
[Paper review] ColBERT, ColBERTv2
![[Paper review] ColBERT, ColBERTv2](https://images.unsplash.com/photo-1501290741922-b56c0d0884af?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDF8fHJlc2VhcmNofGVufDB8fHx8MTY5MDc2MDkzMnww&ixlib=rb-4.0.3&q=80&w=2000)
[Summary]
- BM25 is widely used for ranking method for IR. But since 2016, ranking methods using Neural Networks have started to appear
- Neural IR generally showed high MRR, but had expensive computation. Especially BERT, which showed excellent MRR, was too slow to be applied to services
- ColBERT had a slightly lower MRR than BERT, but was much faster
- ColBERTv2 uses less storage than ColBERT and improves ranking performance by compressing using centroid
[Contents]
- Why I review ColBERT
- Neural IR Ranking
- ColBERT (2020)
- ColBERTv2 (2022)
1. Why I review ColBERT
IR(Information Retrieval) is the task of taking a query, finding. ranking, and returning the appropriate documents among from a large number of documents.
I'm currently implementing a search engine at company and I'm responsible for retrieving documents that appear in a query's terms. Like me, searching for candidate documents is one thing, but ranking the documents that end up in front of the user is very important. Since most users don't go beyond page 1 when searching, it's safe to say that ranking documents determine the quality of the search.
BM25 is widely used as a traditional ranking method. BM25 is similar to TF-IDF but takes into account to document's length. It considers how many times that term has appeared in which documents (more appear, greater value) and how many documents it appeared in (the more documents it appeared in, the smaller the value). Because BM25 value can be precalculated in inverted search engine, it is widely used in search engine which treats many documents and where performance is important.
Since 2016, Neural Ranking with Neural Layer was starting to appear. Neural Ranking shows good recall-ratio(how many relevant documents in retrieved documents) so many companies started to use language model like BERT(google, MS bing). Naver search also announced application of ColBERT in Deview.
ColBERT was published in 2020, so it's pretty old by now. However, here we are still in 2023, there are still follow-up studies based on ColBERT. This is why we can't talk about Neural IR without mentioning ColBERT.
In this article, we will review ColBERT (2020) and ColBERTv2 (2022) which is a follow-up paper by the first author of ColBERT. We will first cover Neural IR Ranking, which is necessary to understand ColBERT, and then look at ColBERT and ColBERTv2 in turn.
2. Neural IR Ranking
IR Ranking refers to scoring query-document pairs, sorting them in descending order, and then getting the top K results.
As mentioned earlier, before Neural Ranking was widely used, BM25 was mainly used. However, in 2016, Query-Document Interaction Models started to appear.
Query-Document Interaction Models (2016~2019)
Models such as KNRM, Conv-KRM, and duet fall into this category. Here's how these models calculate their scores.
- Tokenize query and documents
- Embedding tokens to vector
- Make query-document interaction matrix. And compute cosine similarity for each pair of words.
- Use the matrix created in 3 to compress it into a score. Use a neural Layer (convolution, linear layers ...).
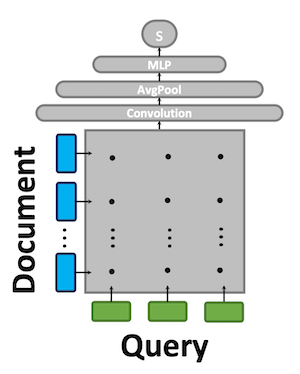
These models performed satisfactorily with a higher MRR at the expense of increased computation (increased query latency). However, due to the increased latency, it could not be applied to all retrieved documents and was mainly applied to the Top K documents selected by BM25 (reranking).
Advent of BERT (2019)
In 2019, we fine-tuned BERT's classifier and started using it for rankings.
Here's how we used BERT for our rankings.
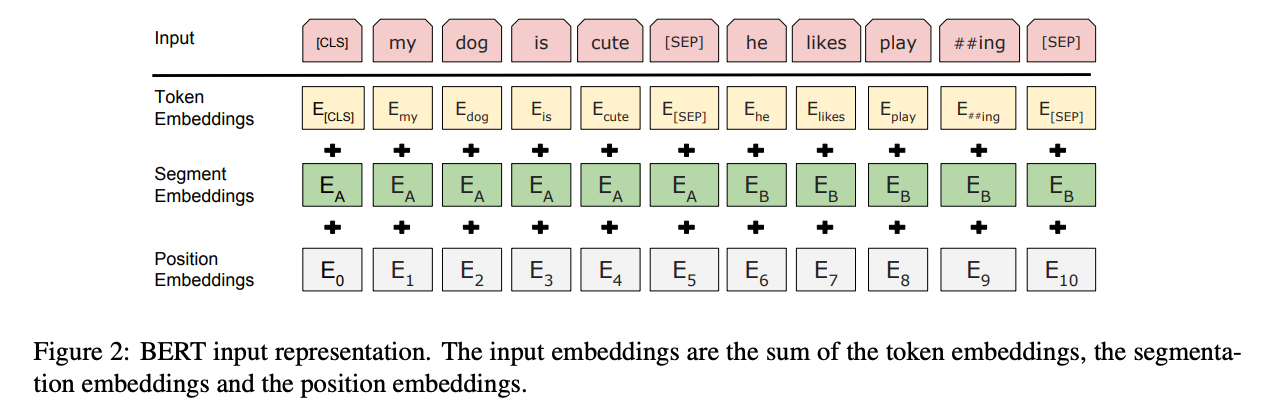
[Prerequisite]
- [CLS] : Classification → the token that should be put at the beginning of each input sequence. BERT aggregates the vectors with [CLS] tokens in the last layer.
- [SEP] : Separation. The input to BERT should be [SEP] between separate tasks, like a question and answer.
[How to ranking]
- Give BERT input in the form "[CLS] Query [SEP] Document [SEP]". You should include the [CLS] and [SEP] tokens in the input data.
- Run for all BERT layers
- Extract the score from the last [CLS] output embedding.
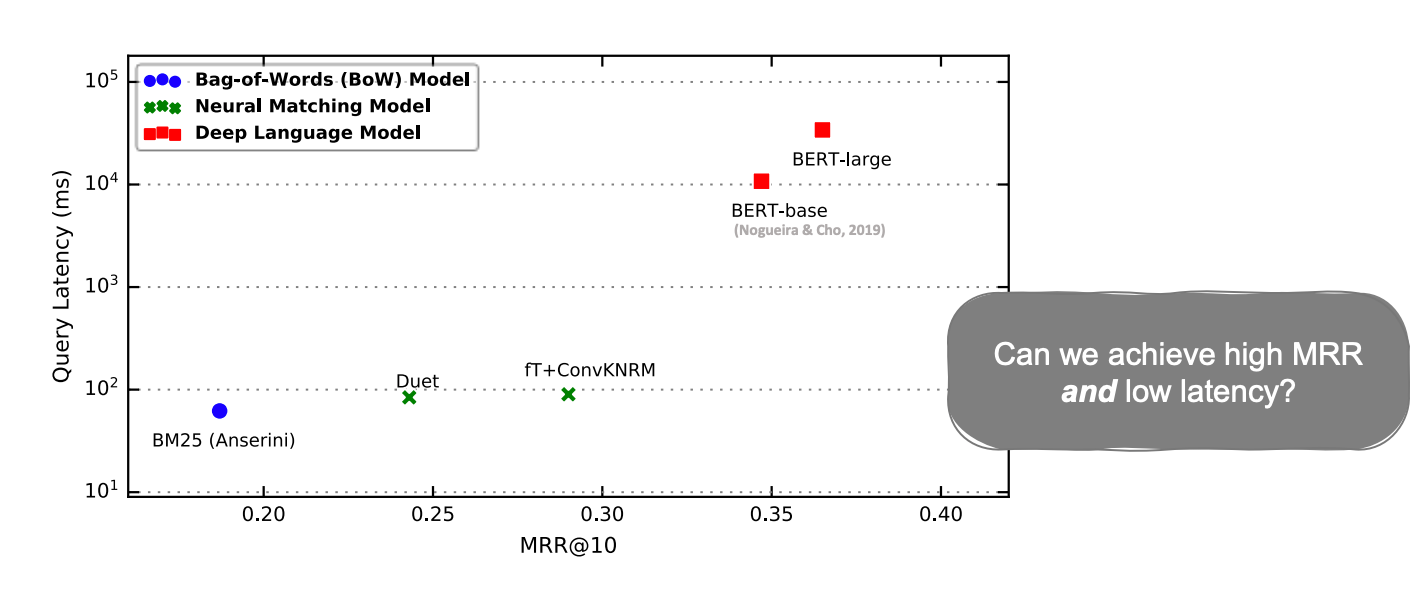
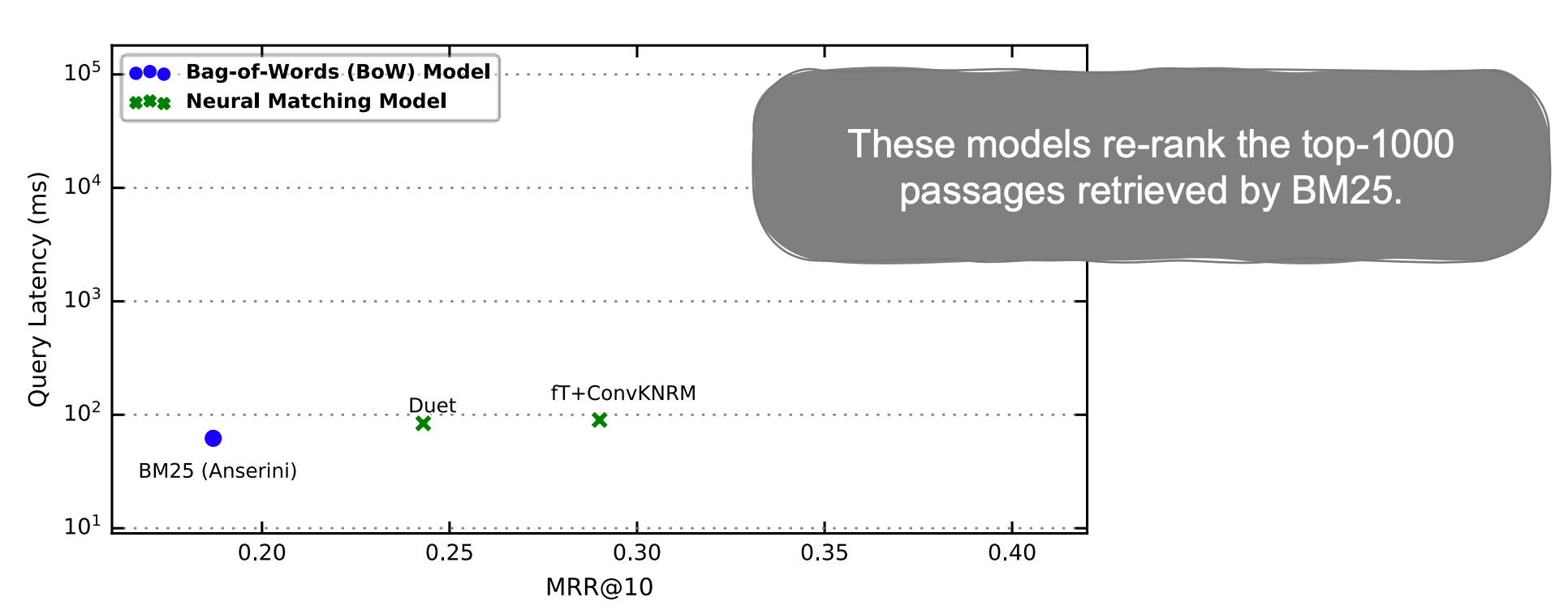
BERT had a high MRR, but it required a lot of computation and had a very high latency. In the graph above, you can see that the latency is almost 100x different from BM25.
Therefore, several studies have emerged to increase MRR while reducing computation.
Representation Similarity
DPR (Dense Passage Retriever) (2020) is a representative representation model. In DPR, compute ranking by encoding each document and query as a 768-dimensional vector.
The Representation Similarity model precomputes document representations and scores them using dot product or cosine similarity, which significantly reduces costs. DPR's use is not limited to reranking, it could be used for end-to-end retrieval. This is because the document vector representation could be indexed and searched with a fast vector similarity search. This can be implemented using libraries like FAISS.
However, by representing it as a single vector, it became a coarse grain representation and lost the term level interaction. So it has lower MRR than BERT.
3. ColBERT (2020)
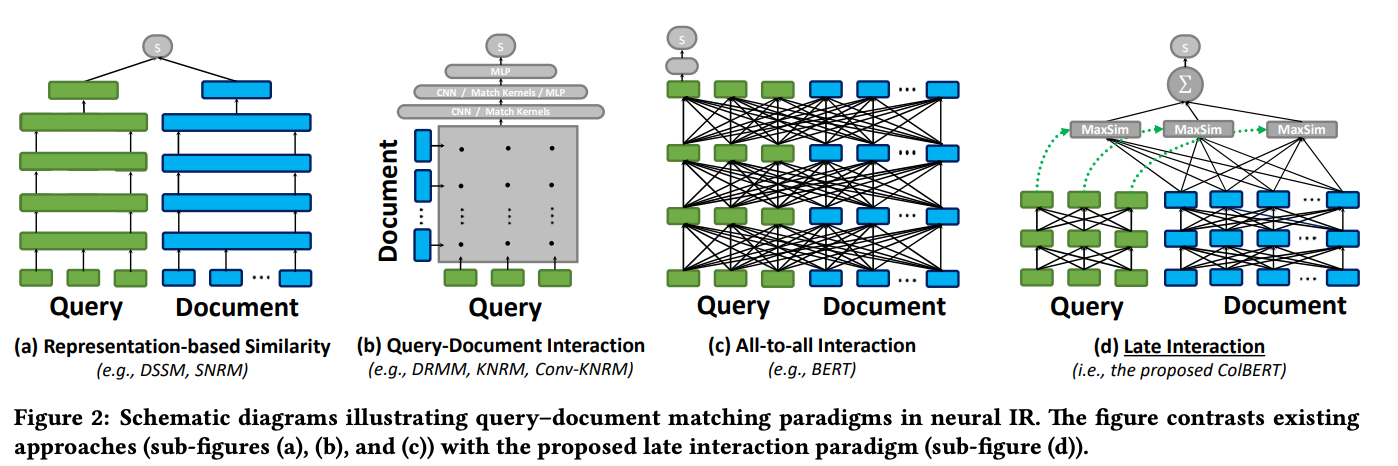
From the models we've seen so far, we can derive the properties we want in our model as follows.
- Enables independent encoding
- Fine grained representation
- Perform a vector similarity search to enable end-to-end retrieval
ColBERT makes these properties possible by using Late Interaction. Like the Representation Similarity model, Late Interaction precomputed the document offline to speed up the computation.
3-1 Architecture
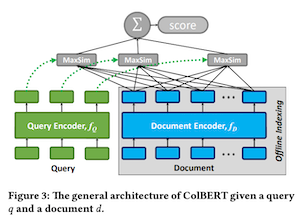
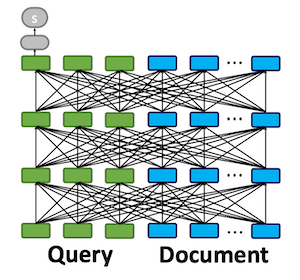
The architecture of ColBERT consists of (a) Query encoder (b) document encoder (c) late interaction. The query encoder embeds a given query q into Eq and the document encoder embeds a given document d into Ed.
ColBERT uses the maximum similarity (MaxSim) operator to calculate relevance scores with late interactions. MaxSim uses cosine or squared L2 distance. For every query term, MaxSim is computed for each document term and summed to get the score.
While more complex matching is possible using common interaction-focused models such as deep convolution or attenion layers, there are clear advantages to using MaxSim. (1) it is much cheaper to compute, and (2) it allows for efficient pruning in top-k retrieval.
3-2 Query & Document Encoders
Late interaction is used to embed queries and documents respectively, but since they share a single BERT model, the tokens [Q] and [D] must be used to distinguish between queries and documents in the input.
(1) Query Encoder
The Query Encoder tokenizes a given query q into BERT-based WordPiece tokens q1,q2,...ql. Then prefix the query with the token [Q]. If the query is less than a predetermined number of tokens, Nq, pad it with the BERT's [mask] token. Padding the mask token is called a query argument. The query argumentation affects the expansion of the query to new terms or the reweighting of existing terms.
The linear layer takes over the representation from the encoder to create an m-dimensional embedding. The number of embedding dimensions in ColBERT has a significant impact on query execution time and document space management. This is because the document representation has to be moved from system memory to the GPU. The most expensive steps in ColBERT's reranking are collecting, stacking, and moving them from the CPU to the GPU.
(2) Document Encoder
The Document Encoder has a similar structure to the Query Encoder. Create a document d with tokens d1,d2,...,dm and prefix [CLS], the start token of BERT, to the token [D] to signal document input. However, it does not attach the [mask] token to the document. The number of embeddings per document is then reduced by filtering out things like punctuation marks through a predetermined list.
To summarize, for a given q=q0,q1,...ql and d=d0,d1,..,dn, the bags of embedding Eq and Ed are constructed as follows: (# stands for [mask] token)

3-3 Late Interaction
For a query q and a document d, we will denote the relevance score as Sqd. Sqd is computed by summing the values obtained through cosine similarity or sqaured L2 distance, as mentioned earlier.
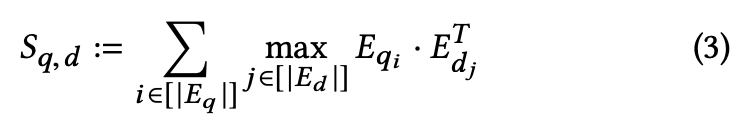
3-4 Offline Indexing: Computing & Storing Document Embeddings
ColBERT separates document and query computation, allowing the document representation to be computed in advance. During the indexing process, it computes the embedding of documents in the collection in batches with a document encoder and stores them.
When batching, pad all documents with the length of the longest document in the batch. It sorts the documents by length and passes them to the encoder in batches of similar lengths.
Once the document representation is created, it is stored on disk as 32-bit or 16-bit for each dimension and loaded for ranking or indexing.
3-5 Top-k Re-ranking with ColBERT
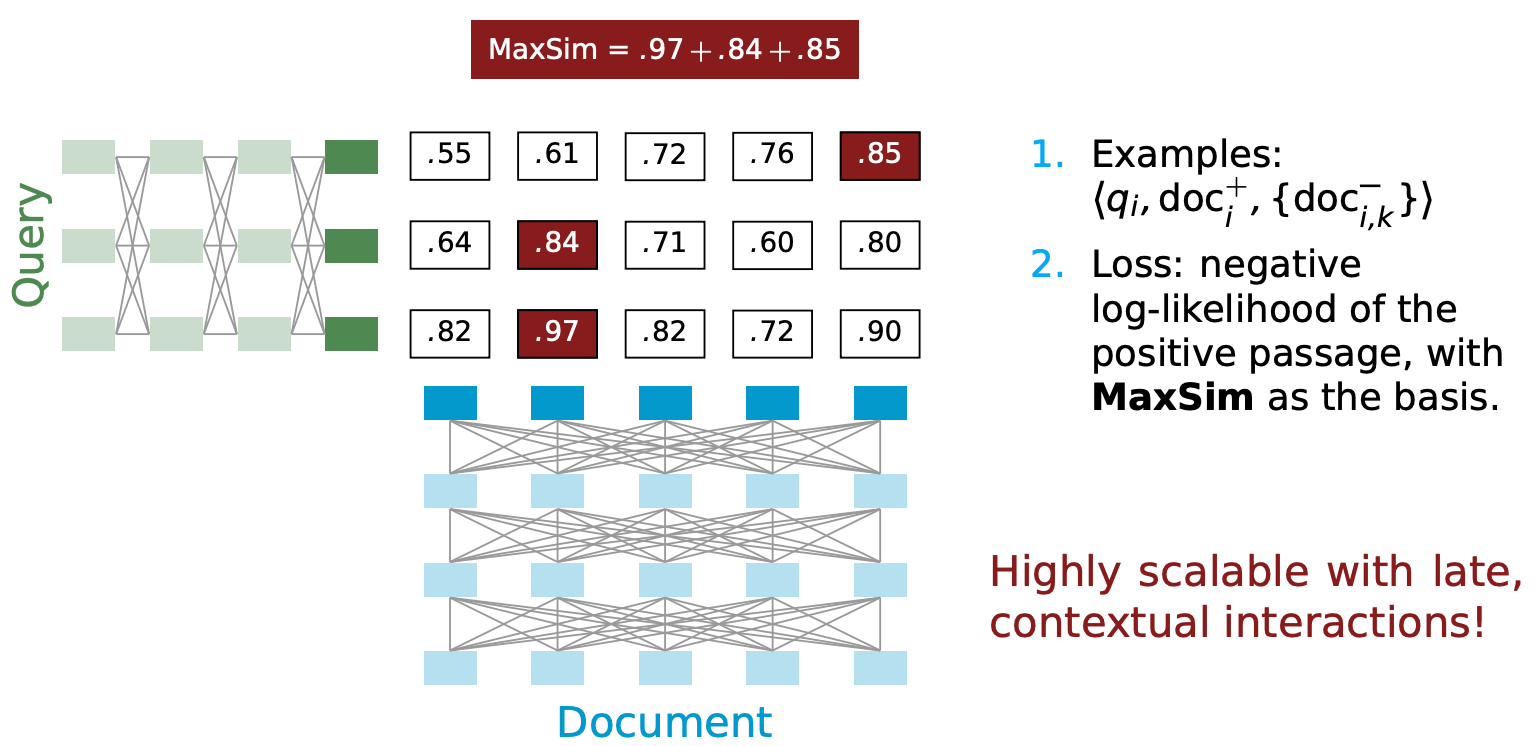
ColBERT can be used for both reranking and end-to-end retrieval.
Reranking has a small document set for a given query q. Since the document set is small, we store an indexed document representation in memory, representing each document as a matrix of embeddings.
Create a three-dimensional tensor D of the document set matrix while computing Eq with the given query. Since the batch job padded the documents to the maximum document length, we move this tensor D to the GPU and compute the batch dot-product for Eq and D. The resulting three-dimensional tensor is the cross match matrices for Q and each document. The score calculation is reduced by max-pool for document terms and sum for query terms. Select k documents, sorted by the scores computed.
Unlike other neural rankers (especially BERT-based), ColBERT is dominated by collecting and moving embeddings with a computed overall cost. A typical BERT ranker requires k inputs of query q and documents di to rank k documents, which increases the cost quadratically. However, ColBERT is much cheaper because it requires only one query input.
3-6 End-to-end Top-k Retrieval with ColBERT
For end-to-end retrieval, the document set N is quite large (over 10 million) compared to the top k.
MaxSim performs pruning when applying late interactions. Instead of applying MaxSim to the query embedding and all documents, we use vector similarity to find and compute only those documents that are relevant to the query. To do this, we can use a library like faiss. So we need to put each document embedding, document mapping, and document embedding index into faiss.
First, we perform Nq times of vector-similarity searches on faiss's index (for each embedding in Eq), each pulling out the top k' documents (k' = k/2). Then a total of Nq * k' documents will be candidates (with some overlap) that have a high similarity to the query embedding. And perform the reranking we covered earlier for these articles.
3-7 Evaluation
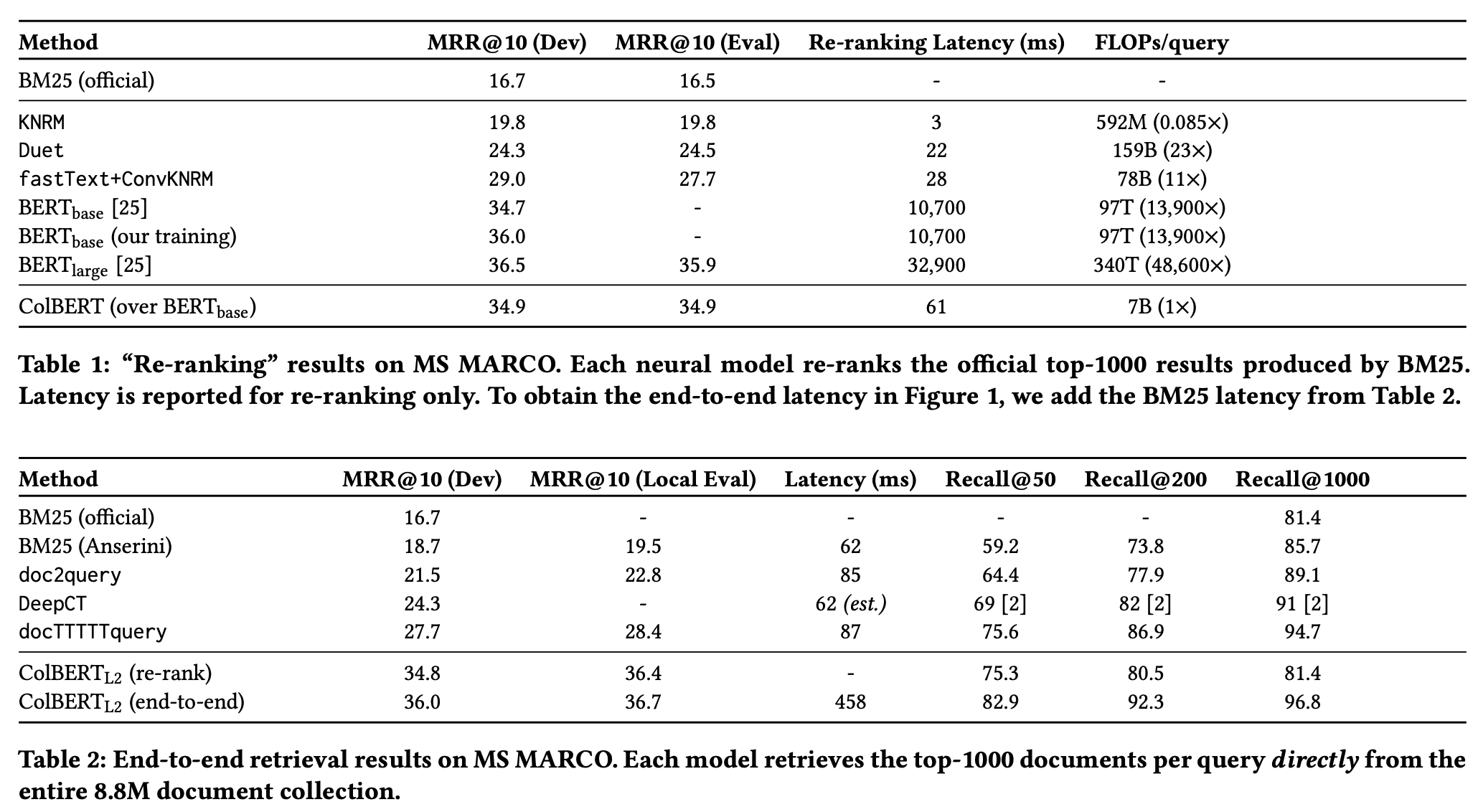
For reranking, the MRR is slightly lower than BERT, but the latency is much better.
End-to-end retrieval has a much lower latency than BM25, but a higher MRR.
4. ColBERTv2 (2022)
4-1 How ColBERTv2 came to be
ColBERT's late interaction was less burdensome on the encoder, but the cost was significantly impacted by the space size of the document. This is the tradeoff of moving from single-vector to multi-vector.
Meanwhile, there are many studies on compressing vector representations in IR research. Based on this research, ColBERTv2 uses a lightweight token representation to efficiently use storage.
4-2 Modeling
ColBERTv2's model is based on the architecture of ColBERT. Queries and documents are encoded by BERT respectively, and the output embedding is low-dimensional. During the offline indexing process, each document d is encoded and stored as a set of vectors. A query q is also encoded as a multi-vector and its score is computed with MaxSim over document d.
4-3 Representation
It was verified through experiments that regions of the ColBERT vector cluster contain tokens with similar semantics. Using this for the residual representation reduces the space footprint and achieve off-the-shelf.
For any given centroid set C, ColBERTv2 encodes each vector v as the index of the nearest centroid Ct and calculates the residual vector (denoted r) as v-Ct. Quantize this residual vector and store it as a approximated vector (denoted ~r). This allows the search to find a ~v that is close to the original vector, requiring only the centroid index t and ~r.
To encode ~r, quantize each dimension of r into one or two bits. It is known that b-bit encoding of an n-dimensional vector requires log|C| + bn bits per vector. In the paper, we used n = 128 and b=1,2 to encode the residual. While ColBERT uses 256-byte vector encoding at 16-bit precision, we have shown that it can encode vectors with 20 or 36 bytes.
4-4 Indexing
ColBERTv2 divides indexing into three stages.
(1) Centroid Selection
Choose a centroids cluster set C for residual encoding. Typically, the size of |C| is set proportional to the root value of the number of embeddings. However, to reduce memory consumption, use k-means clustering with embeddings generated by putting document samples proportional to the root of the collection size into the BERT encoder and found that it actually worked better.
(2) Passage Encoding
Encode all documents with the selected centroid. Find the closest centroid to each embedding and compute the quantized residual, as we saw earlier. Save the compressed representation to disk.
(3) Index Inversion
To support fast nearest neighbor search, we group embedding IDs with the same centroid and create an inverted list of them and store it on disk. This allows us to quickly find token-level embeddings when a query comes in.
4-5 Retrieval
For every vector Qi in a given query Q, find at least one closest centroid. Use an inverted list to find the document embeddings close to each centroid, decompress them, and compute the cosine similarity for each query vector.
For each query token, shortlist the top-n documents. These are the documents that will load the complete embedding. Rank these documents by computing the Sqd we saw earlier.
4-6 Evaluation
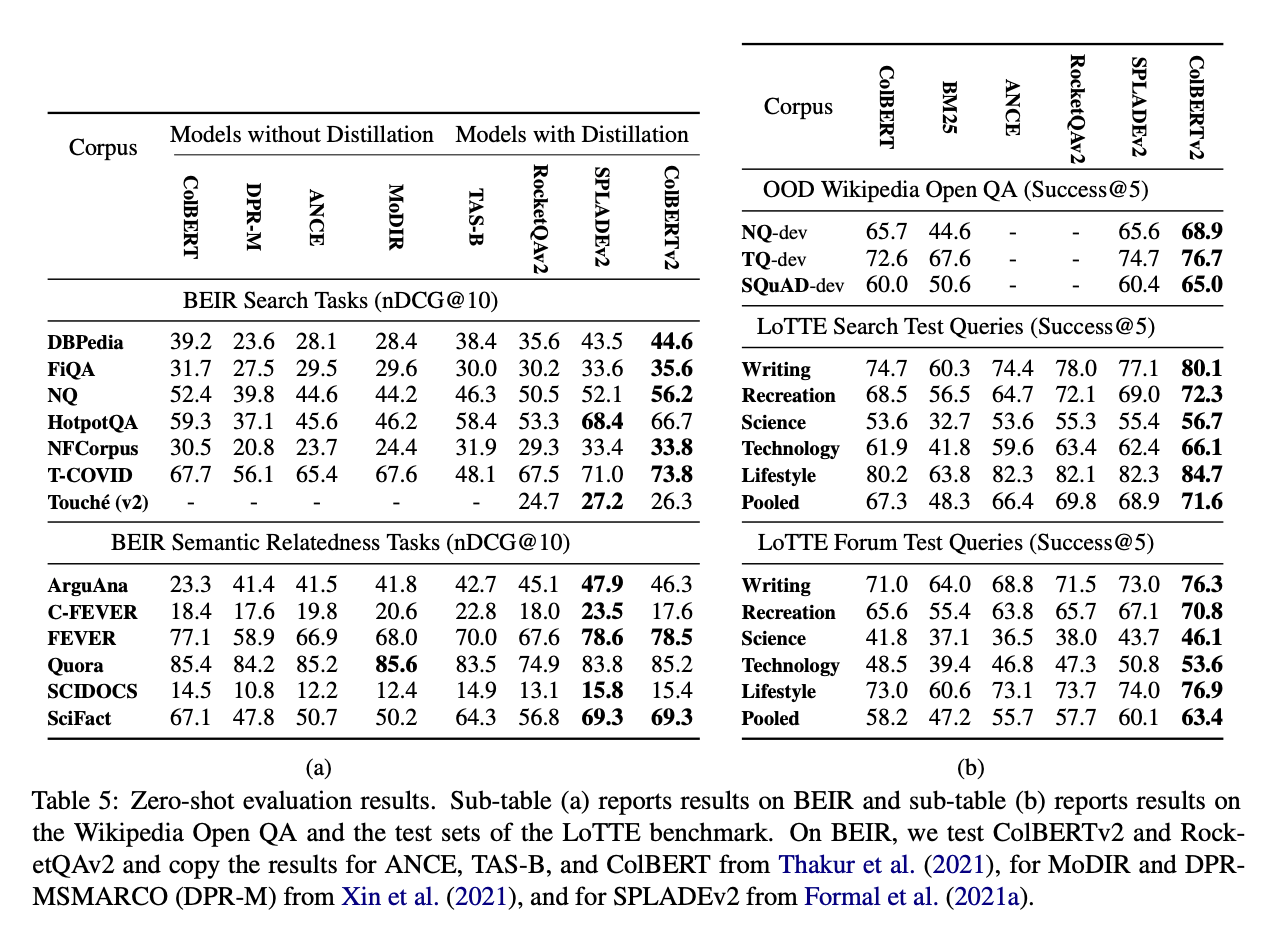
BEIR: Collection for out of domain test
LoTTE: Long-Tail Topic-stratified Evaluation with the dataset introduced in the paper.
You can see that ColBERTv2's recommendation performance is better than other models. However, it was disappointing that there was no evaluation of latency.
[Reference]
Stanford CS224U Nerual IR youtube
Standford CS224U Information Retrieval handout
ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction