
Exploring the Use of Paxos and TrueTime in Google Spanner

[Summary]
- Paxos is a consensus algorithm used in distributed systems, often seen as an extension of the two-phase commit protocol (2PC).
- Spanner utilizes a leader-based Paxos with leases.
- TrueTime in Spanner is a globally synchronized clock with bounded uncertainty, aiding in determining the order of events.
- Through TrueTime, Spanner provides external consistency and Multi-Version Concurrency Control (MVCC).
[Table of Contents]
- Two-Phase Commit (2PC)
- Paxos
- Paxos in Spanner
- TrueTime and MVCC in Spanner
Based on "Spanner: Google's Globally Distributed Database" (2013) and "Spanner, TrueTime, and the CAP Theorem" (2017), this document aims to summarize foundational concepts necessary for understanding the Spanner system and delve into Spanner's use of TrueTime.
Spanner is a globally distributed database developed by Google. It is utilized by various Google services, including the advertising backend (F1), Gmail, Google Photos, and is available for public use via Google Cloud.
Despite sharding data across data centers worldwide, Spanner maintains consistency and avoids partitioning. According to the CAP theorem, Spanner is categorized as a CP (Consistent and Partition-tolerant) system. However, due to its exceptional availability—1 failure in 10^5—it also meets the criteria for high availability.
To maintain consistency, Spanner introduces TrueTime, a globally synchronized clock. No matter how fast the network becomes, the round-trip time across continents remains around 10 milliseconds (Google defines a region as having a 2ms round-trip time). Ordering a high volume of transactions over wide areas is generally challenging, but Spanner successfully achieves external consistency through TrueTime.
Like many distributed databases, Spanner employs the two-phase commit protocol (2PC) and Paxos consensus algorithm. Although the RAFT algorithm was not available at the time, Spanner uses a modified version of Paxos with leader leases to enhance performance. The combination of 2PC and Paxos ensures that consistency is maintained even in partition scenarios.
This document explores TrueTime and Paxos in Spanner. Before diving into Spanner, let's briefly outline the concepts of 2PC and Paxos.
2PC
The Two-Phase Commit (2PC) protocol is a distributed algorithm designed to achieve atomic transaction commits across multiple nodes. It ensures that a transaction either commits on all nodes or aborts on all nodes, thereby maintaining consistency and integrity in a distributed system.
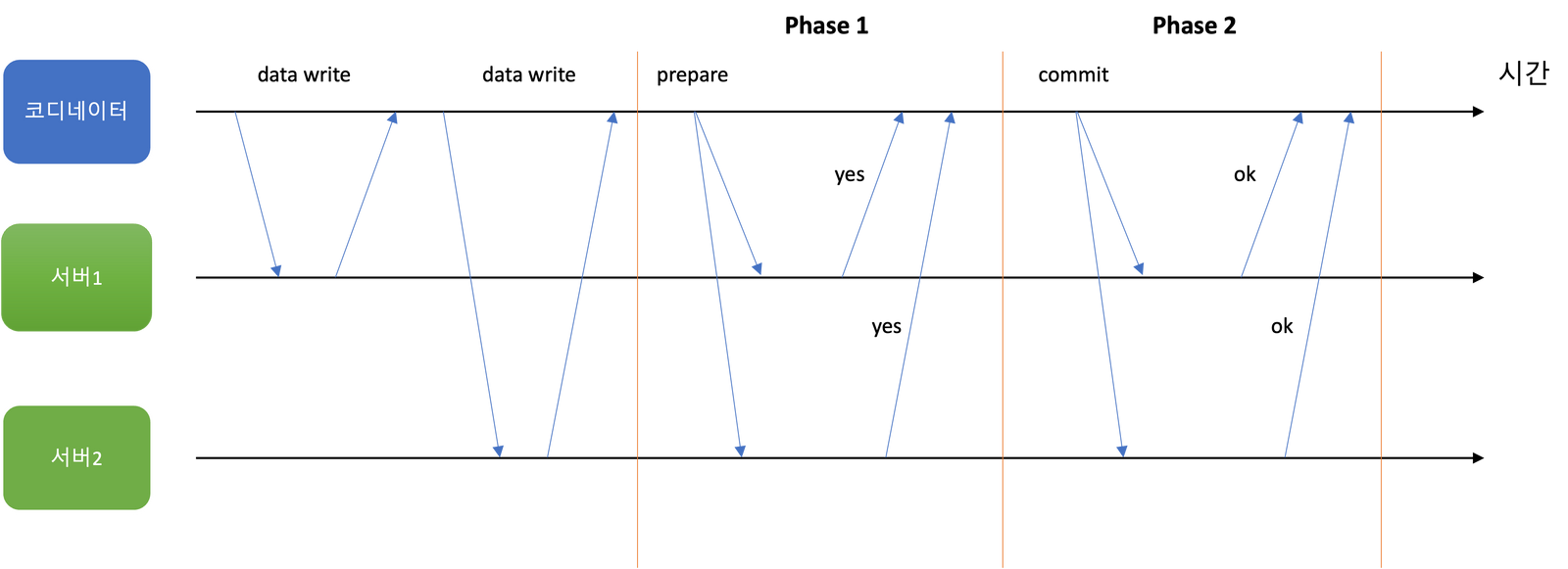
In 2PC, there is a component known as the coordinator, which is not typically present in single-node transactions. Before initiating 2PC, the application requests a unique transaction ID from the coordinator. This ID must be unique to ensure proper tracking and management of the transaction. Using this transaction ID, the application sends write requests to the respective servers. If any server crashes or encounters an issue during this stage, either the coordinator or the server can abort the request.
Once the coordinator has received write request responses from all servers, Phase 1 of 2PC begins.
Phase 1
- Prepare: The coordinator sends a prepare request tagged with a transaction ID to all servers. If any of these requests fail, the coordinator sends an abort request to all servers.
- Promise: Servers that receive the request verify whether the transaction can be committed. They check for factors such as the ability to write data to disk (including checking disk space), conflicts, and constraint violations. If a server responds with an "ok" to the coordinator, it promises to commit but does not commit yet.
Phase 2
- The coordinator receives responses from all requests and decides whether to commit or abort the transaction. If the coordinator crashes, 2PC halts and cannot proceed further. The coordinator records its decision in the transaction log on disk (commit point) to ensure it can continue 2PC after a restart.
- Accept: When the coordinator records the commit point, it sends commit or abort requests to all servers. Since the commit point is recorded, the coordinator retries the requests until they succeed, even if initial attempts fail.
- Accepted: When servers receive a commit request, they commit; if they receive an abort request, they abort.
In 2PC, the coordinator plays a crucial role. Once servers respond "ok" to the prepare request, they cannot unilaterally abort. Servers must wait until the coordinator makes a decision and sends a response. If the coordinator crashes or there is a network failure, servers must keep waiting. Unilateral aborts by servers could lead to inconsistent decisions among them.
2PC ensures the stability of distributed transactions but reduces performance. Forced disk writes (fsync) and the time consumed by additional requests slow down the transaction speed.
Paxos
Paxos is a consensus algorithm used in distributed systems. It was proposed by Lamport in 1989 and was widely used until RAFT emerged in 2014.
The Paxos algorithm must satisfy the following:
- Safety: Only a single value can be chosen, and servers must not learn that value until it is selected.
- Liveness: Some of the proposed values will eventually be chosen. Servers will eventually hold the chosen value.
The basic components of Paxos are divided into proposers and acceptors.
- Proposer: Proposes values to acceptors and handles client requests.
- Acceptor: Responds to messages received from proposers and stores the chosen value.
Paxos can be seen as an extension of the 2PC algorithm, and its operation is very similar. Each round of Paxos consists of two phases.
Phase 1
- Prepare: The proposer creates a message with an identifier number N. This number N must be greater than any number used in previous messages sent by the proposer. This message must be sent to a quorum of acceptors.
- Promise: When an acceptor receives the Prepare message, it checks the number N. If N is less than the number in any previous message it received, it ignores the message (it may also send a rejection message depending on the implementation). Otherwise, it responds with a Promise message. If the acceptor has previously received a message, it includes that message's number in its response.
Phase 2
- Accept: If the proposer receives Promises from a quorum, it assigns a value v to the message. If the acceptor had responded with a previous value, the proposer selects the value associated with the highest identifier number and assigns that value. The proposer then creates an Accept message including the number and the value and sends it to the acceptors.
- Accepted: When the acceptor receives the Accept message from the proposer, it must accept the value as long as it has not already made a promise to another message with a higher number.
Let's look at an example of Basic Paxos.
Case 1

When Server 5 makes a proposal, it receives value X from Server 3. Although it originally intended to propose value Y, it changes the proposal to X. As a result, all servers accept value X.
Case 2

Unlike Case 1, Server 5 makes a proposal before Server 3's acceptance. Server 3 rejects value X because it is older compared to Y. Since the majority of servers have chosen Y, value Y is selected instead of X, which was selected in Case 1.
2PC vs Paxos
What are the differences between Paxos and 2PC? While their operations are similar, 2PC requires agreement from all participants, whereas Paxos only needs agreement from a quorum. Another difference is that Paxos uses identifiers to determine the order of requests.
A key difference is that if the coordinator fails in 2PC, the process halts. In Paxos, there is no single coordinator; even if a proposer fails, the acceptors retain the state, allowing other acceptors to take over. This post provides a brief overview of Paxos. For a more detailed explanation, it is recommended to read "Consensus on Transaction Commit" by Lamport, who proposed Paxos.
Paxos in Spanner
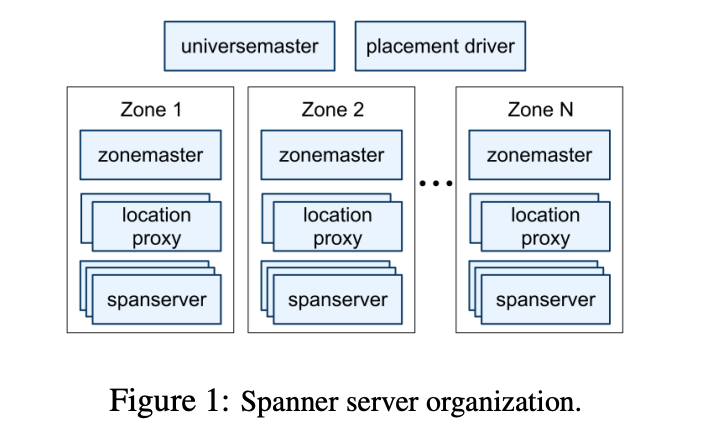
Spanner is organized by zones. Each piece of data is replicated at the zone level, and zones can be added or removed from the running system. Additionally, zones are physically separate units.
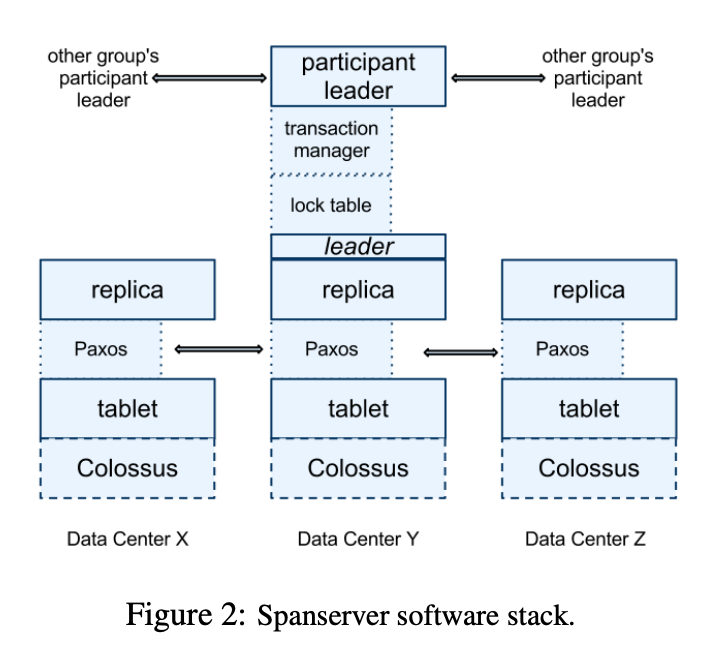
Each zone contains hundreds to thousands of spanservers, and each spanserver manages 100 to 1000 tablets. A tablet is a data structure that implements a mapping from (key: string, timestamp: int64) to string.
To support replication, each spanserver implements a Paxos state machine for each tablet. A replica set is managed as a single Paxos group.
When processing distributed transactions that involve more than one Paxos group, the leader of each group performs 2PC. 2PC requires all participants to operate correctly. By setting the participant unit as a Paxos group, Spanner allows 2PC to proceed even if some nodes fail.
While Paxos allows for multiple proposers, it is more efficient to have a single proposer to avoid conflicts. When there is a single proposer, it is called the leader. If the leader handles the transaction, phase 1 of Paxos can be skipped as the leader can order events sequentially using identifiers.
Spanner also uses leader-based Paxos. Here, the concept of a lease comes into play. A leader candidate requests timed lease votes from participants. If the candidate receives votes from a quorum, it recognizes itself as having the lease and becomes the leader. As the lease expiration approaches, the leader requests an extension from the participants. In Spanner, the lease duration is typically 10 seconds.
When using leader-based Paxos, it is crucial to ensure the monotonicity of transactions between leaders. This means that transactions sent by the current leader must apply after those sent by the previous leader. When a leader fails, there are two options:
- Wait for the lease to expire and elect a new leader.
- Restart the failed leader.
As an optimization, a "last gasp" UDP packet can be sent to participants to shorten the lease expiration time in the event of certain failures.
This approach ensures that leases maintain monotonicity between leaders and allow participants to perform read operations even in the absence of a leader.
Introducing leases into Paxos underscores the importance of monotonicity. Without a proper event order, issues like overwriting current values with previous ones or reading outdated values can occur. One solution to this problem is assigning precise timestamps to each event. The next chapter will explore Spanner's TrueTime mechanism for determining timestamps.
TrueTime and MVCC in Spanner
Earlier, we discussed Paxos as a consensus algorithm, which ensures that servers in a distributed system achieve the same state.
One of the major issues in distributed systems is determining the order of events.
Consider two requests: request A sets variable x to 1, and request B sets variable x to 2. If server 1 receives requests in the order A then B, while server 2 receives them in the order B then A, the value of x on server 1 and server 2 may differ.
If we could accurately know the commit timestamp of each transaction, we could always correctly order transactions. However, each server's perception of time is not precise.
Let's look at some examples from Designing Data-Intensive Applications:
- Server clocks experience drift (running faster or slower), influenced by factors like temperature. Google assumes 200ppm drift on their servers (approximately 6ms every 30 seconds).
- NTP synchronization is limited by network delays and may not provide perfect accuracy.
- Leap seconds can disrupt systems that do not account for them, potentially causing clock failures.
- Virtualized environments introduce additional complexities with virtualized hardware clocks.
Spanner uses TrueTime, a globally synchronized clock with bounded error. When calling the TrueTime API, Spanner receives a [earliest, latest] timestamp range indicating the possible range of timestamps.

If the timestamp ranges of two transactions do not overlap, it is possible to determine their order. However, if they do overlap, determining the order becomes impossible, so it is not a perfect solution. Nevertheless, a simple resolution is possible: the leader in Paxos waits to ensure that the intervals of transactions do not overlap before committing.
TrueTime's Time Source

TrueTime is based on GPS and atomic clocks deployed across all Google data centers. Because these two sources have different failure conditions, they can provide relatively accurate time reliably. GPS can be affected by factors such as antennas, local radio signals, and the GPS system itself, whereas atomic clocks can experience frequency errors.
Each data center has a set of time master machines. Most masters have GPS receivers and antennas, physically separated to minimize mutual influence. The remaining master nodes(Amagettō nodes) have atomic clocks. Each master compares its local clock with the other master nodes, and if discrepancies are significant, it excludes itself from the master set.
Servers obtain time from various masters such as the GPS master selected from nearby centers, GPS masters from distant data centers, and Amagettō masters. Using a variant of the Marzullo algorithm, servers reject incorrect times and synchronize their local clocks. The synchronization interval for servers averages about 30 seconds, and considering Google's assumed drift rate of 200 microseconds per second, errors up to 6 milliseconds can occur.
External Consistency and MVCC
External consistency is the strictest form of transaction concurrency control. In a distributed system that satisfies external consistency, all transactions appear to execute sequentially across multiple servers. Spanner achieves external consistency, making it indistinguishable for users from a single-machine database.
Traditional databases that satisfy external consistency use single-version storage and two-phase locking (2PL). One drawback of 2PL is that it prevents read transactions from accessing objects being modified by write transactions.
MVCC manages multiple versions, allowing read transactions to proceed independently of write transactions. However, implementing MVCC becomes challenging without a monotonic increasing timestamp. Consider a banking system scenario involving deposit transactions, withdrawal transactions, and balance read transactions. If the timestamp of the machine handling the withdrawal transaction is earlier than that of the deposit transaction, querying the balance might only reflect the withdrawal transaction.
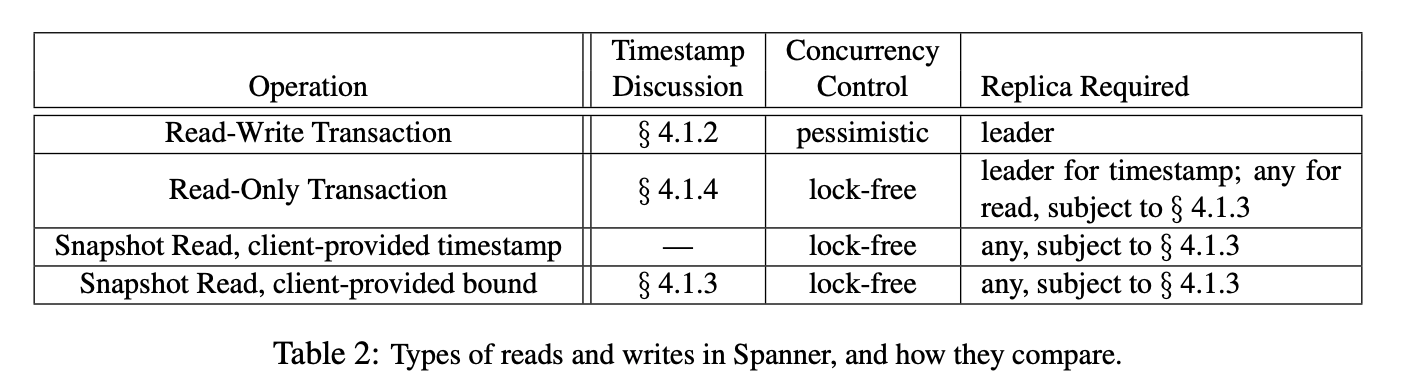
Spanner supports MVCC (Multi-version concurrency control) using monotonic increasing timestamps provided by TrueTime. Therefore, read transactions in Spanner do not require locks. Write transactions create a new snapshot using their own timestamp as the version. Read transactions read the latest version among versions prior to the timestamp assigned to the read transaction. However, it is crucial that the replica where the read transaction executes has been adequately updated.
Spanner determines whether a replica can execute a read transaction by verifying the updated timestamp of the replica. If the timestamp of the read transaction is less than the timestamp of the replica, the read transaction can proceed.
Conclusion
This article has focused on concepts such as Paxos, 2PC, and MVCC as used by Spanner rather than on Spanner itself. For those interested in a detailed understanding of Spanner's implementation, I recommend reading "Spanner: Google's Globally-Distributed Database".
I hope these concepts covered in this article have been somewhat helpful to those interested in distributed systems.
Reference
Spanner: Google's Globally-Distributed Database
Spanner, TrueTime and the CAP Theorem