
eBPF/XDP: Secure and Fast Networking You Might Not Know About

[Summary]
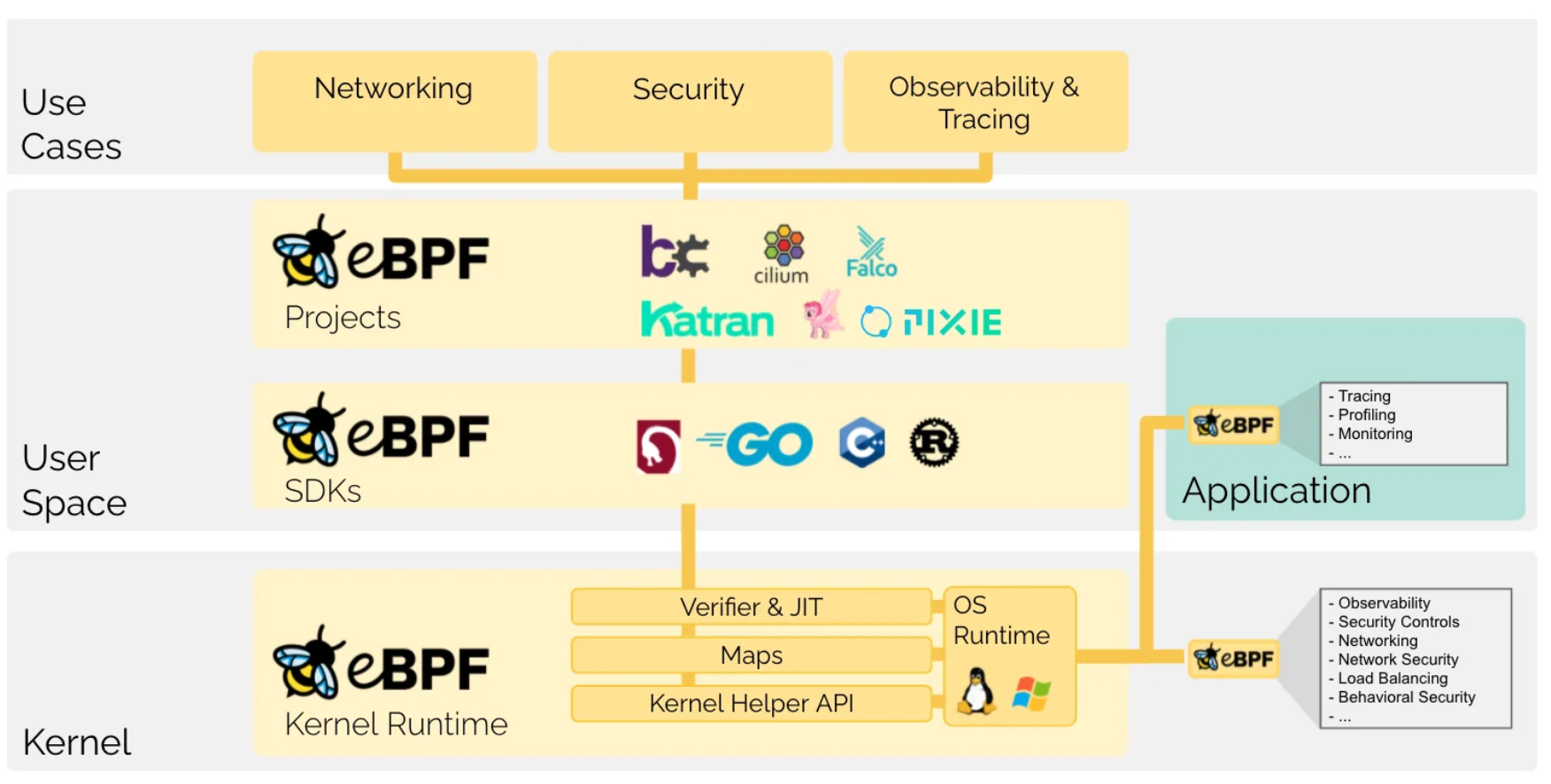
- eBPF: Technology enabling application developers to run programs within the kernel space, allowing them to utilize OS functions at runtime.
- XDP: Technology based on eBPF that supports packet processing.
- XDP consists of XDP driver hooks and the eBPF virtual machine, enabling secure packet processing in the kernel space with high performance.
- Many companies, including Google and Naver, utilize XDP in projects like Cilium.
1. Introduction
eBPF has been a topic of discussion at development conferences and various tech companies for quite some time. However, understanding eBPF can be challenging if you're not familiar with its related domains. Moreover, due to the scarcity of Korean-language resources and the brevity of existing explanations, it can feel even more daunting.
In this article, we will explore "The eXpress Data Path: Fast Programmable Packet Processing in the Operating System Kernel" (2018), which reveals the design of XDP. Instead of diving straight into the content of the paper, which could be difficult, we will gain an understanding through examples of using eBPF and XDP. Additionally, we will showcase examples of eBPF usage, such as Cilium, an open-source project, and Naver's implementation of NAT using eBPF.
I hope this article will be helpful for those who are new to eBPF/XDP.
2. Understanding eBPF/XDP through Examples
Operating systems use virtual memory to separate address spaces into user space and kernel space. These two address spaces are distinct layers: user space is used by user applications and system daemons, while kernel space is utilized by the Linux kernel itself.
The Linux kernel operates with higher privileges compared to applications in user space, allowing it to observe and control the system more effectively. However, due to its critical role in the OS, rapid evolution has been challenging, driven by high demands for stability and security.
eBPF is a technology that enables executing programs within the kernel space, allowing application developers to utilize OS functionalities at runtime.
XDP (eXpress Data Path) is a technology based on eBPF that supports packet processing through eBPF programs.
Let's enhance our understanding through examples.
Using eBPF (XDP) in Applications
This example is a reconstruction based on ebpf-go's example.
Goal: Create a program that counts packets coming in through the eth0 interface.
We proceed with the following steps:
- Writing an eBPF Program Running in the Kernel
- Compiling with eBPF and Generating Golang Code
- Writing a Golang application to load and communicate with the eBPF program
(1) Writing an eBPF Program Running in the Kernel
We will write the eBPF program in C to build it and compile it with LLVM.
First, let's write the file counter.c as follows.
//go:build ignore
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__type(key, __u32);
__type(value, __u64);
__uint(max_entries, 1);
} pkt_count SEC(".maps");
// count_packets atomically increases a packet counter on every invocation.
SEC("xdp")
int count_packets() {
__u32 key = 0;
__u64 *count = bpf_map_lookup_elem(&pkt_count, &key);
if (count) {
__sync_fetch_and_add(count, 1);
}
return XDP_PASS;
}
char __license[] SEC("license") = "Dual MIT/GPL";pkt_count is a structure that records the number of packets, used as a map structure in eBPF. __uint and __type are macros used in eBPF maps.
count_packets increments the counter of pkt_count each time it is called. Upon closer inspection, bpf_map_lookup_elem fetches the value associated with the key from pkt_count, and __sync_fetch_and_add increments it by 1.
(2) Compiling with eBPF and Generating Golang Code
We will compile counter.c into an object file and generate corresponding Golang code using bpf2go.
First, define a Go module and obtain bpf2go to use the Golang toolchain.
$ go mod init ebpf-test && go mod tidy
$ go get github.com/cilium/ebpf/cmd/bpf2goLet's write the following gen.go code.
package main
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go counter counter.cbpf2go builds counter.c into an object file using clang and generates corresponding Go code.
$ ls
counter.c counter_bpfeb.go counter_bpfeb.o counter_bpfel.go counter_bpfel.o gen.go go.mod go.sumThe generated Go code defines functions and structs to enable the use of objects created by the eBPF program.
// loadCounterObjects loads counter and converts it into a struct.
//
// The following types are suitable as obj argument:
//
// *counterObjects
// *counterPrograms
// *counterMaps
//
// See ebpf.CollectionSpec.LoadAndAssign documentation for details.
func loadCounterObjects(obj interface{}, opts *ebpf.CollectionOptions) error {
spec, err := loadCounter()
if err != nil {
return err
}
return spec.LoadAndAssign(obj, opts)
}
....
// counterObjects contains all objects after they have been loaded into the kernel.
//
// It can be passed to loadCounterObjects or ebpf.CollectionSpec.LoadAndAssign.
type counterObjects struct {
counterPrograms
counterMaps
}
// counterMaps contains all maps after they have been loaded into the kernel.
//
// It can be passed to loadCounterObjects or ebpf.CollectionSpec.LoadAndAssign.
type counterMaps struct {
PktCount *ebpf.Map `ebpf:"pkt_count"`
}
// counterPrograms contains all programs after they have been loaded into the kernel.
//
// It can be passed to loadCounterObjects or ebpf.CollectionSpec.LoadAndAssign.
type counterPrograms struct {
CountPackets *ebpf.Program `ebpf:"count_packets"`
}(3) Write a Golang application that loads and communicates with the eBPF program.
Using the previously generated counter_bpfeb.go and counter_bpfel.go, let's write an application that loads and communicates with the eBPF.
func main() {
// Remove resource limits for kernels <5.11.
if err := rlimit.RemoveMemlock(); err != nil {
log.Fatal("Removing memlock:", err)
}
// Load the compiled eBPF ELF and load it into the kernel.
var objs counterObjects
if err := loadCounterObjects(&objs, nil); err != nil {
log.Fatal("Loading eBPF objects:", err)
}
defer objs.Close()
ifname := "eth0" // Change this to an interface on your machine.
iface, err := net.InterfaceByName(ifname)
if err != nil {
log.Fatalf("Getting interface %s: %s", ifname, err)
}
// Attach count_packets to the network interface.
link, err := link.AttachXDP(link.XDPOptions{
Program: objs.CountPackets,
Interface: iface.Index,
})
if err != nil {
log.Fatal("Attaching XDP:", err)
}
defer link.Close()
log.Printf("Counting incoming packets on %s..", ifname)
// Periodically fetch the packet counter from PktCount,
// exit the program when interrupted.
tick := time.Tick(time.Second)
stop := make(chan os.Signal, 5)
signal.Notify(stop, os.Interrupt)
for {
select {
case <-tick:
var count uint64
err := objs.PktCount.Lookup(uint32(0), &count)
if err != nil {
log.Fatal("Map lookup:", err)
}
log.Printf("Received %d packets", count)
case <-stop:
log.Print("Received signal, exiting..")
return
}
}
}loadCounterObjects loads the compiled eBPF program into the kernel.
AttachXDP attaches the count_packets function of the eBPF program to a network interface. Further explanation on XDP will follow.
After building, running the application allows counting packets incoming through eth0.
$ sudo ./ebpf-test
2024/07/07 02:19:20 Counting incoming packets on eth0..
2024/07/07 02:19:21 Received 5 packets
2024/07/07 02:19:22 Received 10 packets
2024/07/07 02:19:23 Received 16 packets
...Using XDP Standalone
This example is a reconfiguration of the Get Started with XDP example.
The previous example demonstrated a Golang application loading and communicating with an eBPF program. This time, we will examine an example of loading an XDP program from the shell.
Goal: Write an XDP program that drops all packets on a specific network interface.
Proceed with the following steps:
- Write and build the XDP program.
- Create a virtual network interface for experimentation.
- Load the XDP program and perform a ping test.
(1) Write the XDP program
Create the following xdp_drop.c file.
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
SEC("xdp_drop")
int xdp_drop_prog(struct xdp_md *ctx)
{
return XDP_DROP;
}
char _license[] SEC("license") = "GPL";With a very simple code, when xdp_drop_prog is called, it returns XDP_DROP. Packets received with XDP_DROP are dropped entirely, so the network interface to which this program is attached will drop all packets.
Let's build it using clang as follows:
$ clang -O2 -g -Wall -target bpf -c xdp_drop.c -o xdp_drop.o(2) Creating the experimental virtual network interface
Since attaching to the currently used network interface is risky, let's create a separate virtual network interface to load the XDP program.
We will create a separate network namespace and create a veth pair linked to that namespace.
# Create a network namespace named "net"
$ sudo ip netns add net
# default namespace에 veth1, net namespace에 veth2 생성
$ sudo ip link add veth1 type veth peer name veth2 netns net
# Check creation
$ sudo ip link show
...
369: veth1@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether fa:46:33:26:e9:0c brd ff:ff:ff:ff:ff:ff link-netns net
$ sudo ip netns exec net ip link show
...
3: veth2@if369: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 62:df:82:b0:ed:63 brd ff:ff:ff:ff:ff:ff link-netnsid 0Assign IPs to veth1 and veth2, and perform a ping check.
# Assign ip
$ sudo ip addr add 192.168.1.1/24 dev veth1
$ sudo ip netns exec net ip addr add 192.168.1.2/24 dev veth2
# interface up
$ sudo ip link set veth1 up
$ sudo ip netns exec net ip link set veth2 up
# route check
$ ip route show
..
192.168.1.0/24 dev veth1 proto kernel scope link src 192.168.1.1
# ping check
$ ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.037 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.029 ms
64 bytes from 192.168.1.2: icmp_seq=3 ttl=64 time=0.036 msYou can confirm successful ping from veth1 to veth2 (192.168.1.1).
(3) Load the XDP program and perform a ping test
We will load the XDP program created in (1) and attach it to veth1. Since the XDP program drops all packets coming through veth1, pings should fail after loading.
# xdp load
$ sudo xdp-loader load -m skb -s xdp_drop veth1 xdp_drop.o
$ sudo xdp-loader status
CURRENT XDP PROGRAM STATUS:
Interface Prio Program name Mode ID Tag Chain actions
--------------------------------------------------------------------------------------
...
veth1 xdp_dispatcher skb 66 94d5f00c20184d17
=> 50 xdp_drop_prog 73 57cd311f2e27366b XDP_PAS
$ sudo ip link show veth1
369: veth1@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdpgeneric qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether fa:46:33:26:e9:0c brd ff:ff:ff:ff:ff:ff link-netns net
prog/xdp id 66 name xdp_dispatcher tag 94d5f00c20184d17 jitedxdp_dispatcher is generated by xdp-loader, while xdp_drop_prog is the program we created.
Now, retrying the ping confirms that it fails.
$ ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
From 192.168.1.1 icmp_seq=1 Destination Host Unreachable
From 192.168.1.1 icmp_seq=2 Destination Host Unreachable
From 192.168.1.1 icmp_seq=3 Destination Host UnreachableFrom these two examples, we understand that using eBPF/XDP allows us to (1) write programs for packet processing and (2) execute them in the kernel space and communicate with user space.
Next, in the following section, let's delve deeper into the structure of XDP and eBPF through "The eXpress Data Path: Fast Programmable Packet Processing in the Operating System Kernel" (2018).
3. XDP Structure and eBPF
I have summarized the contents of "The eXpress Data Path: Fast Programmable Packet Processing in the Operating System Kernel" (2018)
3.1 Abstract & Introduction
XDP, short for eXpress Data Path, is a programmable packet processing technology. Before this, packet processing technologies existed but bypassed the kernel. This was to avoid context switching between kernel and user space, but it did not benefit from the security and stability provided by the OS.
XDP operates within a secure execution environment provided by the OS kernel, built on eBPF (extended Berkeley Packet Filter). eBPF ensures safety by statically verifying programs and enables execution in the kernel space. Additionally, it allows packets to be processed before they reach the kernel's network stack.
The advantages can be summarized as follows:
- Integration with the Linux networking stack.
- Dynamic addition or removal of features without service interruption.
- Operation with low CPU usage as dedicated CPU cores for packet processing are not required.
- Secure execution in kernel space using eBPF.
3.2 The Design of XDP
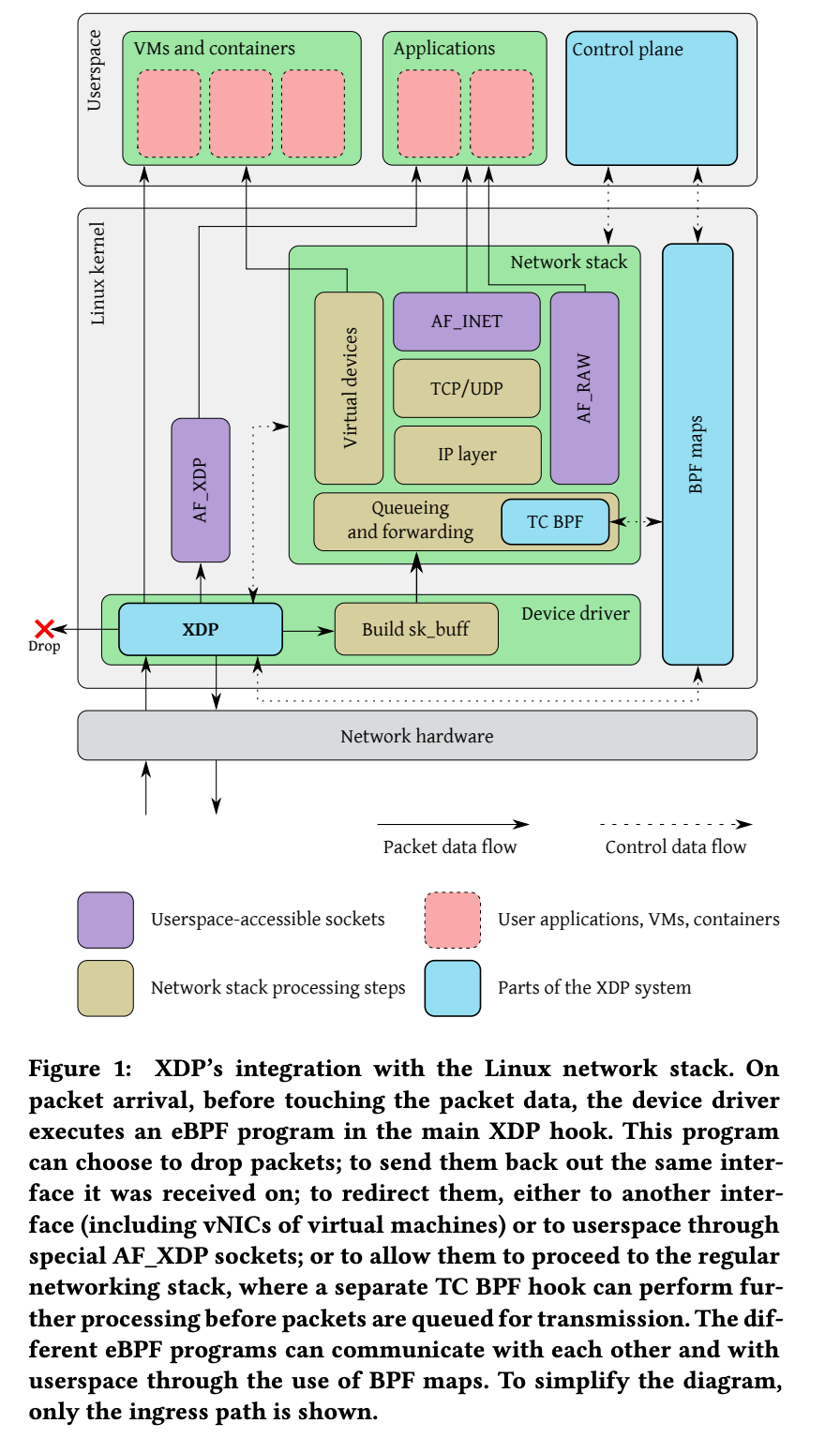
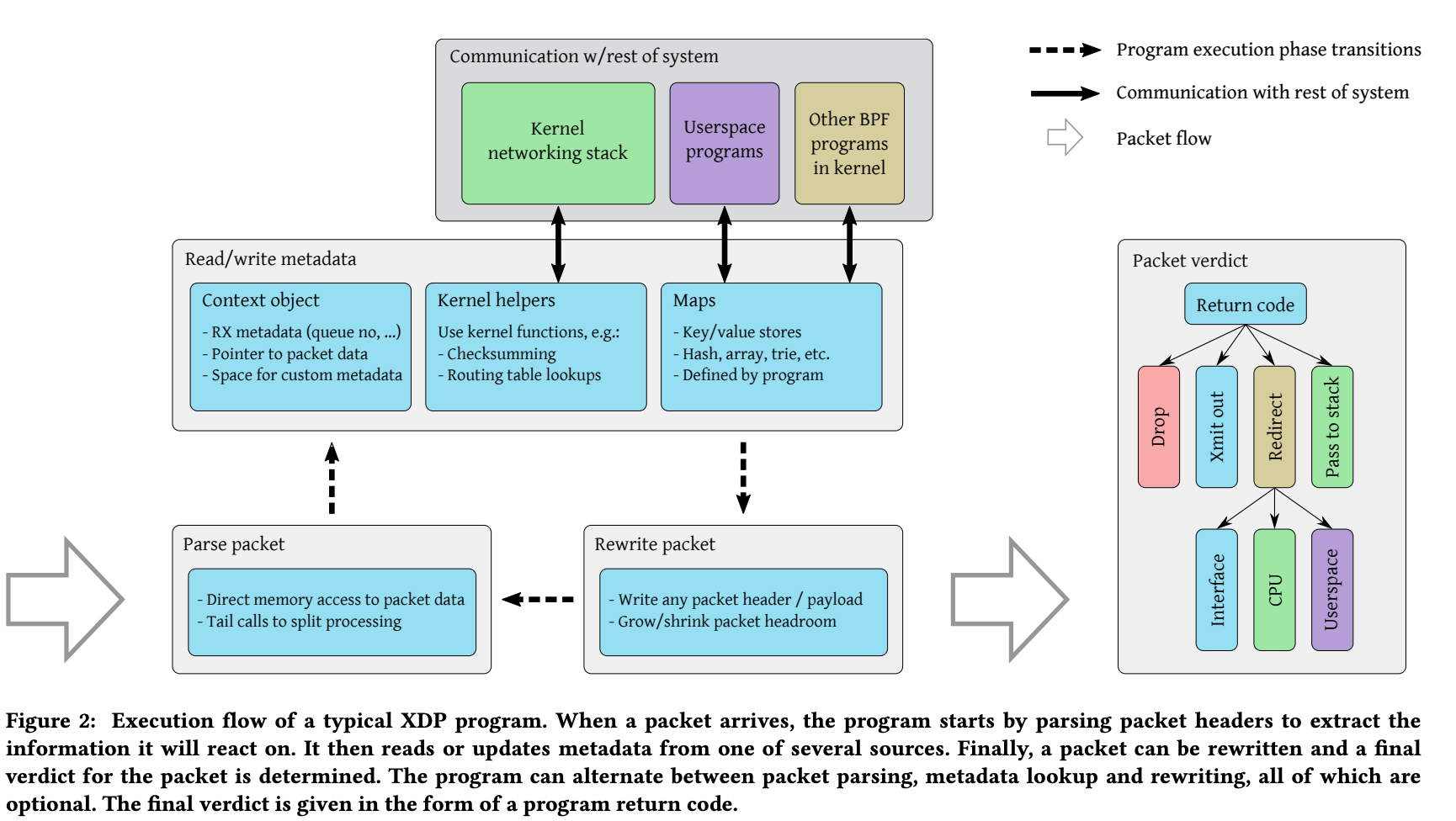
The XDP system consists of four major components:
- XDP driver hook: Main entry point of the XDP program; executed when packets arrive from hardware.
- eBPF virtual machine: Executes the bytecode of the XDP program, optionally using JIT compilation.
- BPF maps: Key/value stores used as communication channels with other systems.
- eBPF verifier: Statically verifies programs before loading to ensure they do not crash or corrupt the kernel.
3.2.1 XDP Driver Hook
When a packet arrives, the XDP program is triggered by a hook within the network device driver. The XDP program runs within the device driver context and avoids context switching to user space. Additionally, as seen in Figure 1, it receives packets before the network stack.
Figure 2 illustrates the processing stages of an XDP program:
- The XDP program parses the packet.
- It reads metadata fields related to the packet using a context object. It can also execute logic using kernel helpers or mappers.
- The program can write packet data and resize the packet buffer. It's possible to rewrite address fields for forwarding, among other actions.
- Upon completion of packet processing, it issues a final return code. For redirects (solid line in Figure 1), it can send packets to different network interfaces, CPUs, or user space socket addresses.
3.2.2 eBPF Virtual Machine
XDP programs run on the eBPF virtual machine.
eBPF is an advanced form of the BSD packet filter (BPF). The BPF virtual machine used two 32-bit registers and 22 instructions. In contrast, eBPF employs 11 64-bit registers and maps the BPF call instruction to native call instructions, minimizing overhead for function calls.
The eBPF instruction set enables general-purpose computation, but programs are restricted by the eBPF verifier to protect the kernel (discussed later in 3.2.4).
Using eBPF maps (discussed later in 3.2.3), eBPF programs can respond to events occurring in different parts of the kernel. For example, monitoring CPU load or dropping packets when a specific threshold is exceeded is possible with XDP programs.
The eBPF virtual machine supports dynamically loading and reloading programs.
3.2.3 BPF Maps
eBPF programs execute in response to events within the kernel. For XDP, this means they execute when packets arrive. These programs start from the same initial state but do not have persistent memory. Instead, they utilize eBPF maps.
BPF maps are key/value stores defined to load eBPF programs and can be accessed by eBPF code. Maps can exist globally or per CPU and can be shared among multiple eBPF programs as well as between kernel and user space.
Using BPF maps allows one eBPF program to modify state and thereby influence the behavior of other programs. Communication between user space programs and eBPF programs is also possible (see 2. Understanding eBPF/XDP through Examples).
3.2.4 eBPF Verifier
eBPF code executes in the kernel space and could potentially damage kernel memory. To prevent this, the kernel enforces a single entry point for all eBPF programs (via the bpf() system call). Upon loading at the entry point, the eBPF verifier within the kernel analyzes the bytecode of the eBPF program.
The eBPF verifier performs static analysis on the bytecode to ensure it does not perform unsafe operations such as accessing arbitrary memory. To achieve this, it restricts features like loops and limits the maximum program size.
The verifier constructs a Directed Acyclic Graph (DAG) from the program's control flow:
- It performs Depth-First Search (DFS) to ensure the DAG is acyclic (checking for loops).
- It verifies all possible paths in the DAG to ensure safe memory access and correct function calls with valid arguments.
The verifier tracks the state of registers, including data types, pointer offsets, and possible value ranges. This information allows the verifier to predict memory ranges for load instructions, ensuring safe memory access.
eBPF programs that the verifier cannot prove to be safe are rejected during loading.
3.3 Performance Evaluation
In the paper, performance evaluation was conducted by measuring the following three aspects:
- Packet drop performance
- Cpu usage
- Packet forwarding performance
For comparison, DPDK, known for its high-performance packet processing, was chosen as a baseline among existing packet processing solutions. Additionally, they also evaluated the performance of the traditional Linux network stack.
packet drop performance
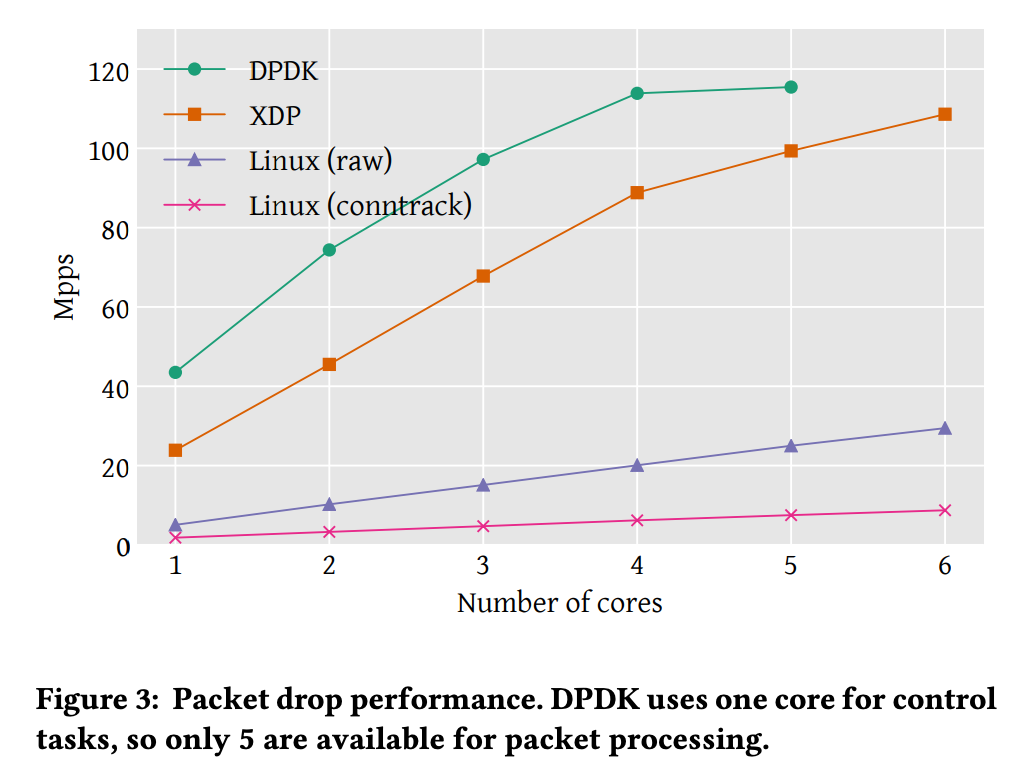
Mpps: Maximum packets per second
Linux(raw): Use linux iptable firewall module
Linux(conntrack): Use connection tracking module
XDP showed better performance than Linux module, but lower performance compared to DPDK. DPDK can be measured performance using up to 5 cores, because of allocating one core for control tasks.
CPU usage
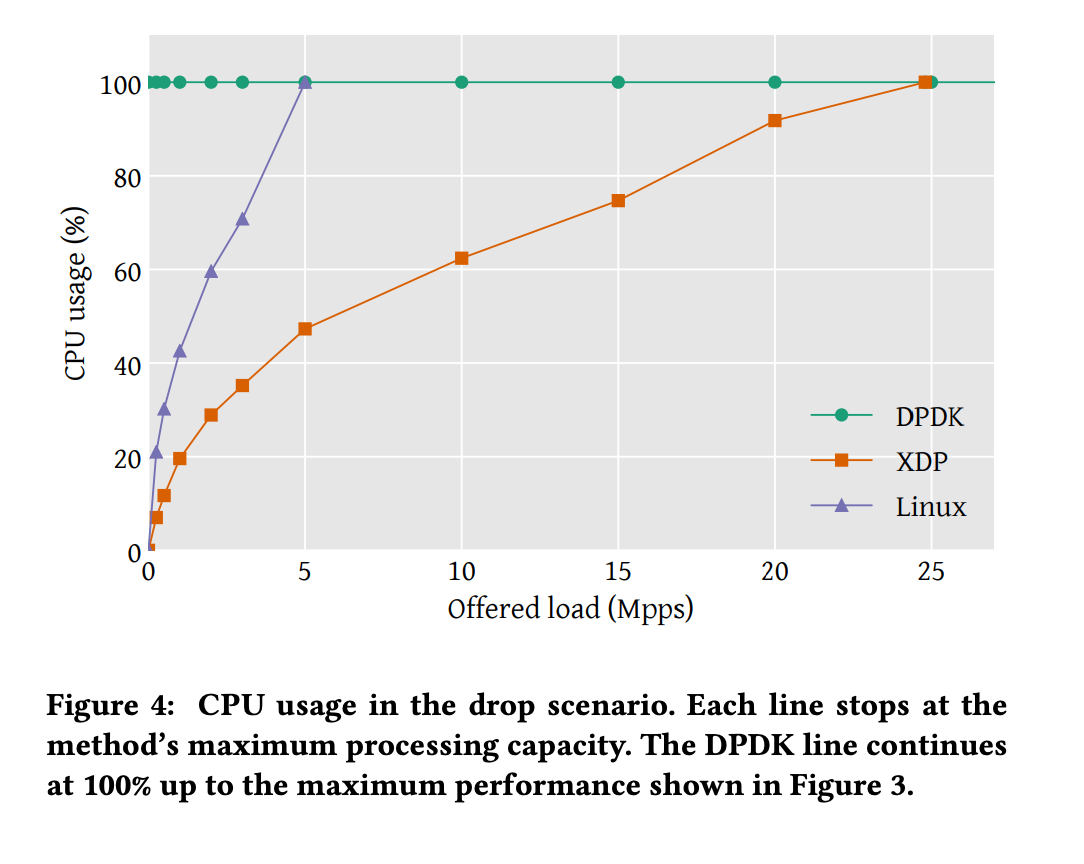
DPDK is designed to utilize full cores for packet processing, achieving 100% utilization using busy polling.
The non-linear segment in the lower left corner is due to fixed overhead from interrupt processing.
Packet forwarding
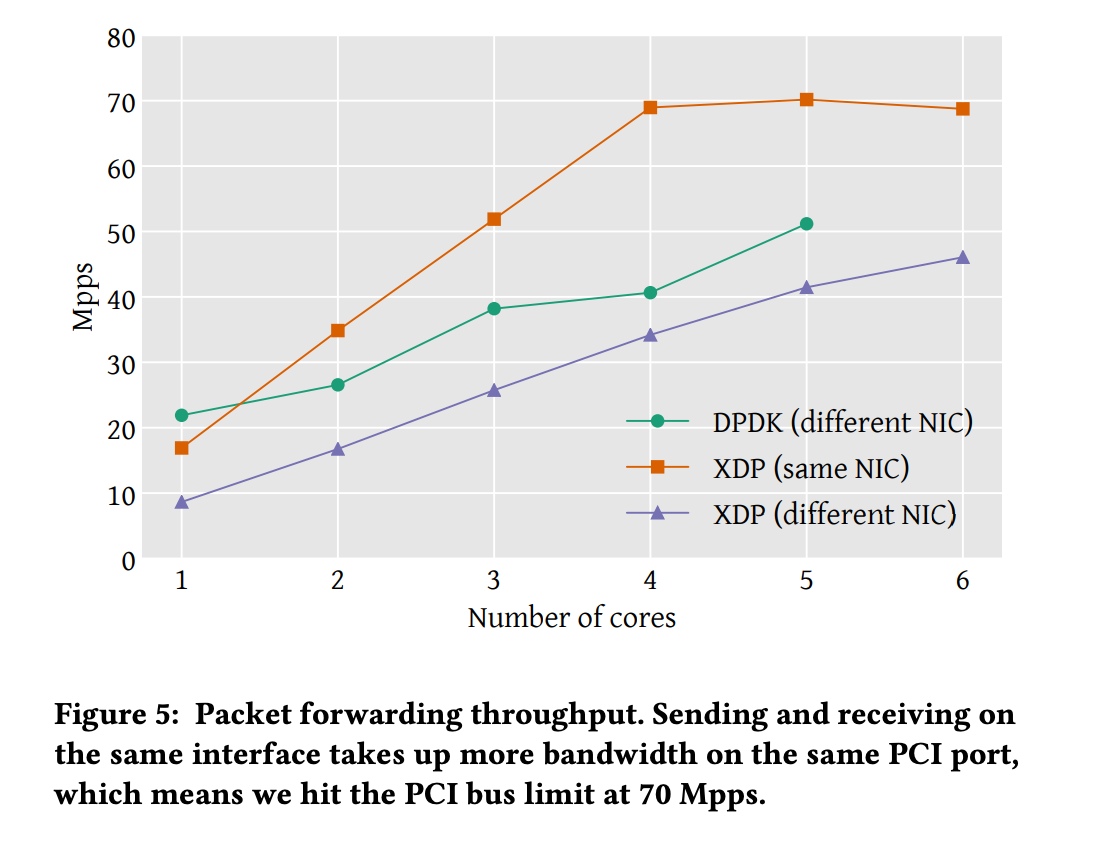
XDP's evaluation included forwarding within the same NIC. The performance improvement when sending through the same NIC is attributed to differences in memory handling. Packet buffers are allocated by the device driver, which is associated with the interface. Therefore, when forwarding packets to another interface, the memory buffer must be allocated to that interface.
XDP is faster than the Linux networking stack but does not match DPDK in performance. However, the paper argues that DPDK benefits from extensive optimizations at the low-level. For instance, in packet drop scenarios, the difference in processing time per packet on a single core is 18.7 ns, with 13 ns attributed to functions used by a specific driver. It is anticipated that performing optimizations such as these at the driver level could eliminate performance differences with DPDK.
4. Use case of eBPF/XDP
Six years after the paper discussed in Section 3, eBPF/XDP is widely adopted in many projects and companies. Here, I will briefly introduce two prominent examples: Cilium and Naver.
(1) Cilium
Cilium is a CNCF project primarily used for networking tasks between Kubernetes clusters.
Traditional Linux networking filters based on IP addresses and TCP/UDP ports faced challenges in container environments like Kubernetes. With the proliferation of microservices and shorter container lifespans, frequent IP address changes made it difficult to control load balancers and ACL rules based on IP addresses and port numbers.
Cilium offers a solution by identifying services, pods, and containers based on service/pod/container IDs rather than IP addresses. It also provides filtering at the application layer (e.g., HTTP), separating IP address allocation from security policies.
(2) Naver - eBPF/XDP-based NAT System
Naver encountered similar challenges in their Kubernetes clusters. Initially, they synchronized Pod and ACL system information to manage ACLs based on IP addresses, which became burdensome. Moreover, failure to propagate ACLs to some pods could lead to outages.
To address these issues, they implemented NAT. Initially, they used Linux Netfilter (iptables) for implementation but encountered performance issues, prompting them to switch to eBPF. For detailed implementation specifics, refer to Deview.
5. Conclusion
We have briefly explored examples, papers, and real-world cases to understand eBPF/XDP.
eBPF is a technology that offers many advantages such as (1) relatively high performance, (2) safety, and (3) the ability to perform networking tasks without service interruption. As seen in the cases of Cilium and Naver, it shines particularly brightly as container environments become more prevalent.
As seen in the examples, loading and communicating with eBPF programs from applications can be very useful in practical applications. We hope that this technology continues to be beneficial in various industries.
Reference
The eXpress Data Path: Fast Programmable Packet Processing in the Operating System Kernel (2018)