
[Paper review] REFRAG: Encoding/Decoding for RAG Optimization
![[Paper review] REFRAG: Encoding/Decoding for RAG Optimization](https://images.unsplash.com/photo-1722936598143-40ea5da94dfd?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDJ8fGVuY29kZXJ8ZW58MHx8fHwxNzY2MjM3NDE0fDA&ixlib=rb-4.1.0&q=80&w=2000)
This article reviews the paper REFRAG: Rethinking RAG based Decoding.
RAG is one of the first methods considered when applying LLMs to services. The key advantage of RAG is its ability to leverage domain knowledge without model fine-tuning.
However, as the knowledge base grows, longer contexts must be fed as input, leading to high latency and memory consumption. In production environments, this overhead becomes a significant bottleneck.
The paper we're introducing today, REFRAG, published by Meta, presents a method to reduce computational and memory overhead by compressing RAG contexts. It achieves up to 30x improvement in TTFT (Time To First Token) without perplexity loss—a 3x improvement even compared to previous state-of-the-art techniques.
However, REFRAG requires training both a separate encoder and decoder (decoder-only foundation model). While it doesn't require changing the LLM architecture or adding new decoder parameters, the need for a training process means it may not be immediately applicable to production services.
Nevertheless, there are two reasons why this paper is worth reviewing. First, the paper presents RAG's problems and solutions in a logically coherent flow, making it an excellent learning resource for those unfamiliar with RAG. Second, it demonstrates an industry trend toward training specialized models for RAG optimization. It's remarkable that such optimization techniques are already emerging when RAG was just being adopted as recently as 2024.
For readers unfamiliar with the inference process of decoder-only models, we'll first examine how models process input tokens before diving into the paper's content.
Why TTFT in LLM Models Increases Quadratically with Context Length
To understand RAG's performance issues, we first need to understand how LLMs generate their first token.
Decoder-only Transformer Architecture
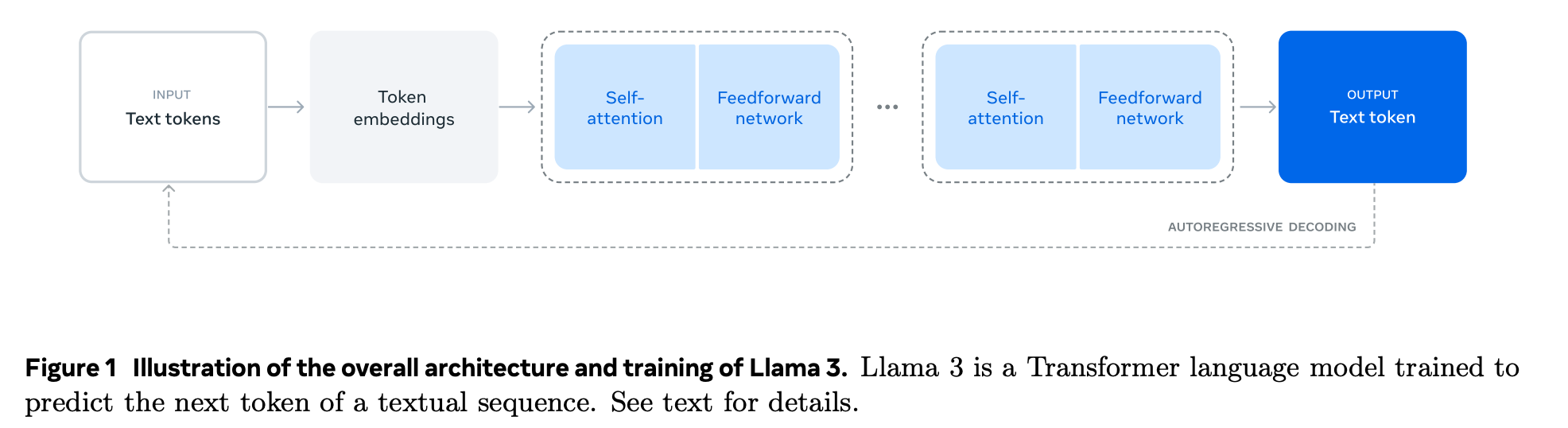
Most modern LLMs (LLaMA, GPT, etc.) use a decoder-only Transformer architecture. This structure receives an input token sequence, processes it through multiple Transformer block layers, and generates tokens.
The input token sequence consists of:
- User query
- System prompt
- Retrieved tokens (in the case of RAG)
Each Transformer block typically comprises the following components:
- Masked Self-Attention
- Feed-Forward Network (FFN)
- Residual Connection and Normalization
Autoregressive Generation Method
Decoder-only LLMs are described as "autoregressive." This means they generate tokens sequentially, one at a time, based on previously generated tokens.
To generate the first token, all input tokens must be processed—a phase called the prefill stage. Since computations across all Transformer blocks must be completed for the entire input sequence, it takes relatively long to output the first token.
The time it takes to output the first token is called TTFT (Time To First Token).
After the first token is generated, subsequent token generation is relatively fast because it leverages the KV cache, which stores Key-Value pairs calculated during the prefill stage.
O(N²) Complexity of Self-Attention
The bottleneck in the prefill stage is the self-attention operation within Transformer blocks.
Let's say the number of input tokens is N and the hidden dimension is d:
- Query (Q) and Key (K) each have dimensions (N × d)
- Attention is computed as Q × K^T (transpose of K)
- The computational complexity of this matrix multiplication is O(N² × d)
In other words, the cost of Self-Attention is proportional to the square of the number of input tokens.
Therefore, as more tokens are input, the self-attention cost increases, and TTFT rises accordingly.
REFRAG: Reducing TTFT Through Context Compression
Now you should understand why long contexts increase TTFT. In RAG, this problem is even more pronounced because retrieved passages are much larger than the user's query.
The REFRAG paper identifies several additional problems in RAG that negatively impact TTFT:
- Unnecessary Token Allocation: RAG contains sparse information, making most passages unnecessary.
- Wasted Encoding: During RAG's retrieval process, context chunks are already preprocessed. Additionally, during vectorization and reranking, each chunk's encoding and correlation information with the query have already been computed. However, this information goes unused during the decoding process.
- Inefficient Sparse Attention: Most context chunks are irrelevant during decoding. Consequently, cross-attention between chunks becomes mostly zero, which is inefficient.
REFRAG proposes a method of feeding compressed chunk embeddings into the decoder instead of using retrieved passages directly.
- Reuse pre-computed embeddings: Eliminates unnecessary computations by reusing chunk embeddings already calculated during the retrieval process.
- Reduce input length: Decreases the decoder's input length.
- Lower attention complexity: Reduces attention computation complexity to be proportional to the square of the number of chunks (C) rather than the square of the number of tokens (N) in the context.
REFRAG Model Architecture
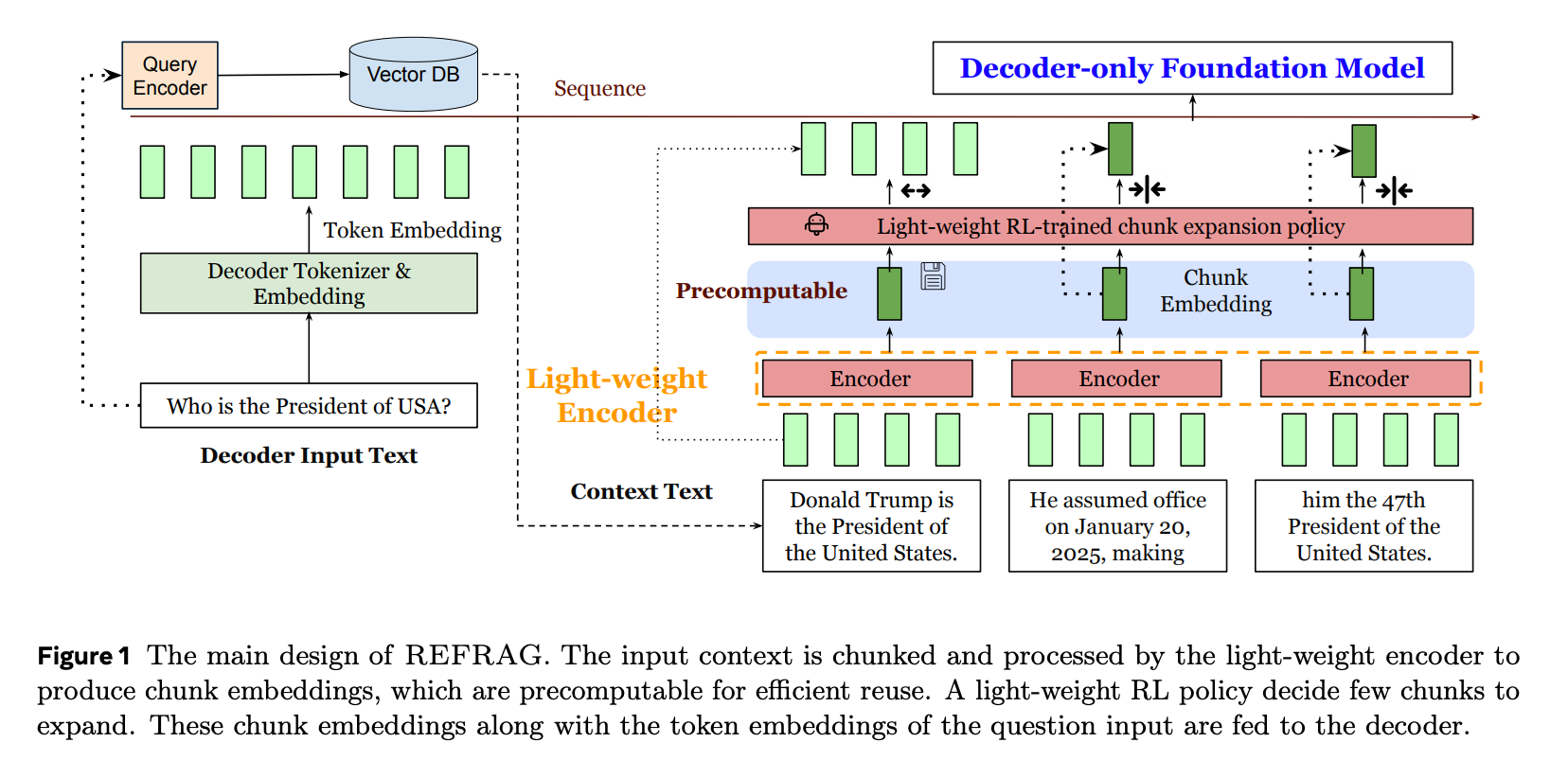
Let's examine REFRAG's structure along with its mathematical formulation.
Input Configuration
- T: Total number of input tokens
- q: Main input tokens (query tokens)
- s: Context tokens (RAG)
- T = q + s
Chunking and Encoding
Context tokens (s tokens) are divided into L chunks: L = s/k (where k is the size of each chunk)
The encoder model processes all chunks to generate an embedding for each chunk. These chunk embeddings pass through a projection layer to be transformed to match the token embedding dimension of the decoder model.
Decoder Input and Generation
The projected chunk embeddings are fed into the decoder model along with the main input tokens (query) to generate the answer. The generated answer y can be expressed as:
y = M_dec({e₁, e₂, …, e_q, e₁_chunk, …, e_L_chunk})
- M_dec: Decoder model
- e_i: Embedding of token x_i
- e_j_chunk: Embedding of the j-th chunk
Key Insight: Input Length Reduction
In RAG, typically s >> q - that is, context tokens far outnumber query tokens.
- Decoder input length in traditional RAG: q + s
- Decoder input length in REFRAG: q + L = q + s/k
Since the context comprises the majority of the total input, the overall input size fed into the decoder is reduced by approximately k times.
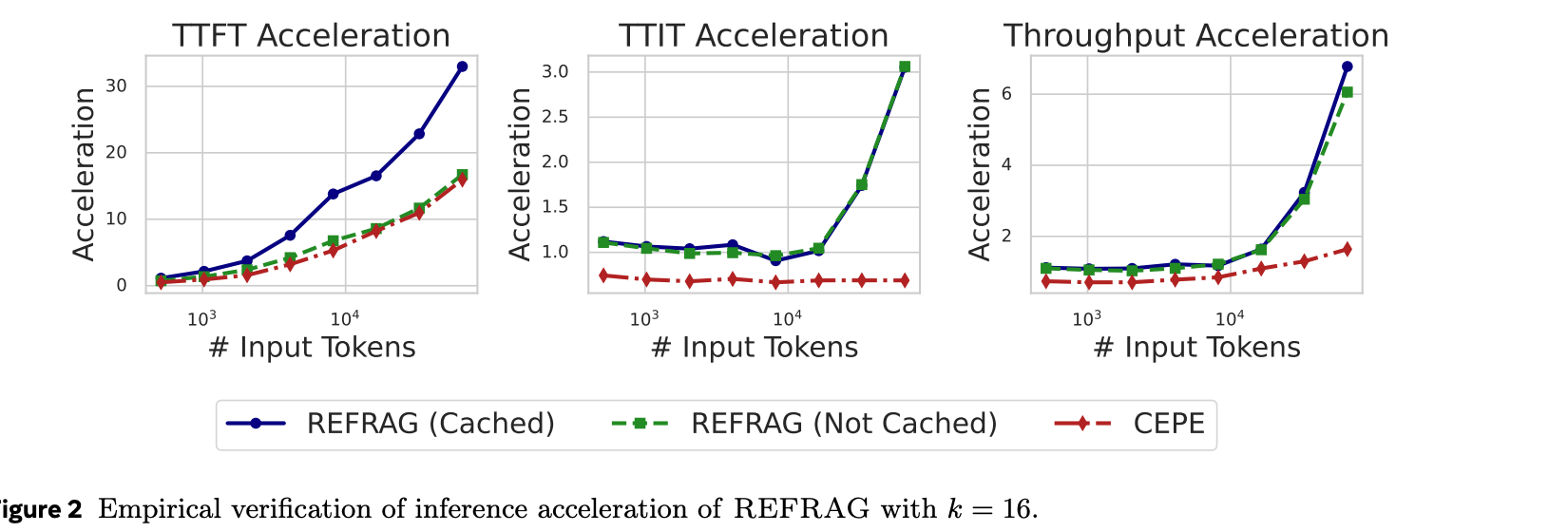
The graph above shows the evaluation results when k=16.
In the case of REFRAG (cache), chunk embeddings are cached. (While not detailed in the paper, it's likely that the chunk embeddings used during retrieval are reused.)
The baseline comparison, CEPE, is the previous SOTA model with similar characteristics to REFRAG.
We can confirm that REFRAG demonstrates superior performance compared to CEPE across all metrics: TTFT, TTIT (subsequent token generation time), and throughput.
Methodology: How to Train the Model?
REFRAG trains the model in two stages: CPT (Continual Pre-Training) and SFT (Supervised Fine-Tuning).
The models to be trained are the encoder model for compressing context and the decoder model (foundation model) that will use that context.
First, the input T tokens are divided into s + o:
- s: Context tokens to be input to the encoder
- o: Output tokens to be predicted by the decoder
In the CPT stage, the first s tokens are input to the encoder, and the encoder output is passed to the decoder to learn to predict the next o tokens. Through this, the model gains the ability to predict the next paragraph using compressed context information.
The goal of the CPT stage is to generate compressed contexts that perform similarly to conventional decoders using full context.
In the SFT stage, the model is adapted to specific downstream tasks such as RAG or multi-turn conversation.
CPT (Continual Pre-Training)
CPT consists of three techniques:
1. Reconstruction Task
The purpose of the reconstruction task is to align the encoder and projection layer with the decoder.
The first s tokens are input to the encoder, and the decoder learns to reconstruct the original s tokens. During this process, the decoder model is frozen (not trained), and only the encoder and projection layer are trained.
Through training, the encoder minimizes information loss when compressing k tokens, and the projection layer efficiently maps chunk embeddings to the decoder token space. It also has the effect of encouraging the model to rely on contextual information rather than knowledge memorized during training.
2. Curriculum Learning
The Reconstruction Task in step 1 has a problem. When the chunk length is k, the possible token combinations grow to V^k (where V is the vocabulary size). Representing this with fixed-length embeddings is difficult. If reconstructing a single chunk is already challenging, reconstructing s = k × L tokens (L chunks) all at once is even more difficult.
The paper states that directly pre-training the decoder to process encoder outputs alone does not improve perplexity, and proposes Curriculum Learning as an alternative.
Curriculum Learning is a method that gradually increases task difficulty so the model can acquire capabilities step by step.
It starts with single chunk reconstruction (1 chunk embedding → k token generation). After sufficient training, it moves to 2-chunk reconstruction (2 chunk embeddings → 2k token generation), progressively expanding to L chunks.
3. Selective Compression
This is a method of selectively decompressing important context chunks to improve prediction accuracy. Using RL (Reinforcement Learning), the model learns which chunks to use as original chunks by setting the perplexity of the next paragraph as a negative reward.
To enable this, the encoder and decoder are trained to handle inputs mixed with both compressed and uncompressed chunks.
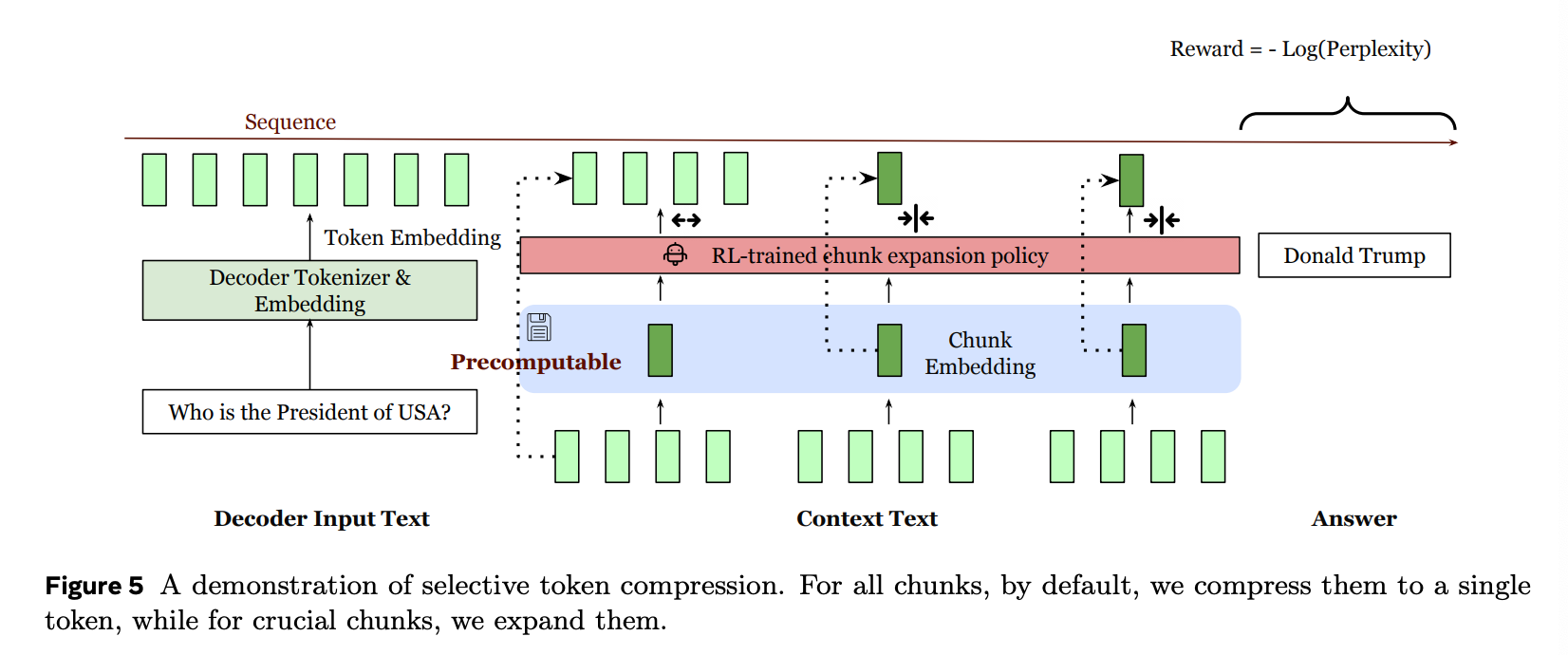
The paper notes that different learning rates were used for the reconstruction stage and the next paragraph prediction stage.
The reconstruction stage uses a higher learning rate compared to paragraph prediction. This is because the reconstruction stage trains only the encoder model, while paragraph prediction trains all parameters including the decoder model.
Evaluation Results
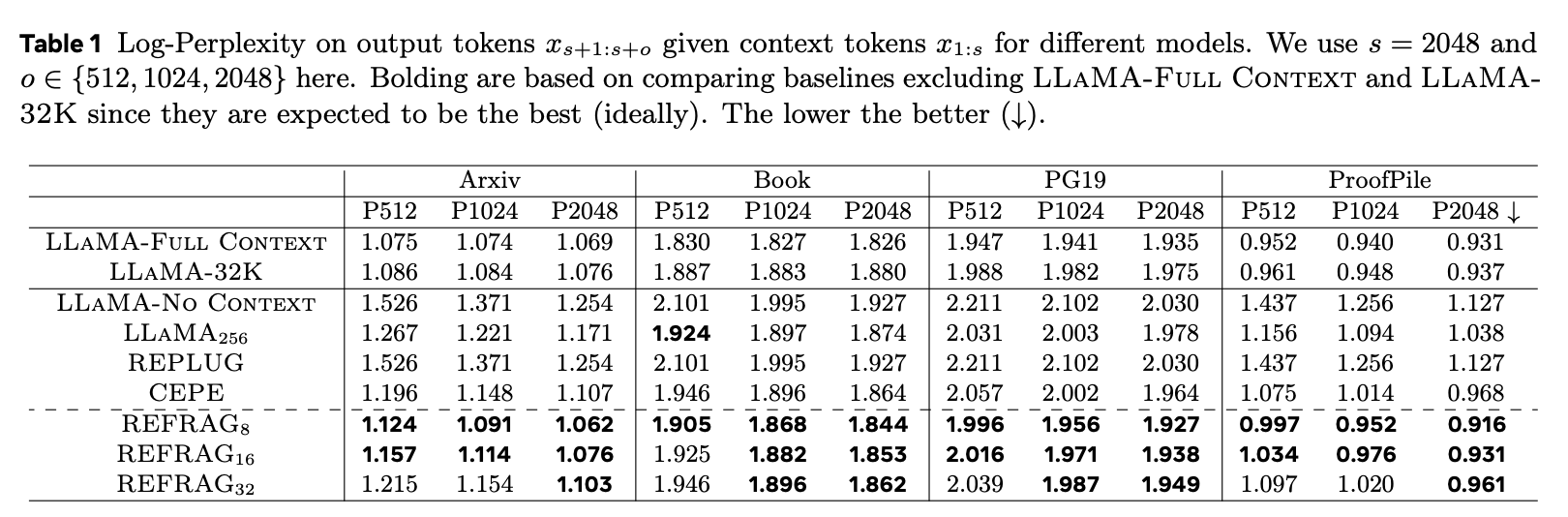
The paper evaluated the model using perplexity on output tokens. Lower perplexity can be interpreted as the model having higher confidence in the generated tokens. In other words, lower is better.
In the experiments, each data sample with T = 4096 tokens was divided into s = 2048 context tokens and o = 2048 output tokens. The model's perplexity on the output tokens was then measured.
LLAMA-No Context took only the output tokens as input and measured perplexity for tokens from s+1 to s+o. That is, it predicted the (s+1)-th token with no initial tokens, then predicted the (s+t+1)-th token while observing tokens s+1 to s+t, measuring perplexity throughout.
The baselines LLAMA-Full Context and LLAMA-32K received all T tokens as input and evaluated tokens s+1 to s+o. In other words, perplexity was measured with full context available.
REFRAG was measured with varying values of k (8, 16, 32).
The results show that REFRAG achieves considerably low perplexity, excluding the baselines.
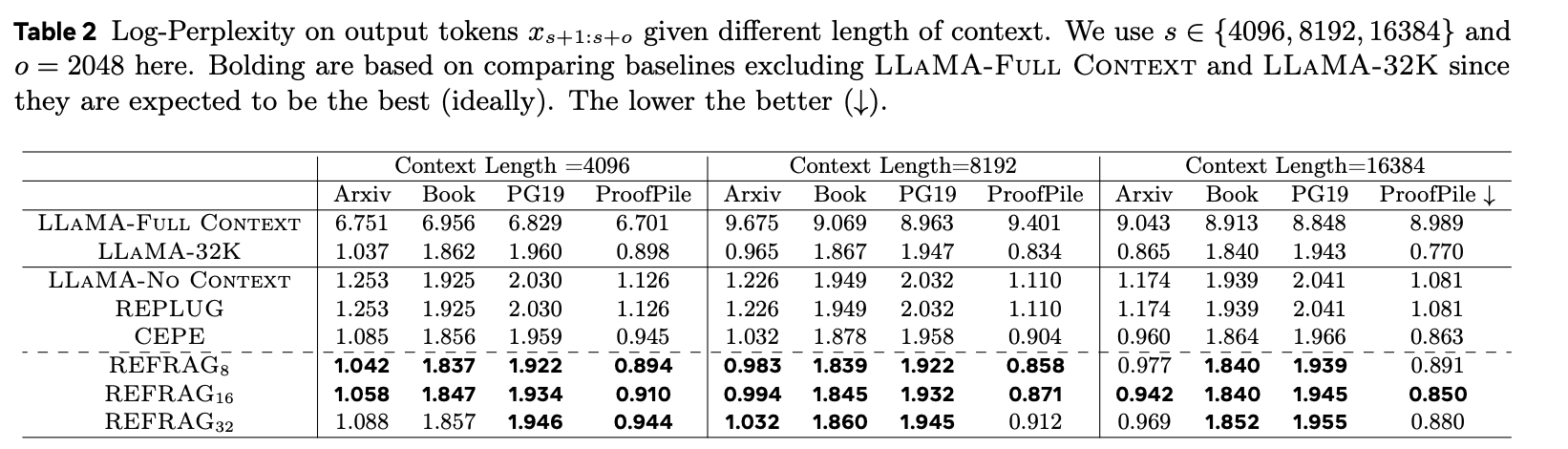
REFRAG demonstrated strong performance even with long context lengths.
LLAMA-Full Context, which has a 4k context window, shows a sharp performance drop on long contexts.
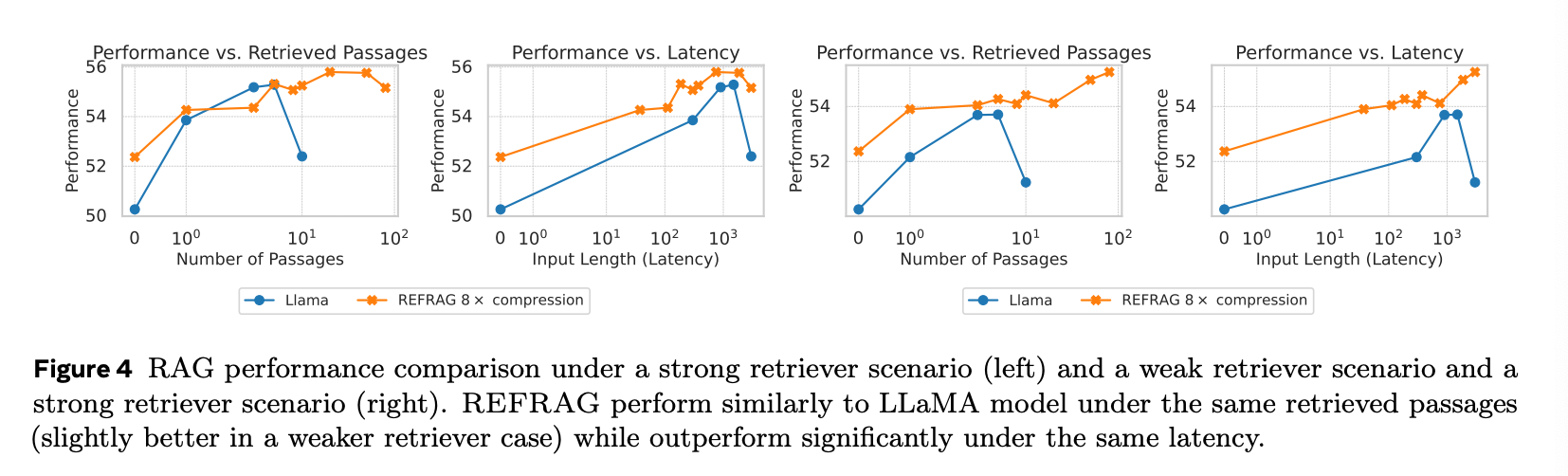
REFRAG's effectiveness shines even more in RAG scenarios.
In Figure 4 above, the left graph shows the strong retriever case, while the right shows the weak retriever case. The strong retriever brings the K passages closest to the question (KNN), while the weak retriever fetches 200 passages and randomly selects K of them.
Performance is a score evaluating how well questions were answered—an averaged metric across multiple RAG tasks performed in the paper.
We can confirm that REFRAG achieves better performance for the same latency.
Why It's Difficult to Embed a REFRAG Encoder Inside LLMs
A natural question arises when reading this paper:
"What if we placed a lightweight encoder like REFRAG inside the LLM architecture to compress context before Self-Attention? Wouldn't all LLM users benefit from this?"
After all, what REFRAG adds is an encoder that divides and compresses context. If this were embedded in the LLM architecture, all LLM users could benefit from it.
However, when we carefully consider the meaning of Self-Attention, we realize that adding such an encoder within the architecture is not meaningful.
The Nature of Self-Attention
Before Self-Attention:
- Each token is an independent embedding vector
- There is no relational information with other tokens
- The meaning between tokens is unknown
After Self-Attention:
- Contextual meaning is acquired through token interactions
- Relationships within the sequence can finally be understood
In other words, until Self-Attention is performed, we cannot know what each token means or which tokens should be grouped together.
Why REFRAG's Encoder Works: RAG's Unique Characteristics
REFRAG's encoder can be used because of the characteristics inherent to RAG:
1. Clear Boundaries
Each passage retrieved in RAG is already separated as an independent document unit. It's clear where to divide them.
2. Independent Encoding
Each passage is encoded independently, and attention is not calculated between different passages.
3. Weak Inter-Passage Connections
Passages retrieved in RAG are independent documents, so their direct connections are weak. Therefore, compressing them independently does not damage semantic meaning.
Why It Doesn't Work for General LLMs
In contrast, general LLMs face different challenges:
- User queries, system prompts, conversation history, etc., form one continuous sequence
- Before Self-Attention, we cannot know which parts are semantically grouped
- Arbitrarily dividing into chunks and compressing could break context
For example, in the sentence "I watched a movie yesterday. It was really entertaining," if we separately compress "I watched a movie" and "yesterday. It was really entertaining," the meaning is damaged. However, before Self-Attention, we cannot know how to properly divide this sentence.
Conclusion
REFRAG's compression method is a domain-specific optimization that leverages RAG's structural characteristics (clearly separated independent passages). This is why it cannot be embedded in general-purpose LLM architectures, and simultaneously why RAG-specific optimization is necessary.