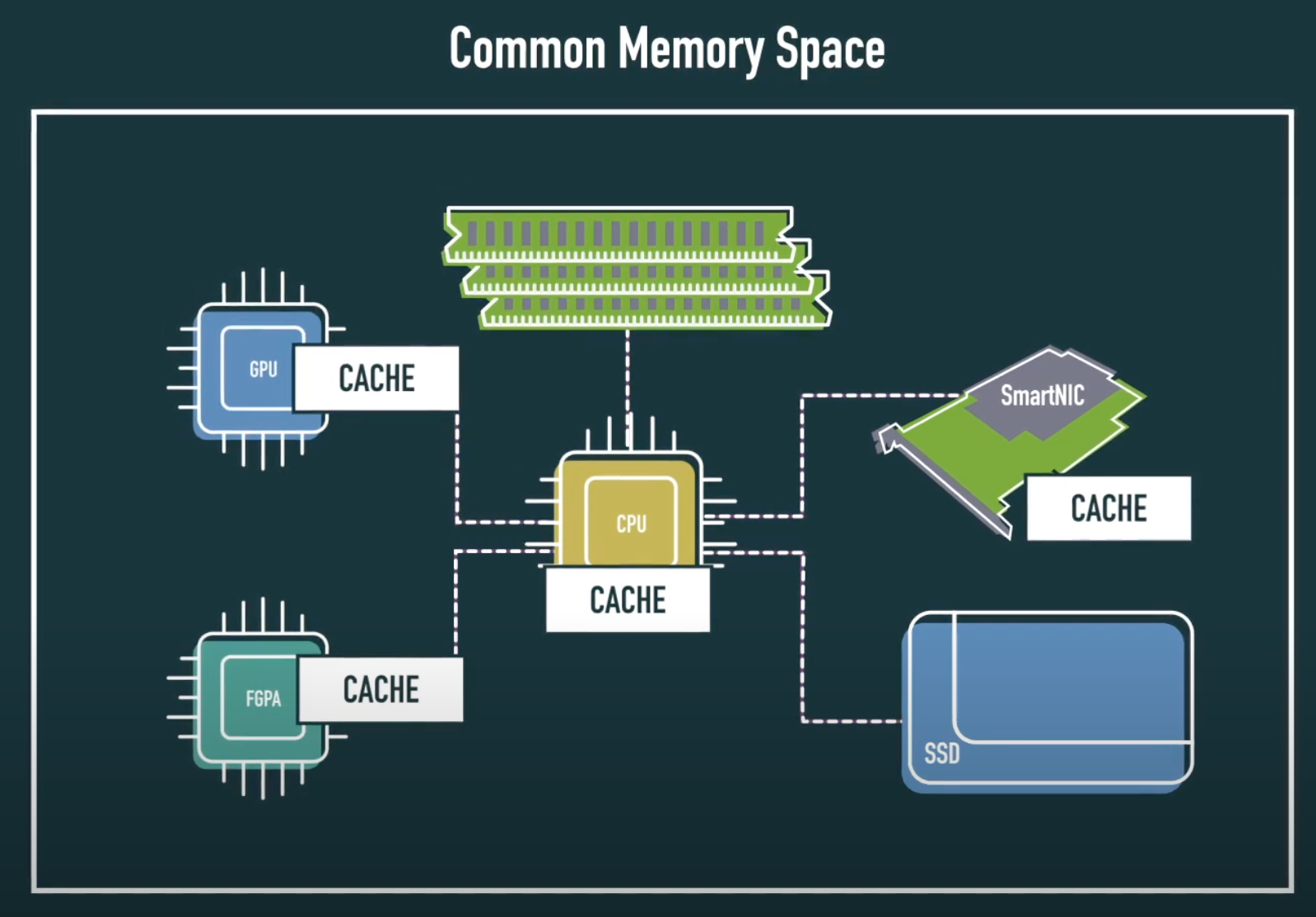
CXL (Compute Express Link) is a high-speed interconnect standard designed to enable low-latency, high-bandwidth, and cache-coherent data transfers between CPUs, accelerators, and memory devices.
CXL operates on the physical layer of PCI Express (PCIe) 5.0, maintaining compatibility and connectivity with existing PCIe infrastructure, while adding key capabilities such as memory sharing and coherence. In essence, CXL allows the host CPU to access and utilize the memory of external devices as if it were its own, and conversely, enables accelerators to directly access and cache the CPU’s memory.
1.2 CXL Architecture: Three Protocols
CXL employs a multi-protocol structure that simultaneously runs three protocols over a single physical link:
CXL.io
CXL.io operates in the same manner as PCIe, performing standard I/O operations such as device initialization, DMA transfers, register access, and interrupt handling. Even if a system does not support CXL, CXL devices can still function as standard PCIe devices. When both sides support CXL, they can switch to using the CXL protocol.
CXL.cache
This protocol allows devices such as accelerators or smart NICs to directly access and cache the host CPU’s memory. Through a hardware-level cache coherence mechanism, memory contents read or written by the device are automatically synchronized with the CPU’s cache. This enables data sharing without software-level copying, significantly reducing latency and boosting performance.
CXL.mem
This protocol allows the host CPU to directly access the memory on a CXL device—such as DRAM or non-volatile memory—via standard load/store operations. The device memory is mapped into the CPU’s physical address space and appears as a NUMA region. This allows flexible expansion of system memory capacity with much lower latency compared to traditional PCIe-based memory access.
1.3 CXL Device Types
CXL classifies devices into three types, based on whether they contain local memory and how they access memory.
Type 1
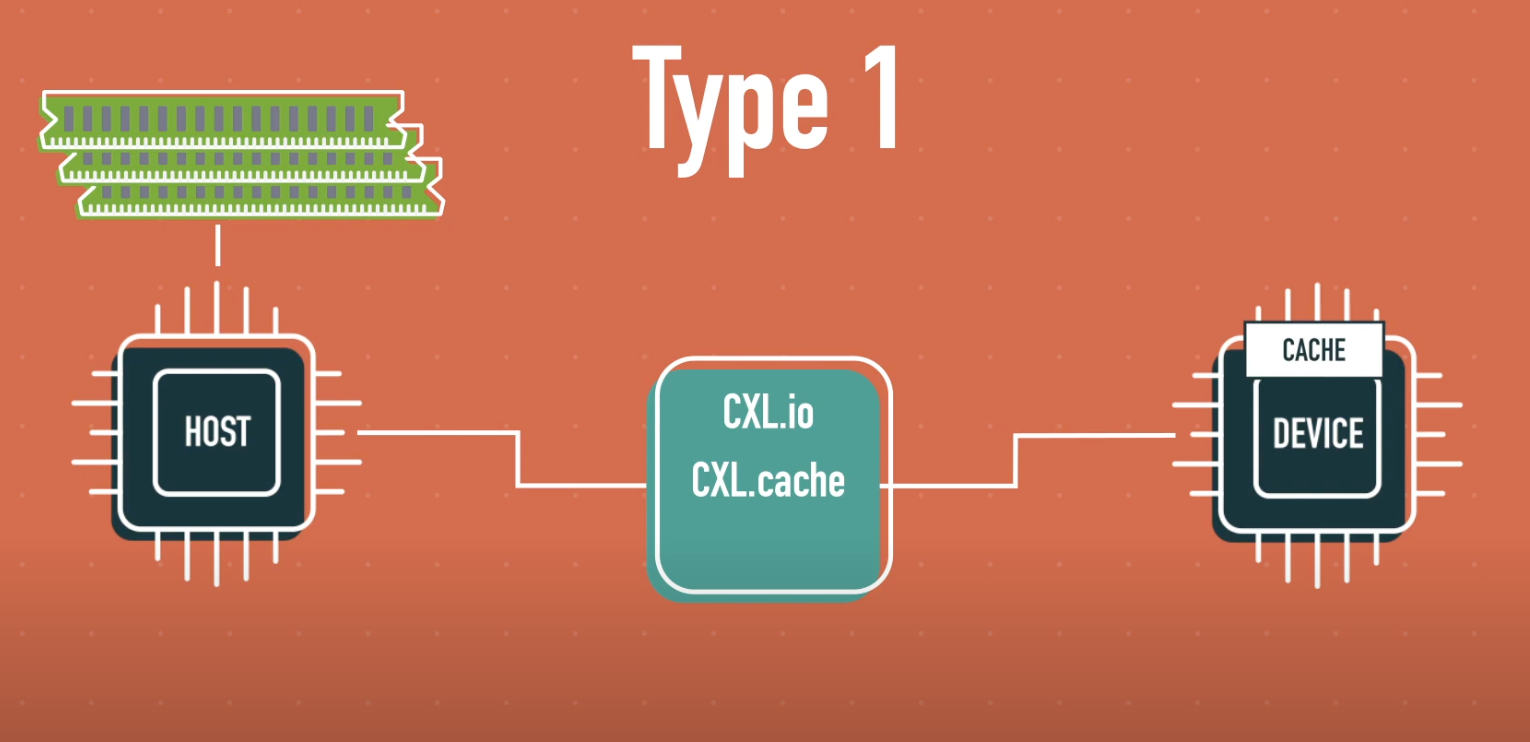
Type 1 devices are accelerators or network devices without local memory, accessing the host’s memory coherently.
Typical examples include network accelerators like PGAS NICs or NIC Atomics, which directly use the host’s DDR memory as buffer pools while maintaining cache coherence.
Type 2
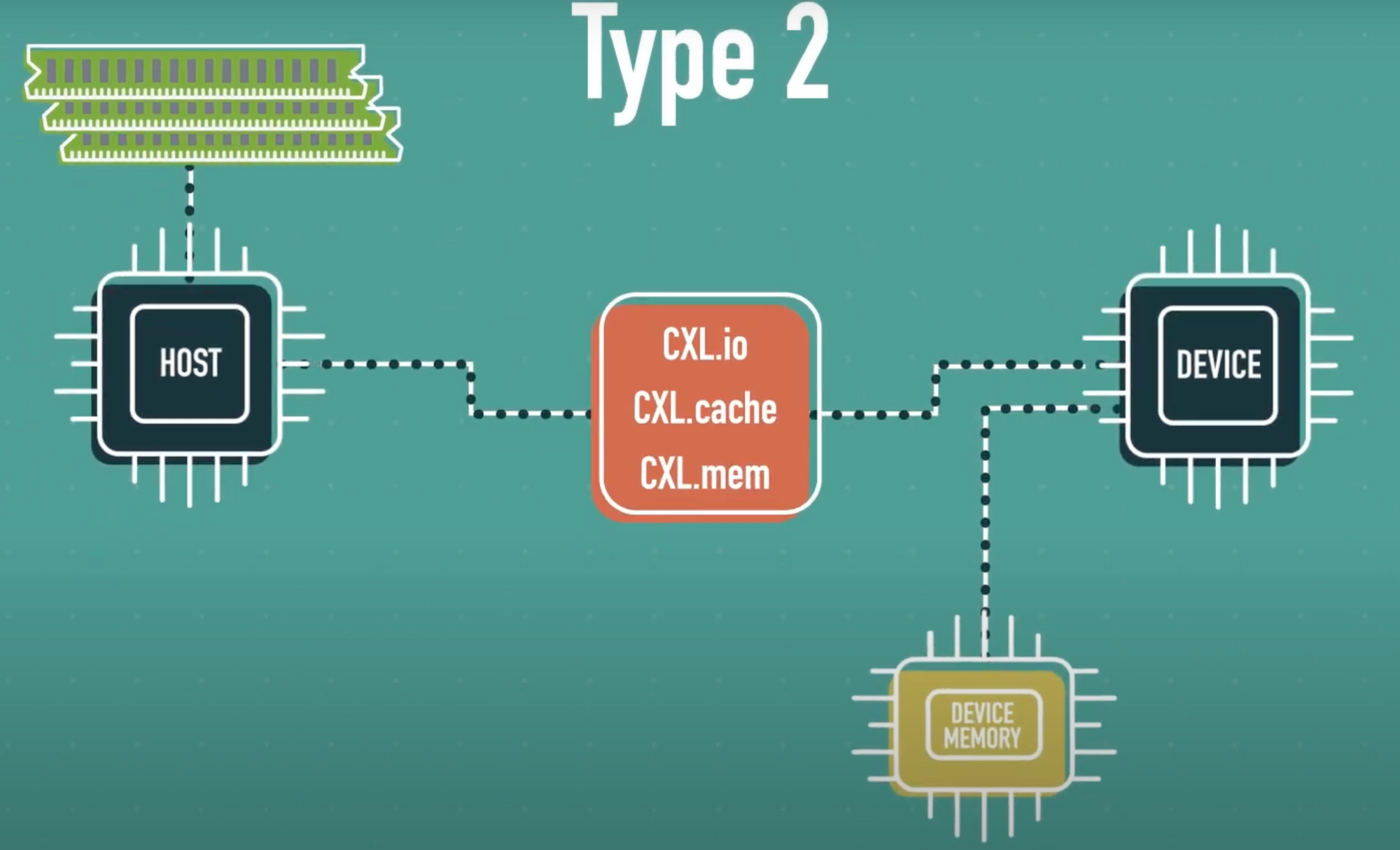
Type 2 devices include GPUs, FPGAs, and AI ASICs that have high-speed local memory (such as HBM or GDDR). These devices support bidirectional coherent memory access between host and device memory.
This enables the CPU and the accelerator to share and manipulate the same data structures, allowing the entire system memory space to function as a unified architecture. For instance, a GPU can directly manipulate data in host RAM, or the CPU can read and write model parameters stored in the GPU’s HBM.
Type 3
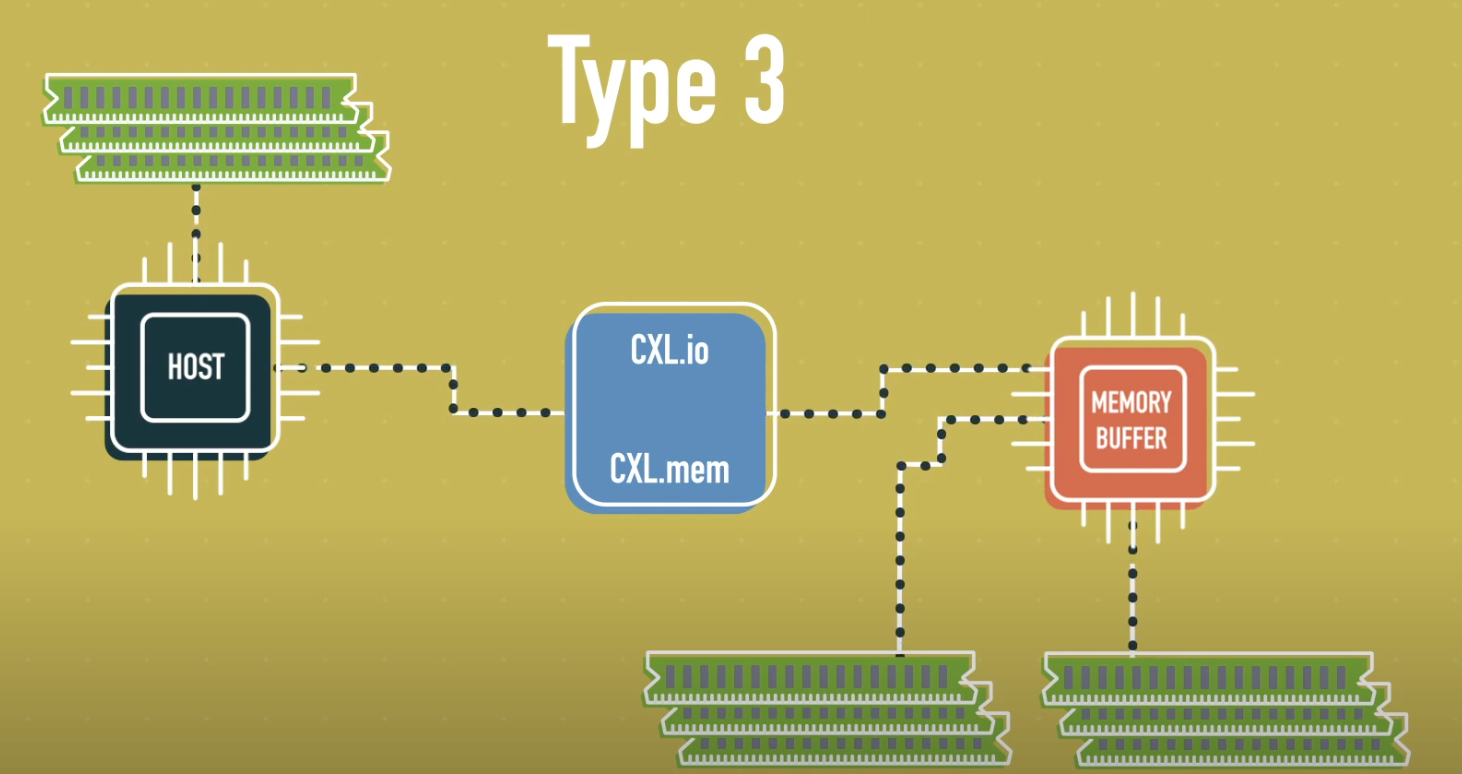
Type 3 devices are designed specifically for memory expansion. They contain only local memory, which the host accesses directly via load/store operations. In contrast, these devices do not need to access the host's memory.
They are typically used as memory expansion modules based on DRAM or NVM and serve to increase the system’s memory capacity and bandwidth. While they behave similarly to PCIe-based memory controllers, CXL provides lower latency and a simpler software stack due to hardware-level coherence support.
1.4 CXL vs PCIe
Although CXL uses the same physical slots and transmission lines as PCIe, its operation and features are fundamentally different.
PCIe has long been used as a standard interface for device initialization, register access, and data transfer, but it does not support cache coherence. Therefore, data sharing between CPU and devices requires a DMA engine, along with complex buffer copying and explicit cache management.
In contrast, CXL supports hardware-level cache coherence. In systems using CXL, accelerators or devices can directly access and cache CPU memory, and the CPU can likewise directly read and write device memory. All accesses maintain cache coherence, allowing programmers to treat device memory as if it were part of the CPU’s internal resources.
In terms of bandwidth, CXL offers performance on par with PCIe. It retains compatibility with existing PCIe infrastructure while delivering additional benefits such as data coherence, memory sharing, and enhanced performance.
This paper introduces a method for expanding server memory using CXL Type 3 devices.
2. The Need for Memory-Centric Systems
Modern database systems are required to process increasingly large volumes of data, which demands more cores and memory resources.
However, it has become increasingly difficult to meet these demands with traditional processor-centric system architectures. In particular, memory bandwidth bottlenecks and low memory utilization have become serious issues in terms of both system efficiency and cost.
2.1 Limitations of Processor-Centric Systems
To date, most systems have been designed based on a processor-centric (CPU-focused) architecture. However, the authors argue that it is now time to consider a memory-centric approach for the following reasons:
- Increasing Core Counts vs. Stagnant Memory Bandwidth
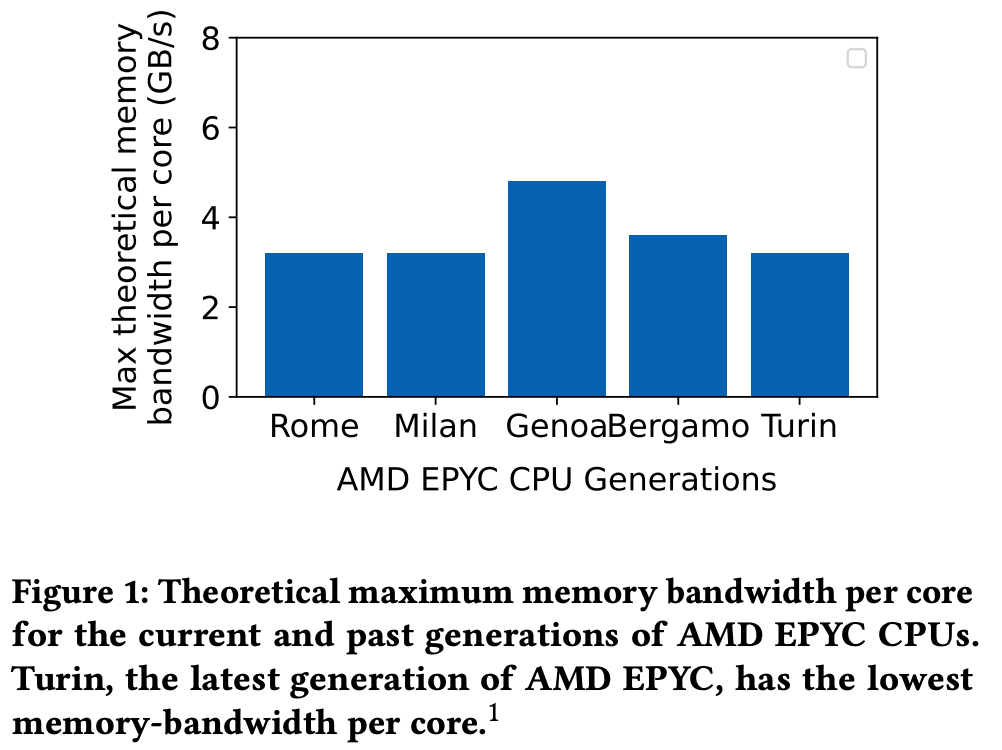
While modern CPUs continue to incorporate more cores, memory bandwidth has not kept pace. As a result, memory-bound workloads suffer from performance degradation, leading to poor overall utilization of system resources.
2. High Cost and Low Utilization of Memory
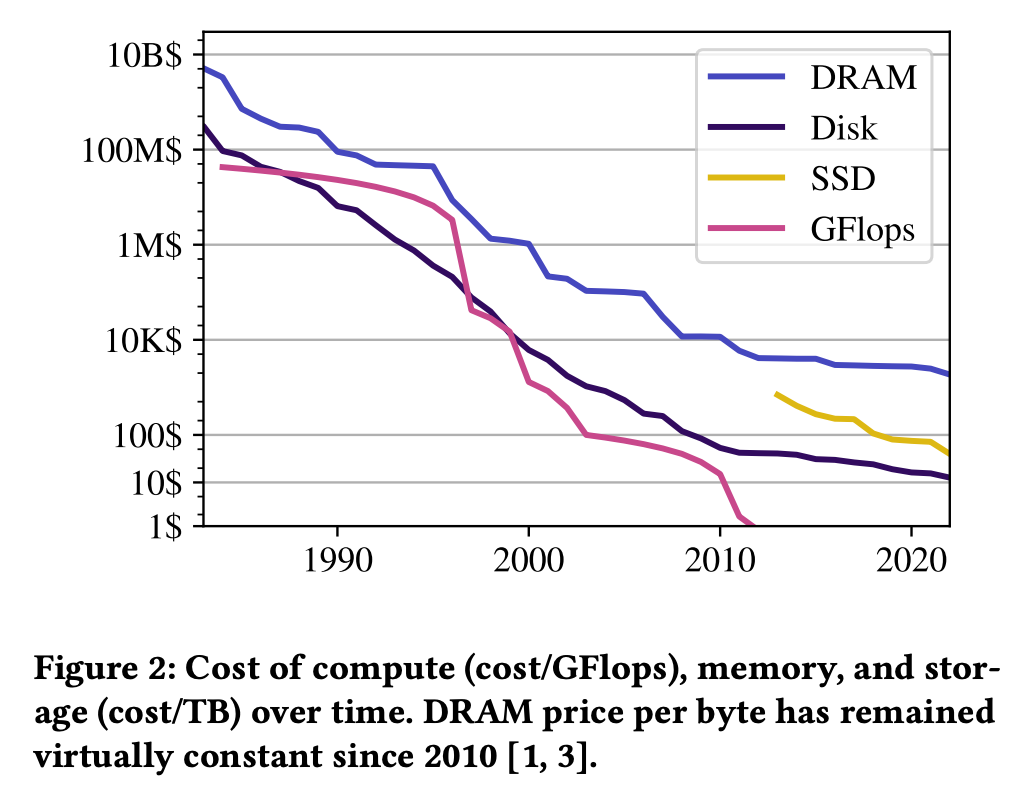
Memory already accounts for a significant portion of server costs, and the cost per byte is no longer dropping rapidly. In cloud environments especially, memory is often underutilized due to vCPU-centric resource allocation models, where memory is statically tied to CPUs in fixed ratios—resulting in inefficiency.
2.2 Memory-Centric Computing
The core idea of Memory-Centric Computing, designed to overcome existing limitations, is as follows:
1. Redesigning the system around memory
Instead of the traditional approach of organizing resources around the CPU, the system is structured around a memory pool, treating computing power as peripheral resources. Various processors—such as CPUs, GPUs, and FPGAs—access the memory pool via a network.
2. Disaggregated memory structure for flexible scalability
By flexibly adding nodes with local DRAM, memory bandwidth and capacity can be scaled independently.
3. Architecture optimized for database systems
Databases are inherently designed to manage memory and data movement efficiently, using out-of-core algorithms and distributed query processing. Leveraging a memory pool allows for more stable performance and a simpler programming model. In particular, technologies like CXL (shared memory) simplify memory abstraction, enhancing developer convenience.
Out-of-core algorithms refer to techniques that process data using disk storage when the dataset does not fit entirely into main memory.
2.3 DBMS Challenges Due to Memory Technology Bottlenecks
As Moore’s Law approaches its limits, chip manufacturers have shifted toward increasing the number of cores to improve performance. However, the memory bandwidth per core has not kept pace. This growing gap between processor speed and main memory access time is known as the Memory Wall.
Due to the Memory Wall, most applications—especially data-centric workloads—are increasingly becoming memory-bound.
In specialized domains like deep neural networks (DNNs), this issue is being addressed through domain-specific architectures (DSAs) such as TPUs or Azure’s Maia. However, DBMSs face a clear limitation due to Amdahl’s Law, as they must support a wide range of functionalities. Parsing, query optimization, transaction processing, disk/memory management, and network processing are all intertwined, meaning DSAs can only accelerate a subset of tasks.
Despite DRAM being one of the most expensive resources, it is typically allocated on a per-CPU basis in cloud environments. As a result, actual memory utilization is low—Microsoft, for example, reports that only about 25% of DRAM is effectively used—leading to significant resource waste.
The Memory Wall is no longer just a latency issue; it has evolved into a multi-dimensional problem involving bandwidth, capacity, and cost. With current system architectures, overcoming this wall requires adding more servers, which in turn leads to exponentially rising costs for scaling database systems.
3. Memory-Centric Architecture of DB
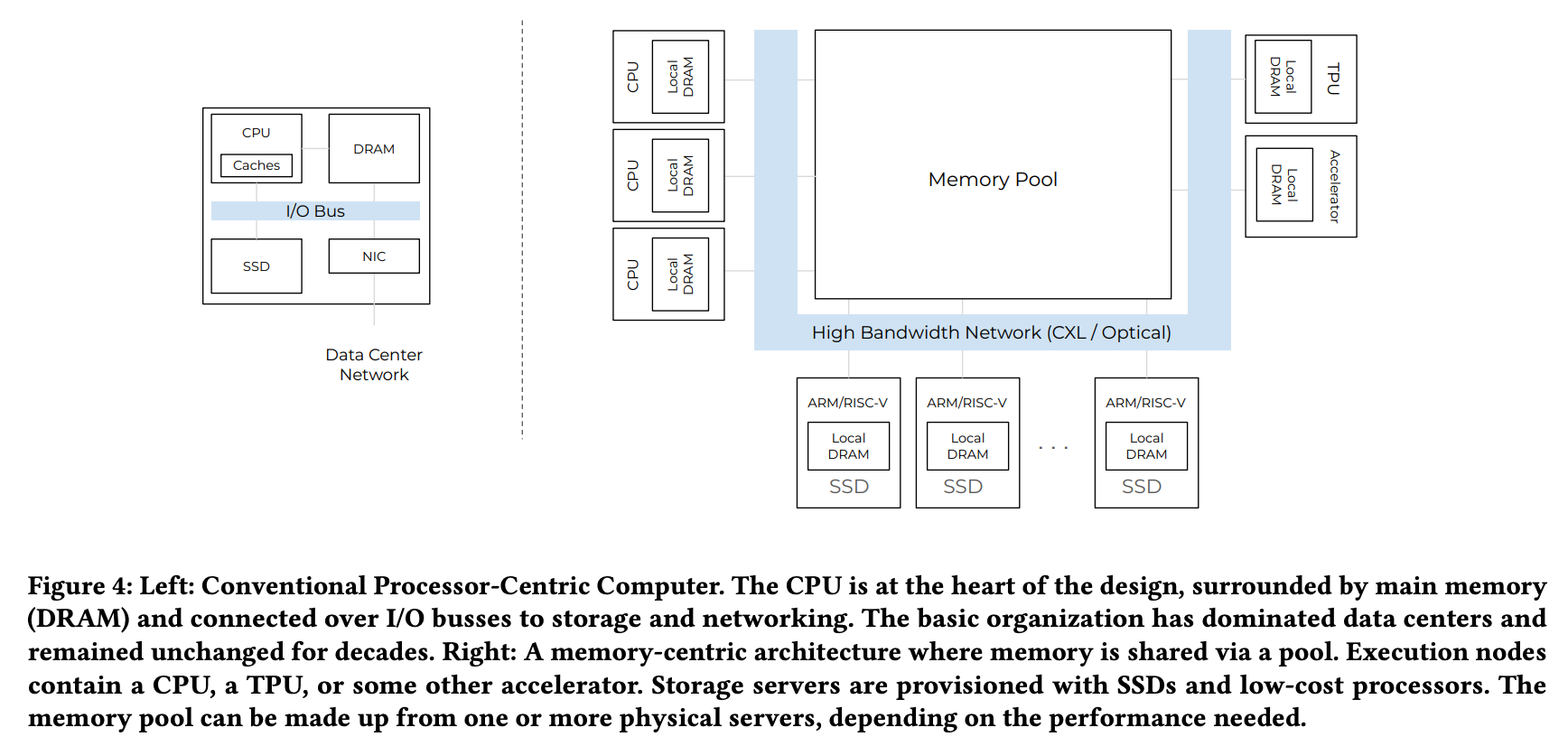
3.1 Memory Pooling
In traditional server architectures, each CPU core is typically assigned a fixed amount of memory. However, Memory-Centric Design takes a different approach. Most memory exists as a shared pool accessed over the network, while individual compute nodes only have small local DRAMs. The actual data resides in a central memory pool.
This memory pool can be shared not only with high-performance processors (Figure 4, left) but also with low-power cores such as ARM and RISC-V (Figure 4, bottom), as well as various hardware accelerators (Figure 4, right). This design helps reduce memory stranding in cloud environments and allows the system to handle complex workloads more efficiently.
From the application’s perspective, the memory pool can supplement local DRAM, or disaggregate memory in distributed systems, improving overall memory efficiency and simplifying the handling of large-scale data exchanges.
For example, Google BigQuery performs fast, large-scale shuffle operations based on distributed memory services, while Microsoft uses RDMA to borrow memory from remote nodes, reducing disk I/O.
Memory pooling is also cost-effective. Cloud providers have traditionally replaced memory every time a new hardware generation is introduced (e.g., DDR4 → DDR5), even though memory can last over 25 years. This was inevitable under the conventional CPU-attached memory model. However, with a CXL-based memory pool, older generation memory can be reused, significantly reducing costs.
3.2 Databases and the Memory Pool
Most applications struggle to manage the memory hierarchy directly, but databases are an exception. A DBMS controls data movement internally and optimizes memory layers through out-of-core algorithms. In distributed query processing, when the working set exceeds local memory, performance suffers. A memory pool allows for flexible handling of overflow data and simplifies data partitioning.
3.3 Memory Pools Reduce Data Movement Costs
One of the biggest costs in distributed queries is data movement. Fetching data from remote storage or transferring it between nodes involves overhead from compression, serialization, buffer copying, format conversions, and more.
By using a memory pool instead of the storage layer, many of these steps can be reduced to simple network-level memory access. Technologies like CXL make the implementation of data movement even simpler.
Modern data pipelines involve multiple types of processors—CPUs, GPUs, TPUs, and others. Previously, local memory constraints of each device created bottlenecks due to constant data copying and movement. In a memory-centric design, all computing devices access the same memory pool at a "equidistant" distance (see Figure 4). This simplifies data sharing between heterogeneous compute units and mitigates memory size bottlenecks across devices.
4. Example Use of a Memory-Centric System: Distributed Join
The paper compares the time and resource consumption required to perform an equi-join, a commonly used operation in distributed environments, under a processor-centric versus a memory-centric system architecture.
A simplified SQL representation of an equi-join is:
SELECT *
FROM table1
JOIN table2
ON table1.common_column = table2.common_column;The experiment uses two tables: R (20GB) and S (100GB), both stored in a distributed storage system.
A hash table is created from the relatively smaller table R, and the join is executed by scanning rows of S using the join key to probe the hash table.
Experimental Setup
- Number of compute nodes: 10
- Network bandwidth: 200 Gbit RDMA (25 GB/s)
- Local DRAM bandwidth: 100 GB/s
- CXL Memory Pool: Used only in the Memory-Centric configuration
- DRAM Join processing speed: 8 GB/s
- CXL Memory Join processing speed: 5 GB/s
Experimental Procedure
- Fetch tables R and S from distributed storage
- Partition both tables and distribute them to compute nodes
- Build a hash table from each partition of R
- Probe the hash table with each tuple of S
4.1 Join Performance in a Processor-Centric Architecture
- Partitioning: Each of the 10 compute nodes holds a 2GB partition of R. Time: 2GB / 100GB/s = 0.02s
- Shuffling: 0.2GB is retained, and the remaining 1.8GB is shuffled to other nodes. Time: 1.8GB / 25GB/s = 0.072s
- Data Skew Scenario: Server 1 receives a 5GB partition of R, Server 2 receives 2GB, Remaining servers each receive 1.625GB
- Hash Table Build Time: Based on the largest partition (5GB on Server 1): Time: 5GB / 8GB/s = 0.625s
- Probing Time: Total probing data = 10GB (1/10th of S). Time: 10GB / 8GB/s = 1.25s
Total Time: 0.02 + 0.072 + 0.625 + 1.25 = 1.967s
Memory Requirement: Each node requires 5.5GB (5GB partition + 0.5GB buffer). Total = 55GB
4.2 Join Performance in a Memory-Centric Architecture
Same 10-node setup, but each node has 3GB of local memory and access to a CXL-connected memory pool.
- Partitioning: Same as processor-centric: 0.092s
- Handling Data Skew: Server 1 cannot store the full 5GB R partition in 3GB local memory → Borrows 2.5GB from CXL memory
- Hash Table Build Time: 2.5GB in local memory: 2.5GB / 8GB/s, 2.5GB in CXL memory: 2.5GB / 5GB/s. Time: 0.3125 + 0.5 = 0.8125s
- Probe Time: 5GB total probing, 2.5GB local: 2.5GB / 8GB/s, 2.5GB CXL: 2.5GB / 5GB/s. Time: 0.3125 + 0.5 = 0.8125s
Total Time: 0.092 + 0.8125 + 1.625 = 2.5295s
Memory Requirement: Each node uses 3GB local memory. Total of 2.5GB from the memory pool → 32.5GB total memory
Summary
Processor-Centric:
- Time: 1.967s
- Memory: 55GB
Memory-Centric:
- Time: 2.5295s
- Memory: 32.5GB
Despite the slightly higher execution time, the memory-centric architecture significantly reduces memory usage, enabling better scalability and cost efficiency, especially in memory-constrained environments.
5. Conclusion
Comparing Sections 4.1 and 4.2, the Memory-Centric architecture sacrifices about 20% more execution time but saves approximately 70% of memory usage. While there is a slight performance trade-off, this approach may prove more stable in cloud and large-scale data processing environments.
In real-world deployments, services often allocate far more memory than they usually use to handle temporary memory spikes. In this context, using a memory pool can be a far more cost-effective solution.
The paper explains that the Memory-Centric architecture can be implemented in various ways, with memory pooling being just one such method. As further research continues, it’s likely we’ll see even more advanced designs emerge.
After reading this paper, I came to believe that Memory-Centric design might be adopted faster than expected. As the paper points out, Memory-Centric architecture is essentially a logical reorganization of components in traditional Processor-Centric systems. Since it doesn’t necessarily require introducing new hardware components, the cost burden of architectural changes may be lower from a company’s perspective.
Of course, to fully leverage such architectures, technologies like CXL—mentioned multiple times in the paper—need to be adopted at the data center level. If global cloud providers confirm that adopting CXL reduces costs, as suggested in the paper, then Memory-Centric design could spread faster than anticipated.
Going forward, I plan to keep an eye on follow-up studies to see how this architecture evolves and consider how application developers should adapt to these changes.
Reference
Databases in the Era of Memory-Centric Computing (2025)