
A guide to the LLM Agent Framework for the average developer

There's talk of AI and LLM everywhere these days.
I think it's less and less necessary to study the LLM model or serve to be good at LLM, because there are more and more services that offer LLM APIs, and the price is dropping over time.
Beyond the LLM model, companies are also releasing services that utilize AI. AI agents are software systems that utilize AI to perform tasks on behalf of the user to accomplish goals. Examples include Manus, which recently made waves.
In this article, we'll talk about agents that utilize LLMs. While the AI agent in the media is a big, system-level concept, we're talking about the smallest agents that make up that system.
We'll start with a brief survey paper to get an idea of LLM agents. Then we'll look at a test generation system that utilizes LLM agents published by Meta. Finally, we'll look at frameworks that deal with multiple LLM agents and talk about how I utilize them.
1. LLM Agent Trends
This article is organized based on the contents of A Survey on Large Language Model based Autonomous Agents.
This paper refers to LLM agents as LLM based Autonomous Agents, but for the sake of consistency, we will use the term LLM agents instead.
The paper summarizes trends in agent research, focusing on two issues
- How have agent architectures been designed to make LLMs better?
- How have we enhanced the capabilities of agents to perform different tasks?
We'll summarize both perspectives in turn.
1.1 Agent architecture design
LLMs have evolved to be able to do a wide variety of tasks in the Question - Answer format.
However, the LLM agent we're talking about is far from the question-answer problem that LLMs are good at. Agents, like humans, need to recognize and learn about their environment and perform specific roles through it.
For an existing LLM to fulfill the role of an agent, it is important to design the architecture well to maximize the capabilities of the LLM. Existing researchers have developed various modules to enhance the functionality of LLMs.
In this thesis, we synthesize these studies and present a framework for designing an agent architecture.
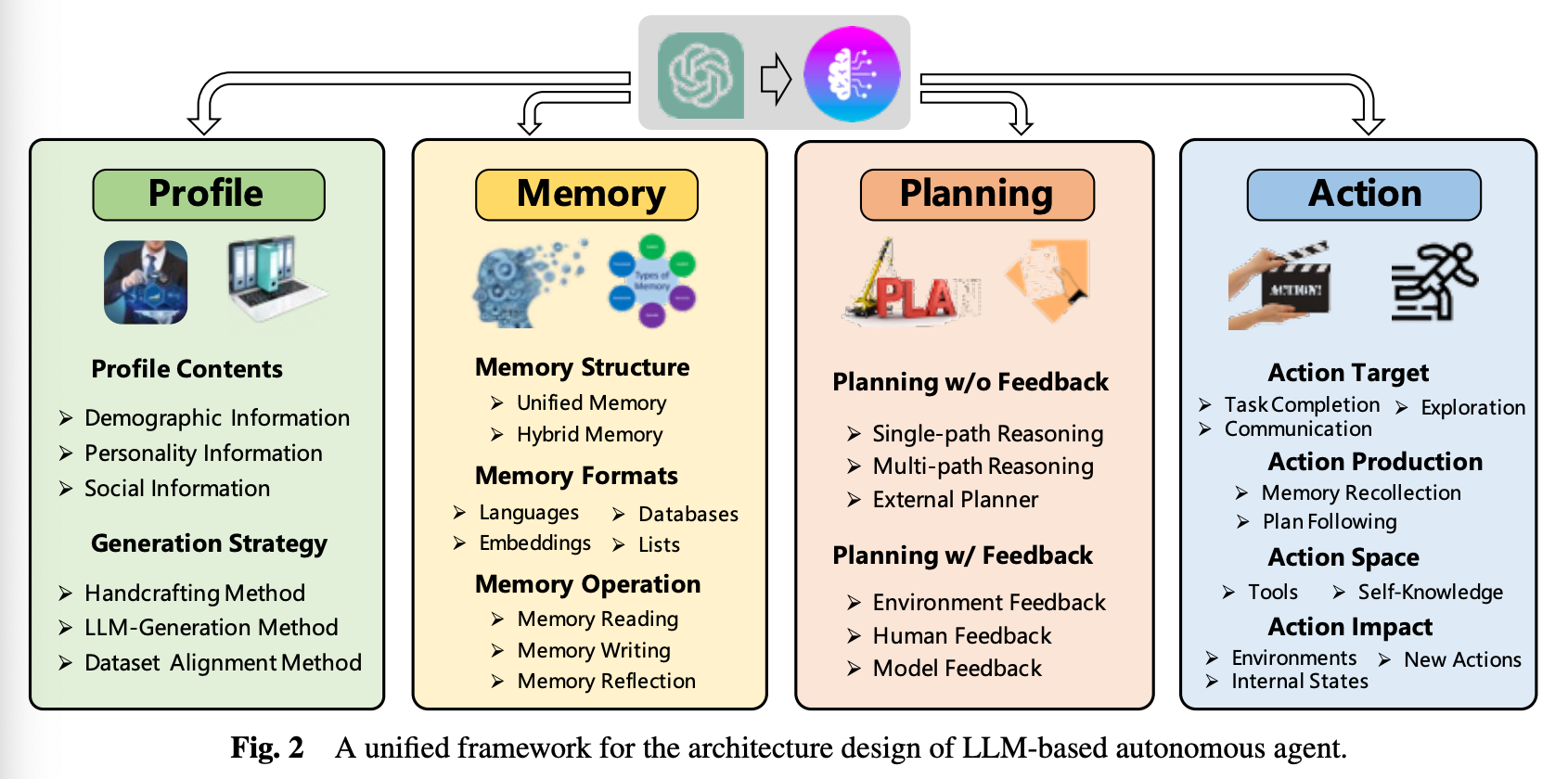
The framework categorizes modules into four categories
- Profiling: Understanding the role of the agent
- memory: Remembering the agent's past behavior
- planning: Planning future behavior
- action: Translate the agent's decisions into outputs
In short, all four of these modules are required for an agent to behave like a human.
Let's take a quick look at what each module does.
1.1.1 Profiling Module
It specifies the profile of a certain agent role.
You can specify age, gender, career, personality, etc. or even have social information between agents.
For example, you might write “You're an active person” in an agent's profile and include it in the agent's LLM runtime prompt.
Profiles are often defined by humans, but if that's not possible, you can have LLM create them for you, or you can use information about people in the actual dataset as prompts.
1.1.2 Memory Module
Memory can be divided into short term memory and long term memory.
You can think of short term memory as using input memory within the context window of the transformer architecture, while long term memory is using external vector storage.
When using only short term memory, all state is served by LLM prompts, which has the disadvantage that memory is limited by the LLM's context window.
Long term memory is memory that is used infrequently, stored in a vector DB, and retrieved and used when needed. For example, an agent might store the context of its current situation in prompts and its previous actions in a vector DB.
Making good use of memory is important for an agent to interact with its environment. We can categorize the way an agent deals with memory into three different ways: read, write, and reflection.
For reading, the more recent the memory, the more relevant it is to the request, and the more important it is, the better the extraction should be. For relevance, we use ANNOY, FAISS, and others that utilize vector search algorithms like LSH, HNSW, and others. For importance, it reflects the nature of the memory itself. Most studies still only reflect relevance.
For write, it's about storing information about the environment that the agent is aware of in memory. The question is how to store redundant information, and which memory to clear when storage space runs out. Memory redundancy can be solved by collecting similar memories and combining and refining them when they reach a certain size. Excess storage can be cleared by user command (ChatDB) or by using a FIFO (RET-LLM).
Reflection is about giving agents the ability to summarize and reason independently, for example, in the case of Generative Agents, summarizing past experience into abstracted insights. It does this by sequentially generating three questions based on recent memory, which it uses to extract information from memory. From this information, the agent then generates five insights.
By giving the agent a memory module, the agent can learn and complete tasks in a dynamic environment.
1.1.3 Planning Module
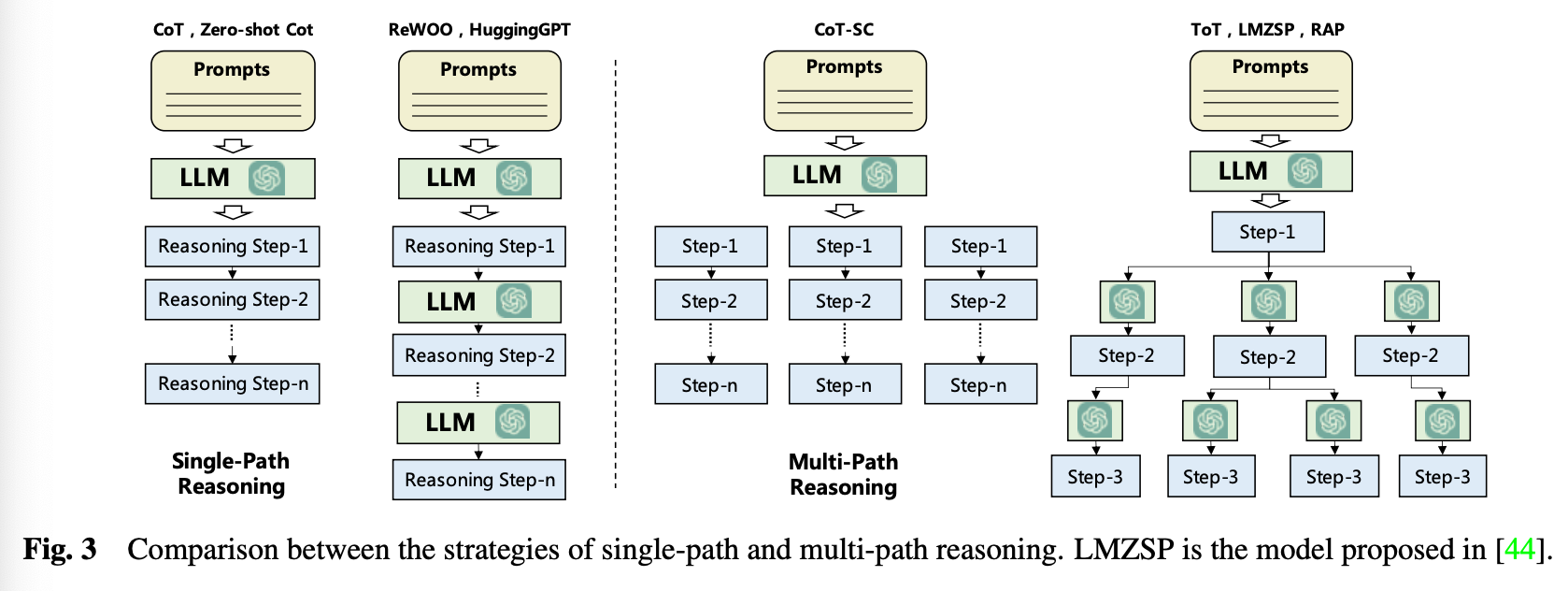
Just as humans break down work into simple subtasks, the Planning module does something similar.
Plans can be categorized into two types: those that receive feedback and those that do not.
The figure above (Fig 3) is all Planning without feedback.
Single Path Reasoning is a Chain of Thought (CoT), where the LLM breaks down the task into multiple steps by including examples in the prompts.
Multi Path Reasoning generates multiple answers for each intermediate step. Self consistent CoT (CoT-SC) receives answers from multiple CoTs and selects the best one, and Tree of Thoughts (ToT), where each node creates a plan on its own again.
In the case of receiving feedback, the agent acts on the plan and then receives feedback.
ReAct receives feedback after execution by search engines, for example, and Voyager receives feedback from errors made by executing the programs it creates. In some cases, feedback is provided by using the trained model as an evaluator.
1.1.4 Action Module
Actions can be divided into four categories: goal, production, space, and impact.
Goals of actions include performing a specific task, sharing information with other agents or users, and navigating an unfamiliar environment.
Actions can be performed in two ways: by extracting information from the agent's memory, or by following a plan that has been passed to it. For example, if the agent has done a similar task before, it may have a strategy for performing according to a plan if it hasn't already.
The space can be divided into external tools and LLM intrinsic knowledge. External tools are APIs, databases, external models, etc.
The impact can be changing the state of the environment (moving around in the game, collecting items, etc.), changing the state of the agent (updating memory, making a plan), or generating a new action (constructing a building when you collect all the resources you need in the game).
1.2 Enhance agent capability
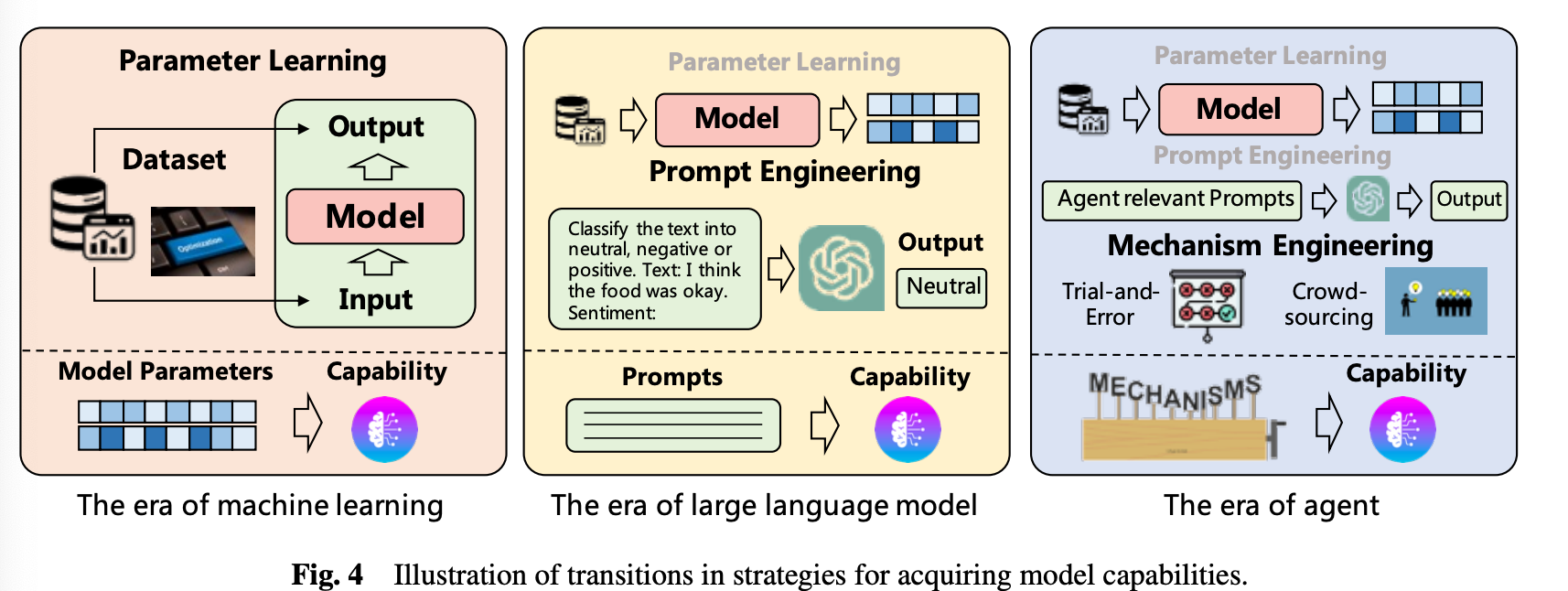
In the figure above, you can see that over time, methods have been added to enhance the power of the model.
In traditional machine learning, fine tuning methods, which dissolve data into the parameters of the model, were often used. In the LLM era, prompt engineering was used to improve the ability of LLMs without directly training the data.
In the agent era, mechanism engineering was added to these two methods.
Let's introduce some of the types of mechanism engineering
(1) Trial-and-error: The agent tries an action first and gets feedback.
(2) Crowd sourcing: An agent generates answers to a given problem with other agents. If their answers don't match, they respond again, including the answers of other agents. This is repeated until a finalized answer is found. This method requires each agent to be able to understand and combine the answers of other agents.
(3) Experience accumulation: GITM (Ghost in the Minecraft) stores successful actions in memory as the agent explores. When it encounters similar tasks in the future, it pulls in the successful actions to solve them.
(4) Self-driven Evolution: By setting up a reward function or integrating a LLM that gives feedback to the multi-agent system, it can give and receive feedback and improve itself.
2. Test generator created using Agent in Meta
What kind of services can you create using LLM agents?
Meta shared an example of using LLM agents to create a Mutation test generator on their tech blog
The purpose of Mutation testing is to see how well the test code we have in place can detect what's wrong when the source code is changed. So, we make some changes to the source code to create a mutation and measure if the test code detects it.
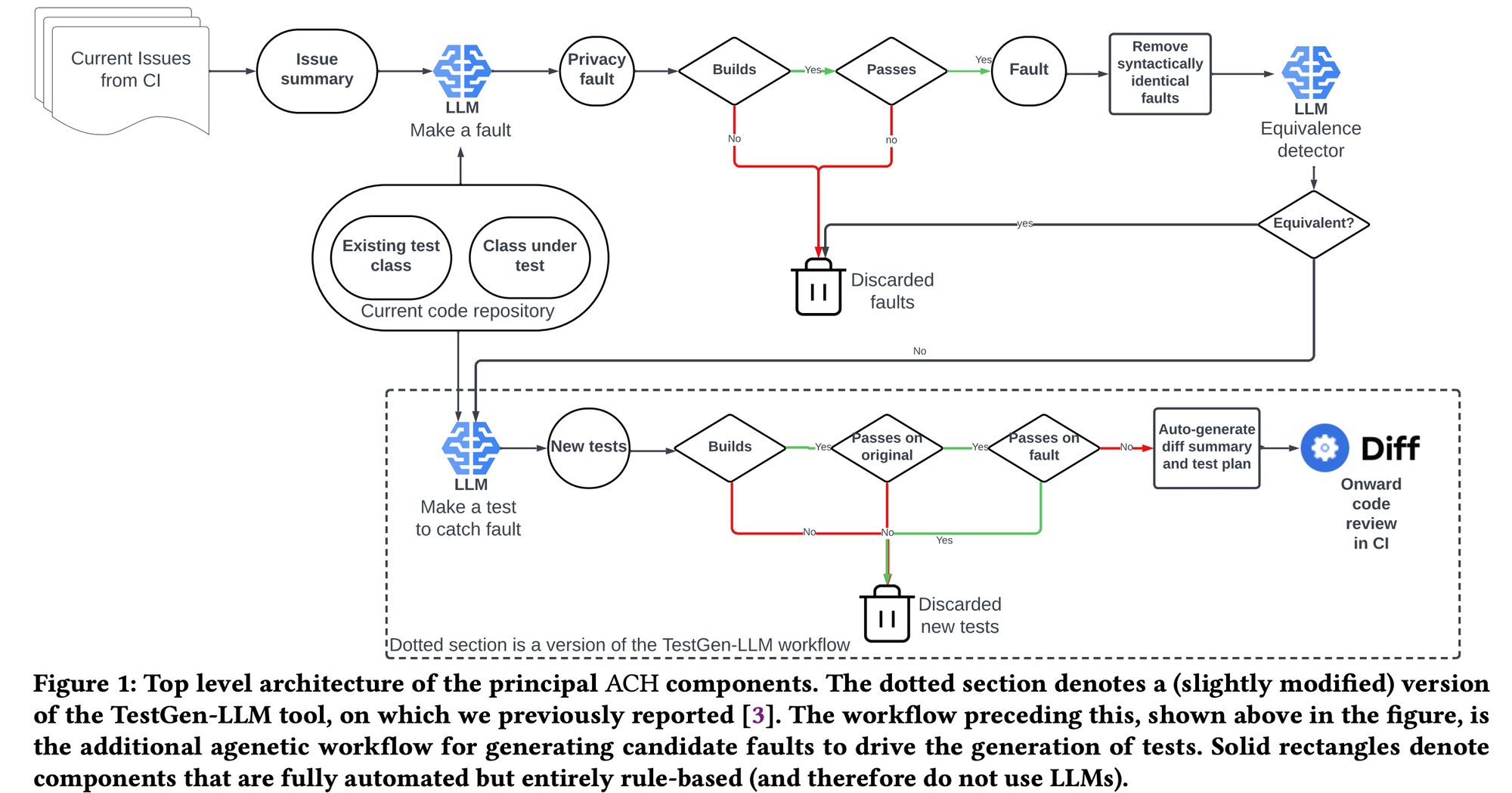
Meta created a system to generate mutants and introduced it as Automated Compliance Hardening (ACH).
If you look closely at the components of ACH, you can see the LLM in the middle.
ACH has a total of three LLM components
- Make a fault: Creates a mutant
- Equivalence detector: discards the generated mutant if it is logically equivalent to the existing code
- Make a test to catch fault: Creates a test that can detect the mutant you created
These components can be thought of as a kind of LLM agent. You can see the prompts we used for these LLM agents in the paper.

ACH can be thought of as an AI agent service that generates mutants, with three LLM agents as the core components of ACH.
Isn't the structure simpler than you think?
3. Introducing Multi-Agent Frameworks: MetaGPT, Autogen
It is much more accurate to have multiple agents working together to accomplish a task than it is to have a single LLM agent. In “1. Trends in LLM Agents”, we introduced the idea of agents giving each other feedback as a way to improve their performance.
To this end, there are frameworks that help developers manage multiple LLM agents, two of which are MetaGPT and Autogen.
3.1 MetaGPT
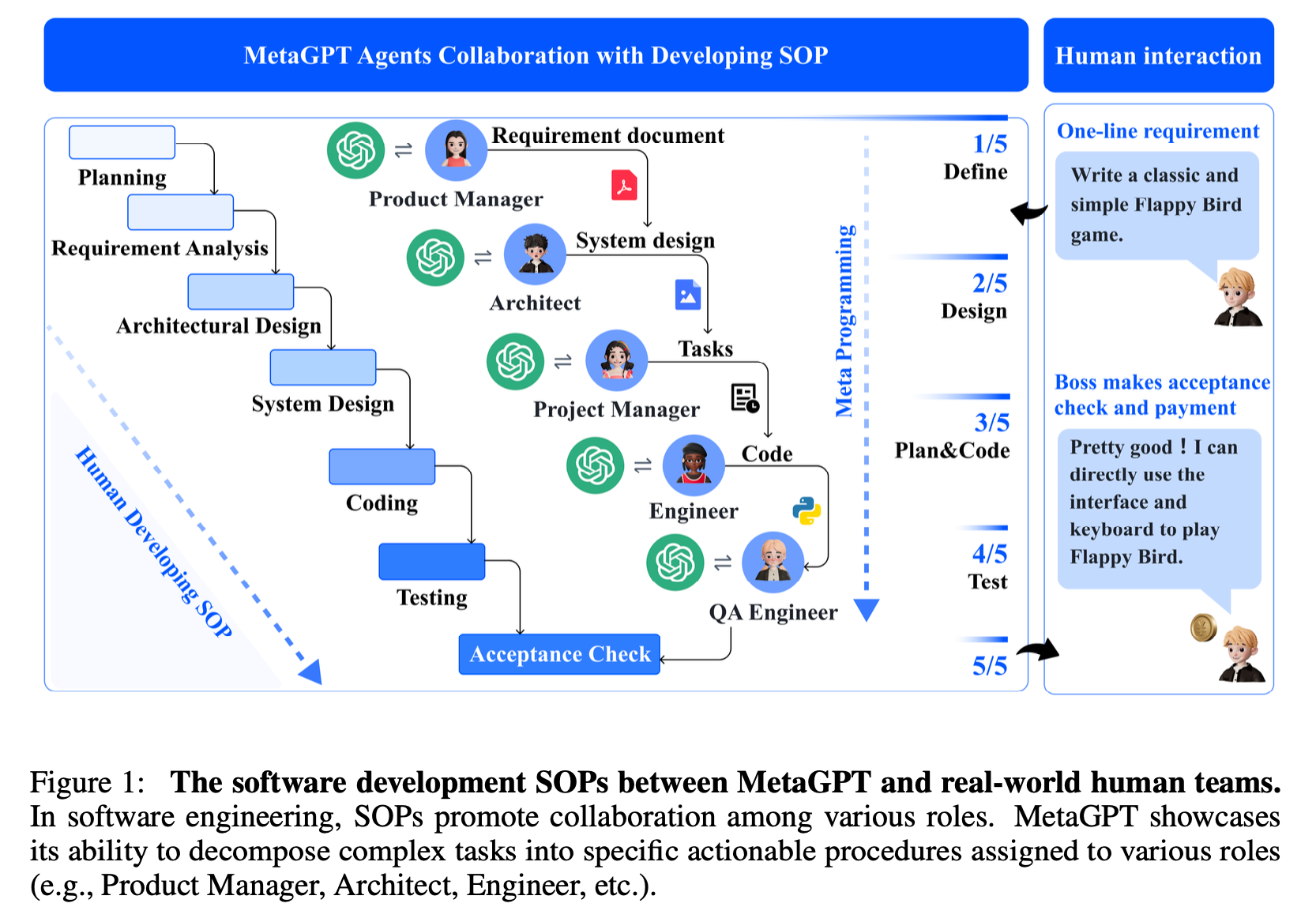
MetaGPT takes the approach of distributing roles across agents.
For example, in Figure 1, each agent has the roles of Product Manager, Architect, Project Manager, Enginner, and QA Enginner, which are the roles of a software company.
The idea is to create software through agents, so this is the structure of a real software company.
import asyncio
from metagpt.roles import (
Architect,
Engineer,
ProductManager,
ProjectManager,
)
from metagpt.team import TeamYou can define agents using the roles you've defined in MetaGPT, as shown above. Of course, you can also define your own roles.
class SimpleCoder(Role):
name: str = "Alice"
profile: str = "SimpleCoder"
def __init__(self, **kwargs):
super().__init__(**kwargs)
self._watch([UserRequirement])
self.set_actions([SimpleWriteCode])Coming back to Figure 1, the actual behavior looks something like Figure 2 below.
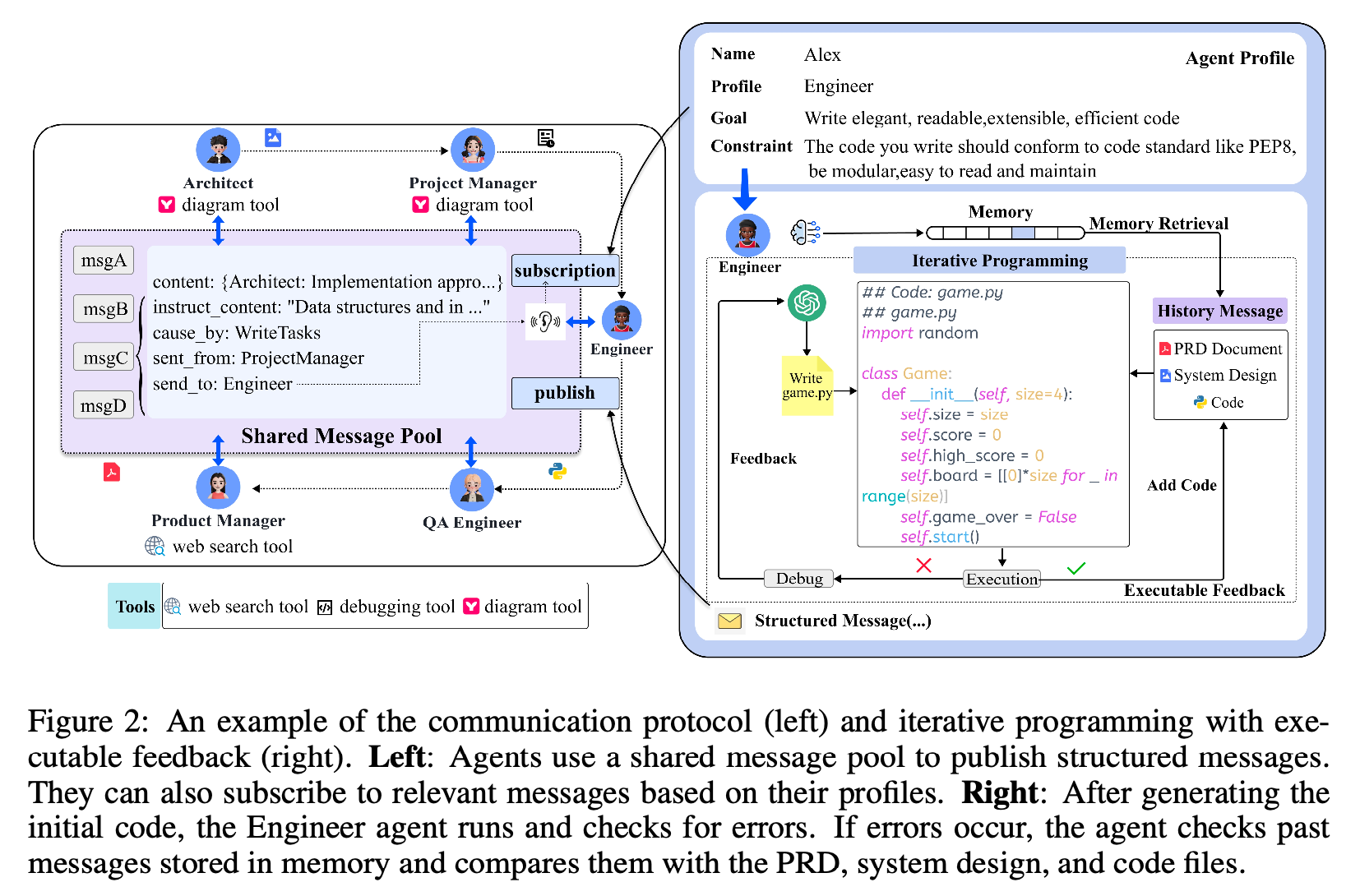
The general flow is that Architects materialize the components of the system design, Product Managers distribute work from the system design, and Engineers implement classes and functions.
The communication between the agents is done through a shared message pool. It would be inefficient for each agent to store their own information and ask other agents whenever they don't know something. MetaGPT uses a method where each agent publishes/subscribes information to the message pool and does not directly get information from other agents.
4.2 Autogen
Autogen is a multi-agent framework created by Microsoft.
It's not too different from MetaGPT in the grand scheme of things, but the way it distinguishes roles for agents is a little different.
For example, MetaGPT's roles are abstracted to support Architect, Product Manager, Engineer, and so on. Autogen supports UserProxyAgent (an agent that passes input from the user), WebSurfer (an agent that searches the web), and CodeExecution (an agent that executes code) roles at a slightly lower level, which means that the degree of abstraction that the framework primarily supports is slightly different.
While you can configure multiple agents directly through Autogen to create a multi-agent system, you can also use Magentic-One, which Autogen supports. Magentic-One is a multi-agent team defined by Autogen and can browse files, search the web, code, execute code, and more. The internal implementation of Magentic-One is naturally using Autogen.
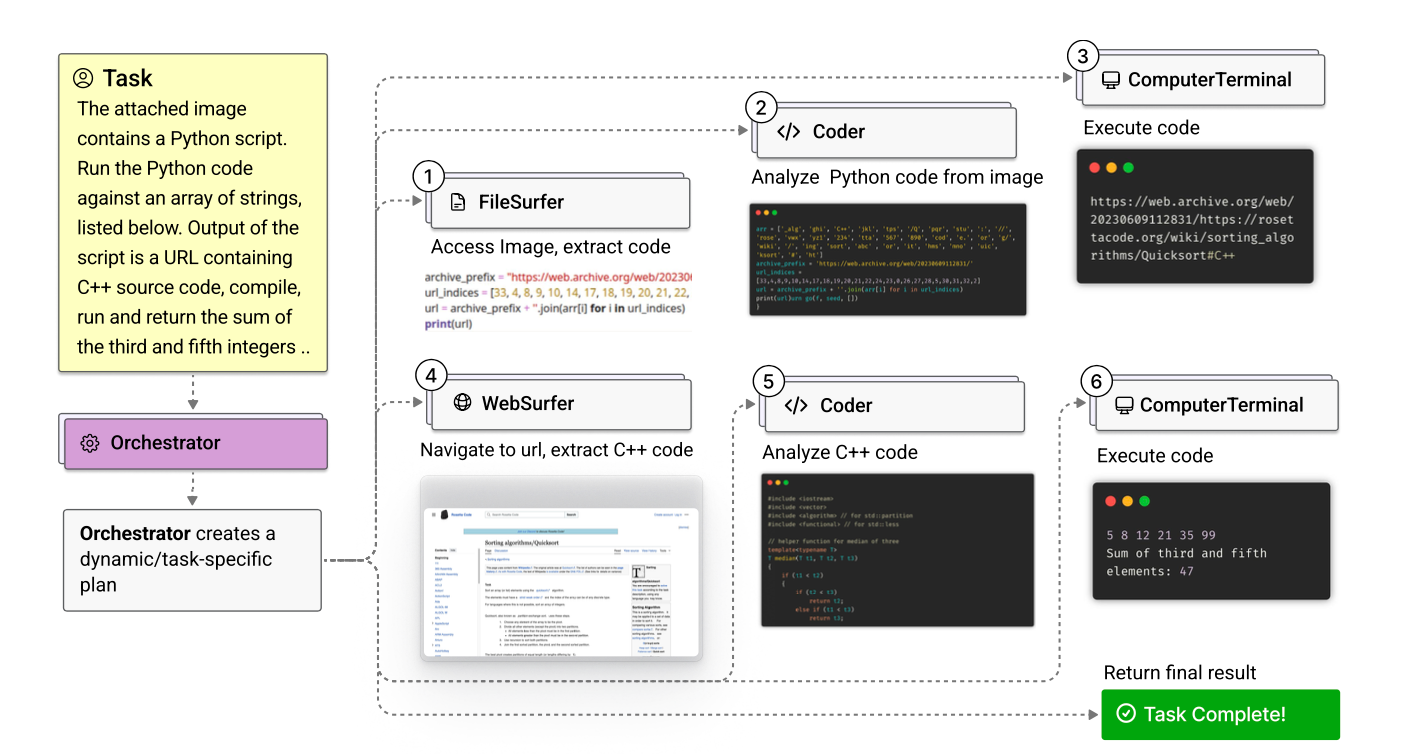
Magentic-One consists of an Orchestrator agent that coordinates tasks and Coder, ComputerTerminal, WebSurfer, and FileSurfer that perform tasks.
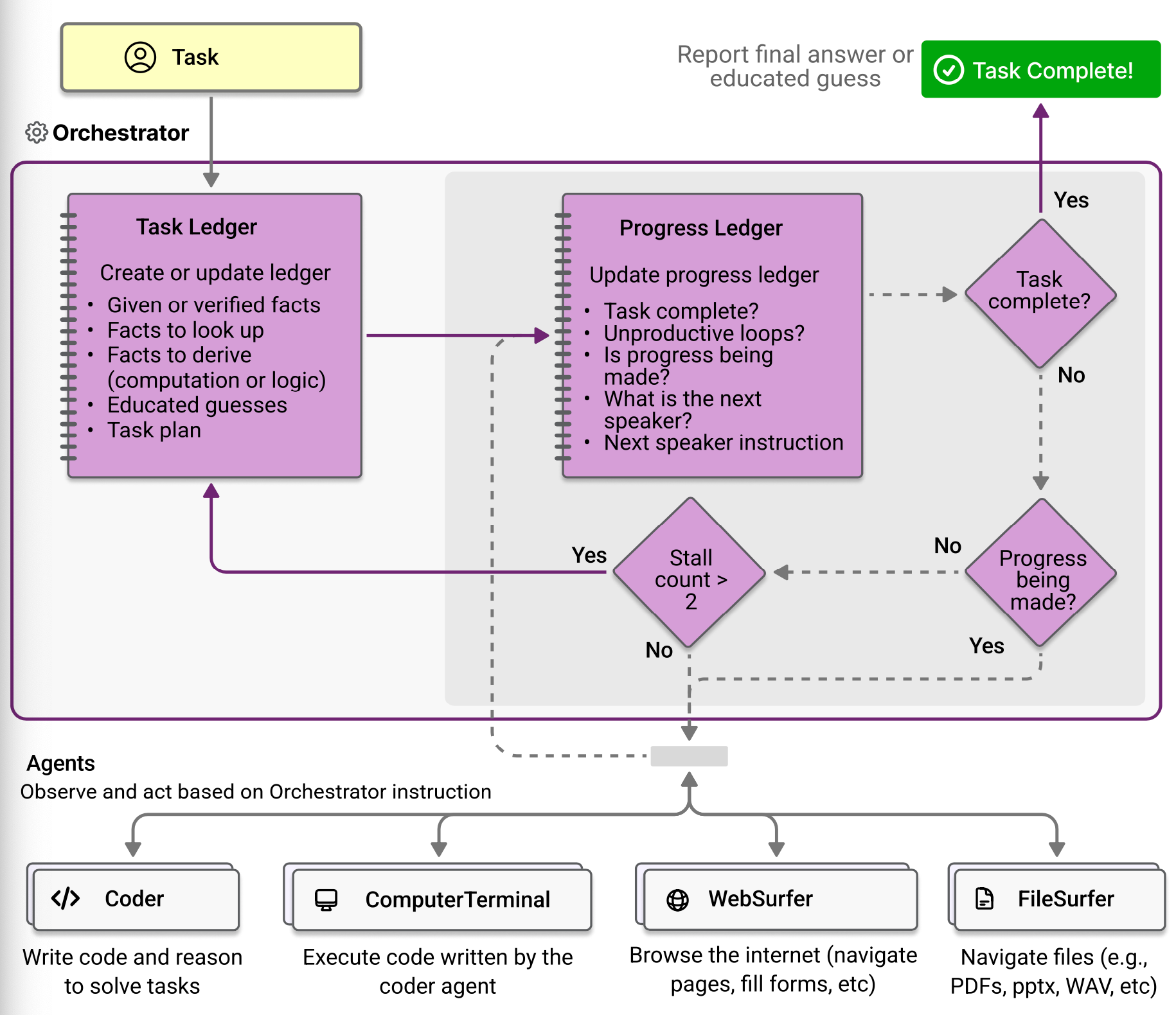
The Orchestrator has two loops: an outer loop that uses the task ledger and an inner loop that uses the progress leder.
Outer loop
Orchestrator uses the task ledger as short term memory. When it receives a task, orchestrator reflects on the request and creates a task ledger with the information it is given, information it needs to check (web searches), information it needs to compute (programming and reasoning), and learned guesses.
Once the task ledger is populated, orchestrator thinks about how to fulfill it. Using the team's membership information and the current task ledger, the orchestrator devises a step-by-step plan. This plan is expressed in natural language and consists of steps for each agent to perform.
The plan is similar to a chain of thought prompt, so neither the orchestrator nor the other agents need to follow it exactly. Once the plan is formed, the inner loop begins.
Inner loop
In each iteration of the inner loop, Orchestrator answers five questions to build a process ledger
- Is the task complete
- Is the team looping or iterating
- Has forward progress been made
- Which agent's turn it is to speak next
- What instructions or questions should be asked of that team member
As you answer questions, you decide which agents will perform which tasks and coordinate the sequence.
The Orchestrator internally checks to see if work is progressing, incrementing a counter if the loop is not progressing. When this counter crosses a threshold, it exits the inner loop to proceed with the outer loop and allows the results from the inner loop to be reflected in the outer loop so that the plan can be changed.
Types of Agents
Here is a brief introduction to the types of agents used in Magentic-One.
WebSurfer
- When WebSurfer receives a request, it maps it to an action in one of its action spaces and reports the new state of the web page with a screenshot and description.
- WebSurfer's action spaces consist of naviagtion (visiting a URL, performing a web search, scrolling within a web page), web page actions (clicking and typing), and reading actions (summarizing and answering questions).
- The reading action allows the WebSurfer to ask a document Q&A within the context of the entire document, reducing round trips to the orchestrator.
- When interacting with a web page (clicking, typing), WebSurfer acts on the current web page. In the paper, they used set of marks prompting.
For reference, set of marks prompting is a way of segmenting an input image into meaningful regions and overlaying each region with a mark.

FileSurfer
- Similar to Websurfer, except that it uses a custom markdown-based file preview application.
- It can handle PDFs, office documents, images, video, and audio.
- It also has the ability to list directories and navigate folder structures.
ComputerTerminal
- Provides a console shell that allows you to run programs.
- ComputerTerminal can run shell commands, and programming libraries are available for download and installation.
4. How I'm using it
As a side project in my company, I'm building a multi-agent E2E test automation system.
Unlike unit tests, E2E tests are complex to organize test logic because the same API returns different results depending on the state of the application.
The rough structure is as follows
(1) Check the application state
(2) Expect the result of the API under test accordingly
(3) Compare expected results after calling the API under test
I've demoed a system using Autogen that does all of (1), (2), and (3). I can't reveal all of it, but here's the basic structure.
- An agent, like Magentic-One's orchestrator, that determines the order in which agents perform
- A Planner that draws the overall test structure
- Coder to generate code
- A Critic that judges the quality of the code
- Executor to carry out the code
This project has even succeeded in automatically generating tests for the project I'm currently working on as my main one. I'll briefly share what I realized while working on it.
- The roles of each agent should be as granular as possible.
- The more specific you can be with your prompts, the better.
- Agents that do big picture planning, such as designing test structures, need to use LLM models beyond OpenAI's 4o model to properly generate plans.
- We often use 90,000 or 100,000 tokens because of the large number of LLM calls that occur in a single use of the system.
- Because of this, techniques to reduce the number of tokens are essential for proper utilization.
I'm working on this project as I have time and hope to make it publicly available in the future.
If you're interested in LLM agents, I recommend following the tutorials on Autogen or MetaGPT right away to get a feel for how it works. You'll find that it's not as hard as you think it is.
Reference
A Survey on Large Language Model based Autonomous Agents
Revolutionizing software testing: Introducing LLM-powered bug catch
METAGPT: META PROGRAMMING FOR A MULTI-AGENT COLLABORATIVE FRAMEWORK