
[논문 리뷰] ColBERT, ColBERTv2
![[논문 리뷰] ColBERT, ColBERTv2](https://images.unsplash.com/photo-1457369804613-52c61a468e7d?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDMyfHxSZXNlYXJjaHxlbnwwfHx8fDE2ODk5NDkyMjl8MA&ixlib=rb-4.0.3&q=80&w=2000)
[요약]
1. IR의 랭킹 방법은 BM25가 널리 쓰이고 있지만 2016년부터 Neural Network를 사용한 랭킹 방법들이 등장하기 시작했다.
2. Neural IR은 대체로 높은 MRR을 보여주었지만 계산이 비싸다는 단점이 있었다. 특히 BERT는 월등한 MRR을 보이지만 서비스에 적용하기에 너무 느리다.
3. ColBERT는 BERT보다 약간 모자란 MRR을 보이지만 훨씬 빠른 성능을 보여주었다.
4. ColBERTv2는 centroid를 사용한 압축으로 ColBERT보다 적은 스토리지를 사용하고 랭킹 성능도 향상시켰다.
[목차]
1. ColBERT를 리뷰한 이유
2. Neural IR Ranking
3. ColBERT (2020)
4. ColBERTv2 (2022)
1. ColBERT를 리뷰한 이유
IR(Information Retrieval)은 쿼리를 받아 수 많은 문서들 중 적절한 문서들을 찾고 순위를 매겨 돌려주는 작업이다.
현재 필자는 회사에서 검색엔진을 구현하고 있으며 쿼리의 텀이 등장하는 문서들을 검색해 Return하는 부분을 담당한다. 필자처럼 후보 문서들을 검색하는 일도 중요하지만 최종적으로 사용자에게 보여지는 문서를 고르는 Ranking 작업도 굉장히 중요하다. 대부분의 사용자는 검색시 1 페이지를 넘어가지 않기 때문에 Ranking이 검색의 품질을 좌우한다해도 과언이 아니다.
전통적인 Ranking 방법으로 BM25를 많이 사용하고 있다. BM25는 TF-IDF와 비슷하지만 문서의 길이를 고려한 랭킹 함수이다. 어떤 텀에 대하여 해당 텀이 어떤 문서에 얼마나 많이 등장하였는지(많이 등장할수록 값이 커짐)와 얼마나 많은 문서에 등장했는지(많은 문서에 등장할수록 값이 작아짐)를 고려한다. BM25는 역색인 검색 엔진에서 미리 계산해 저장할 수 있기 때문에 많은 문서를 다루고 성능이 중요한 검색엔진에서 많이 사용되었다.
2016년 이후 Neural Layer를 이용한 Neural Ranking이 등장하기 시작했다. Neural Ranking은 좋은 재현율(검색된 문서들 중 적합한 문서가 얼마나 있는가)을 보여주었고 많은 기업들이 BERT와 같은 언어 모델을 사용하기 시작했다(google, MS bing). 네이버 검색은 ColBERT 적용을 Deview에서 발표하기도 하였다.
ColBERT는 2020년에 발표된 논문으로 지금 시점에서 꽤 오래된 논문이다. 하지만 2023년 지금까지도 ColBERT를 베이스로한 후속 연구들이 끊임없이 나오고 있다. 현재 Neural IR을 논할 때 ColBERT를 빠뜨릴 수 없는 이유이다.
이번 글에서는 ColBERT(2020)와 ColBERT 1저자가 참여한 후속 논문인 ColBERTv2(2022)를 리뷰할 것이다. ColBERT를 이해하는데 필요한 Neural IR Ranking을 먼저 다루고 ColBERT와 ColBERTv2를 차례로 볼 것이다.
2. Neural IR Ranking
IR Ranking이란 query-document pair에 대하여 점수를 매기고 이를 내림차순으로 정렬한 이후 Top K개를 가져오는 것을 말한다.
앞서 말한대로 Neural Ranking이 본격적으로 쓰이기 전에는 BM25를 주로 사용했다. 하지만 2016년부터 Query-Document Interaction Model들이 등장하기 시작했다.
Query-Document Interaction Models (2016~2019)
KNRM, Conv-KRM, duet 등의 모델들이 이 카테고리에 속한다. 이 모델들이 점수를 계산하는 방법은 아래와 같다.
- 쿼리와 문서를 토크나이즈한다.
- 만들어진 토큰들을 벡터로 임베딩한다.
- query-document interaction matrix를 만든다. 이때 각 word의 pair에 대해 cosine similarity를 계산한다.
- 3에서 만든 matrix를 사용해 점수로 압축한다. 이때 neural Layer(convolution, linear layers ...)를 사용한다.
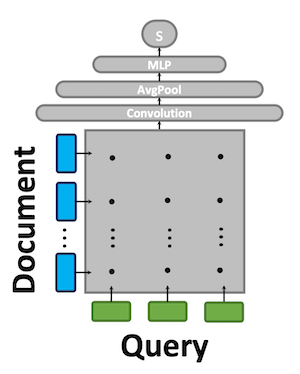
이러한 모델들은 computation이 증가하지만(query latency 증가) MRR이 높아지면서 만족할만한 성능을 냈다. 다만 latency 증가로 검색된 모든 문서에 적용하지 못하고 BM25에 의해 뽑힌 Top K개의 문서에 대해 주로 적용되었다(reranking).
BERT의 등장 (2019)
2019년 BERT의 classifier를 fine-tuning하여 랭킹에 사용하기 시작했다.
BERT를 랭킹에 사용한 방법은 아래와 같다.
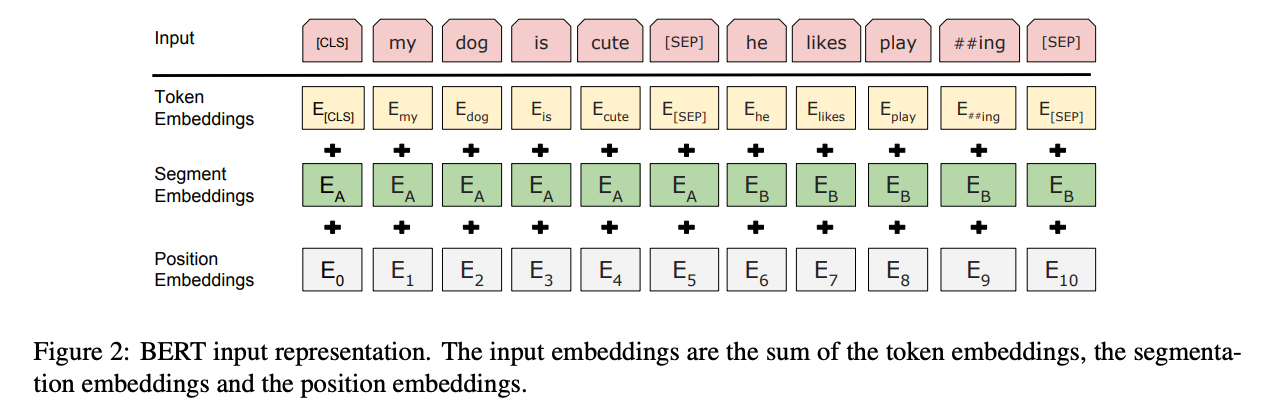
[사전 지식]
- [CLS] : Classification → 각 input sequence 시작에 넣어줘야 하는 토큰. BERT가 마지막 레이어에서 [CLS] 토큰이 있는 벡터를 aggregation 한다.
- [SEP] : Separation. BERT의 Input은 질문과 답처럼 분리된 task 사이에 [SEP]을 넣어야 한다.
[방법]
- BERT에게 “[CLS] Query [SEP] Document [SEP]” 형식으로 던져준다. 이때 input data로 [CLS]와 [SEP] 토큰을 포함해서 던져줘야 한다
- 모든 BERT 레이어에 대해 실행한다.
- 마지막 [CLS] output embedding에서 score를 추출한다.
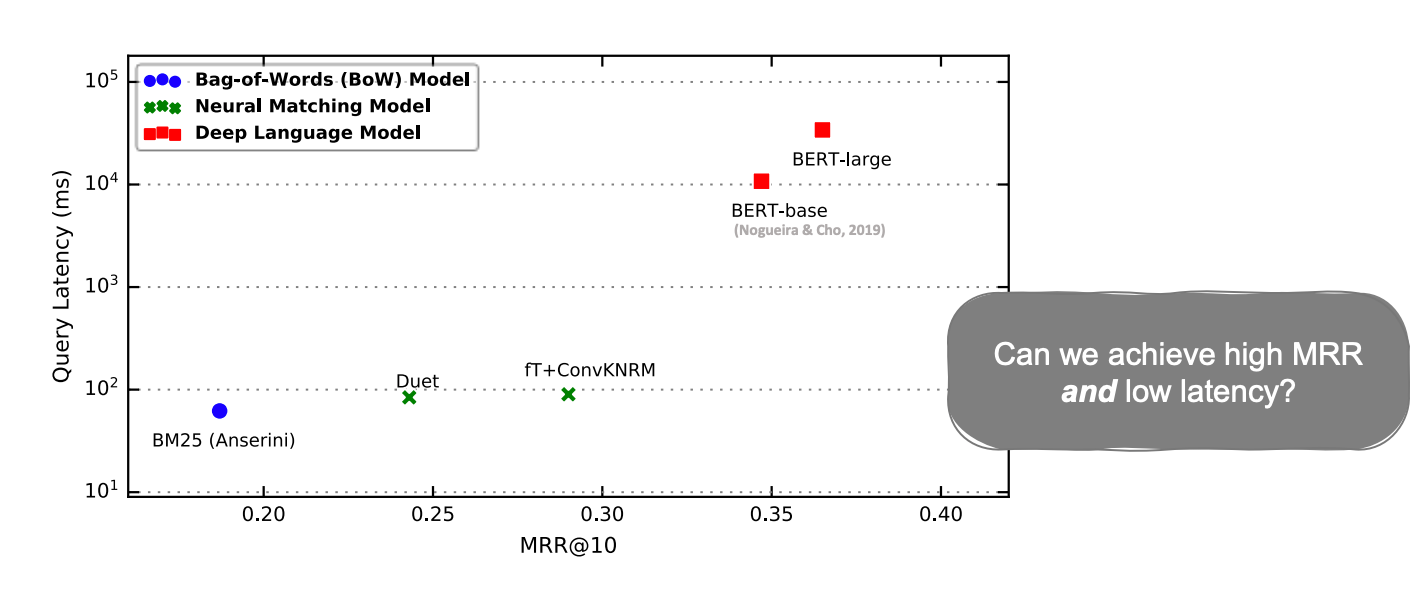
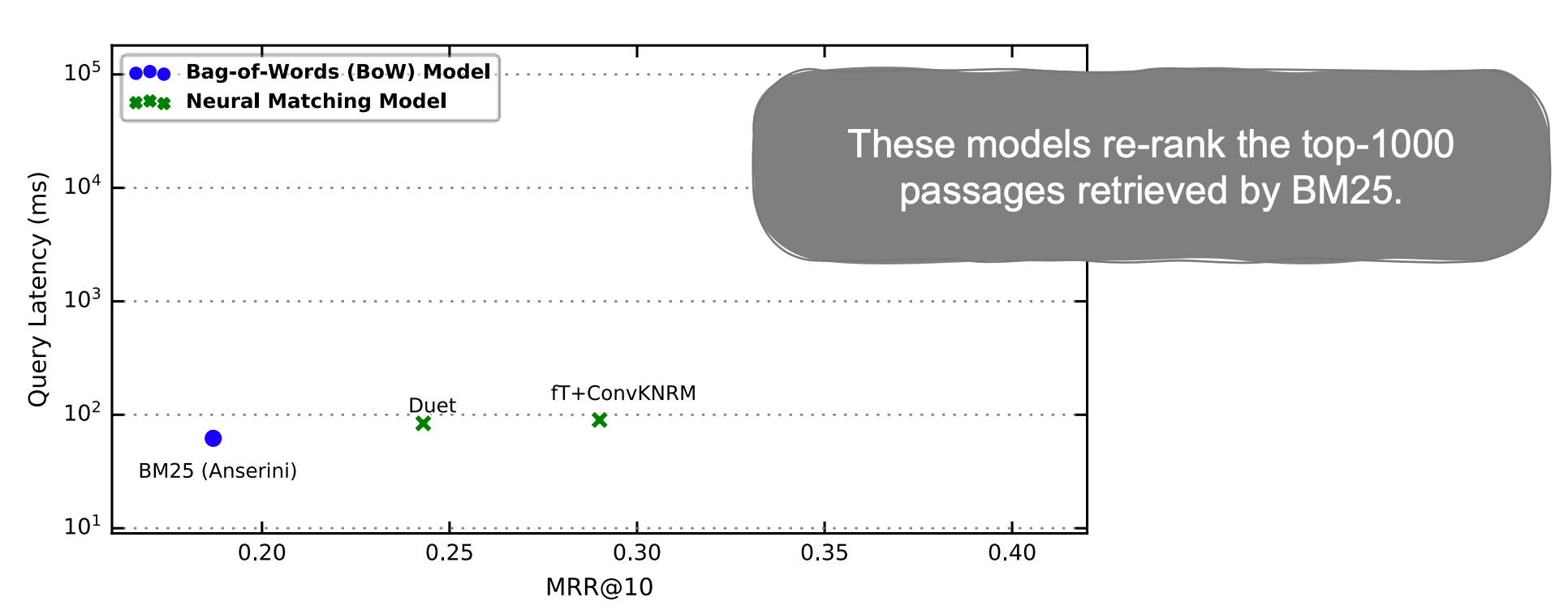
BERT는 높은 MRR을 보였지만 많은 computation이 필요하여 매우 높은 latency를 보였다. 위 그래프를 보면 BM25와 latency가 거의 100배 차이가 난다.
따라서 computation을 줄이면서 MRR을 높이기 위해 여러 연구들이 등장한다.
Representation Similarity
DPR(Dense Passage Retriever) (2020)가 대표적인 Representation Model이다. DPR은 각 문서와 쿼리를 768차원의 벡터로 인코딩하여 계산하였다.
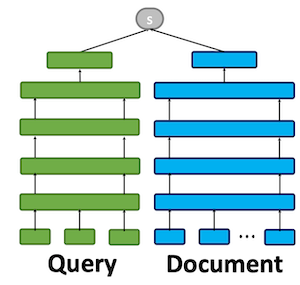
Representation Similarity 모델은 문서 Representation을 미리 계산하고 점수를 dot product나 cosine similiarity를 사용해 비용을 크게 줄였다. 굳이 Reranking에 사용처를 한정할 필요 없이 End-to-end Retrieval에 사용 가능할 정도였다. 문서 벡터 Representation은 인덱싱해 fast vector similarity search로 검색이 가능했기 때문이다. 이는 FAISS 같은 라이브러리를 사용하면 구현이 가능하다.
하지만 이렇게 하나의 벡터로 표현하다보니 coarse grain representation이 되어버려 텀 레벨 interaction이 없어졌다. 그래서 BERT보다 낮은 MRR을 보이는 단점이 있었다.
3. ColBERT (2020)
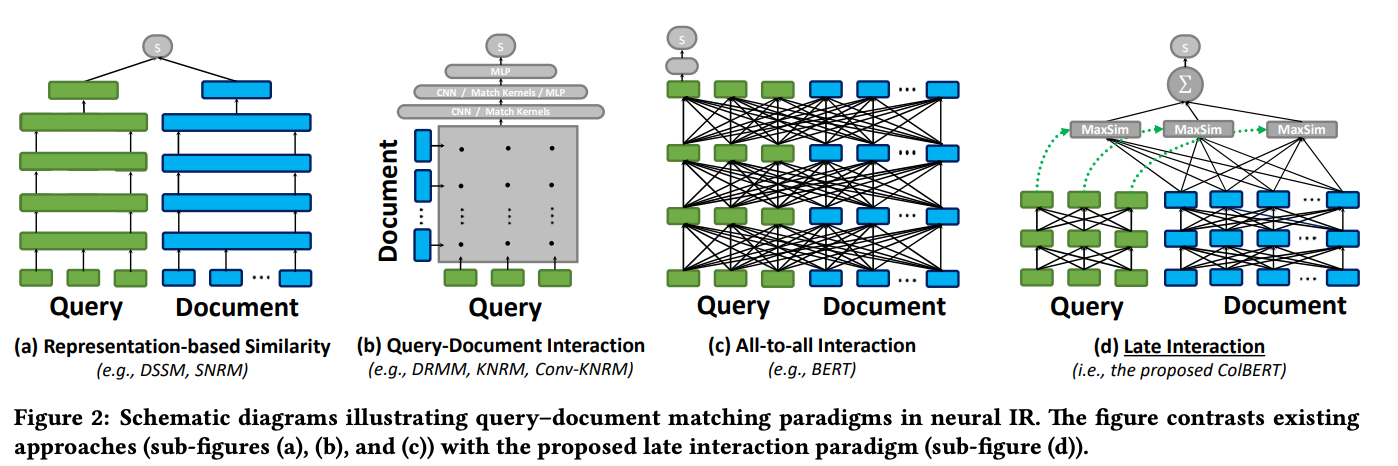
앞서 보았던 모델들을 통해 우리가 모델에 원하는 속성들을 도출하면 다음과 같다.
- 독립적인 인코딩 가능
- Fine grained representation
- Vector similarity search를 수행해 End to End Retrieval 가능
ColBERT는 이를 Late Interaction을 통해 가능하게 하였다. Late Interaction은 Representation Similarity 모델처럼 Document를 미리 offline에서 계산해 computation을 빠르게 만들었다.
3-1 Architecture
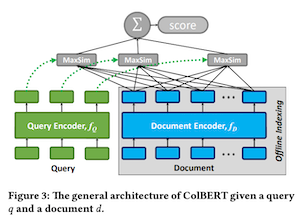
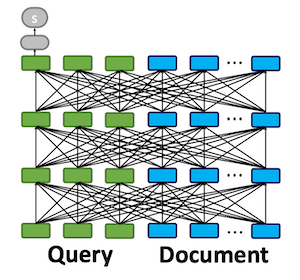
ColBERT의 아키텍처는 (a) Query encoder (b) document encoder (c) late interaction으로 구성되어 있다. Query encoder는 주어진 쿼리 q를 Eq로 임베딩하고 document encoder는 주어진 문서 d를 Ed로 임베딩한다.
ColBERT는 late interaction으로 relevance score를 계산할 때 maximum similarity(MaxSim) 오퍼레이터를 사용한다. MaxSim으로는 cosine이나 squared L2 distance를 사용한다. 모든 쿼리 텀에 대해서 각각 문서의 텀에 대해 MaxSim을 계산하고 이를 합쳐 스코어를 구한다.
Deep convolution이나 attenion layer와 같은 일반적인 interaction focused 모델을 사용하면 좀 더 복잡한 매칭이 가능하지만 MaxSim을 사용함으로써 얻을 수 있는 장점이 분명히 있다. (1)계산이 훨씬 싸고 (2)Top-k retrieval시 pruning을 효율적으로 할 수 있다.
3-2 Query & Document Encoders
Late interaction을 사용해 쿼리와 문서를 각각 임베딩하지만 하나의 BERT 모델을 공유하기 때문에 토큰 [Q]와 [D]를 사용해 인풋에서 쿼리와 문서를 구분해야 한다.
(1) Query Encoder
Query Encoder는 주어진 쿼리 q에 대해 BERT-based WordPiece 토큰 q1,q2,...ql로 토크나이즈한다. 그리고 토큰 [Q]를 쿼리 앞에 붙인다. 만약 쿼리가 미리 정해진 토큰 개수 Nq보다 적다면 BERT의 [mask]토큰을 붙여 패딩한다. mask 토큰을 패딩하는 것을 query argument라고 한다. Query argumentation은 새로운 텀으로 쿼리가 확장되거나 기존 텀의 가중치를 재조정할 때 영향을 준다.
Linear layer는 인코더로부터 represetnation을 넘겨받아 m-차원 인베딩을 만든다. ColBERT의 임베딩 차원 개수는 쿼리 실행 시간과 문서의 공간 관리에 큰 영향을 미친다. 시스템 메모리에서 GPU로 문서 representation이 옮겨져야하기 때문이다. ColBERT의 reranking에서 가장 비싼 스텝은 모으고, 쌓고, 이를 CPU에서 GPU로 옮기는 작업이다.
(2) Document Encoder
Document Encoder도 Query Encoder와 비슷한 구조를 가진다. 문서 d를 토큰 d1,d2,...,dm으로 만들고 BERT의 시작 토큰인 [CLS]를 문서 입력을 알리는 토큰 [D] 앞에 붙인다. 하지만 문서에는 [mask] 토큰을 붙이지 않는다. 이후 미리 정한 리스트를 통해 구두점 기호 등을 필터링하여 문서당 임베딩 개수를 줄이는 과정을 거친다.
요약하면 주어진 q=q0,q1,...ql과 d=d0,d1,..,dn에 대해 bags of embedding Eq와 Ed를 다음과 같이 만든다. (#은 [mask] 토큰을 뜻한다)

3-3 Late Interaction
쿼리 q와 문서 d에 대해 relevance score를 Sqd라고 표기하겠다. Sqd는 앞서 말했듯이 cosine similarity나 sqaured L2 distance를 통해 구한 값들을 합쳐 계산한다.
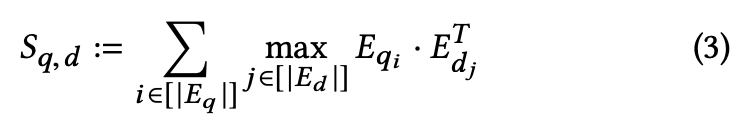
3-4 Offline Indexing: Computing & Storing Document Embeddings
ColBERT는 문서와 쿼리 계산을 분리시켜 문서 representation을 미리 계산하는 것이 가능하다. 색인 생성 과정에서 배치로 컬렉션에 있는 문서들을 document encoder로 임베딩을 계산하고 이를 저장한다.
배치 작업시 배치 문서 중 가장 긴 문서 길이로 모든 문서에 패딩을 한다. 이때 문서들을 길이로 정렬하고 여기서 다시 배치로 비슷한 길이의 문서들을 인코더에게 전달한다.
문서 representation이 생성되면 디스크에 각 차원마다 32bit나 16비트로 저장하고 랭킹이나 인덱싱시 로드하여 사용한다.
3-5 Top-k Re-ranking with ColBERT
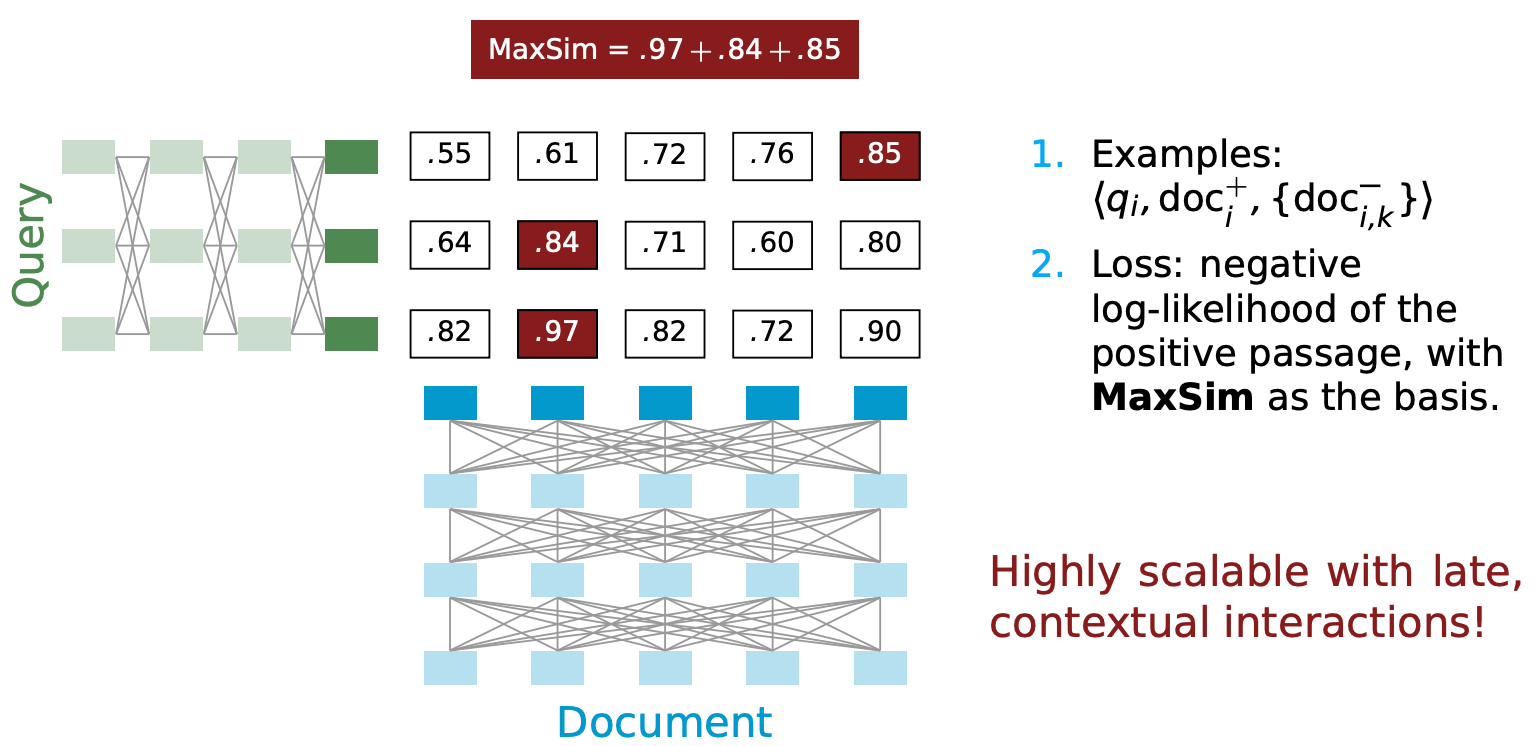
ColBERT는 reranking과 end-to-end retrieval에 모두 사용할 수 있다.
Reranking은 주어진 쿼리 q에 대해 문서 셋이 작다. 문서 셋이 작기 때문에 메모리에 색인된 문서 representation을 올려 각 문서를 matrix of embedding으로 표현한다.
주어진 쿼리로 Eq를 계산함과 동시에 문서 셋 matrix로 이루어진 3차원 tensor D를 만든다. 배치 작업에서 문서들을 최대 문서 길이로 패딩했기 때문에 이 tensor D를 GPU로 옮기고 Eq와 D에 대해 배치 dot-product를 계산한다. 결과로 나온 3차원 텐서는 q와 각 문서에 대한 cross match matrices이다. 점수 계산은 문서 term에 대해서 max-pool로, 쿼리 term에 대해서는 합쳐서 reduce한다. 이렇게 계산한 점수로 정렬해 k개의 문서를 뽑는다.
ColBERT는 다른 neural ranker(특히 BERT 기반)들과 다르게 전체 비용이 계산된 임베딩을 모으고 옮기는 것에 지배된다. 일반적인 BERT ranker는 k개의 문서 랭킹시 쿼리 q와 문서 di로 이루어진 k개의 input을 주어야 하기 때문에 비용이 quadratic하게 늘어난다. 하지만 ColBERT는 하나의 쿼리 input만 주기 때문에 훨씬 싸다.
3-6 End-to-end Top-k Retrieval with ColBERT
End-to-end Retrieval의 경우 Top k개 대비 문서 셋 N이 상당히 크다(1000만개 이상).
Late interaction 적용시 MaxSim에서 pruning을 수행한다. 쿼리 임베딩과 모든 문서에 대해서 MaxSim을 적용하지 않고 vector similarity를 이용해 쿼리와 관련 있는 문서들만 찾아 계산한다. 이를 위해 faiss와 같은 라이브러리를 사용한다. 그래서 faiss에 각 문서 임베딩과 문서 매핑 및 문서 임베딩 인덱스를 넣어야 한다.
먼저 faiss의 인덱스에서 vector-similarity 검색을 Nq번 수행해(Eq 내 임베딩 각각에 대해 수행) 각각 문서 top k'개를 뽑아낸다(k' = k/2). 그러면 총 Nq * k' 의 문서가 후보에 오르게 되고(겹치는 것도 있겠지만) 쿼리 임베딩과 높은 유사도를 가진다. 이 문서들을 대상으로 앞서 다뤘던 reranking을 수행한다.
3-7 Evaluation
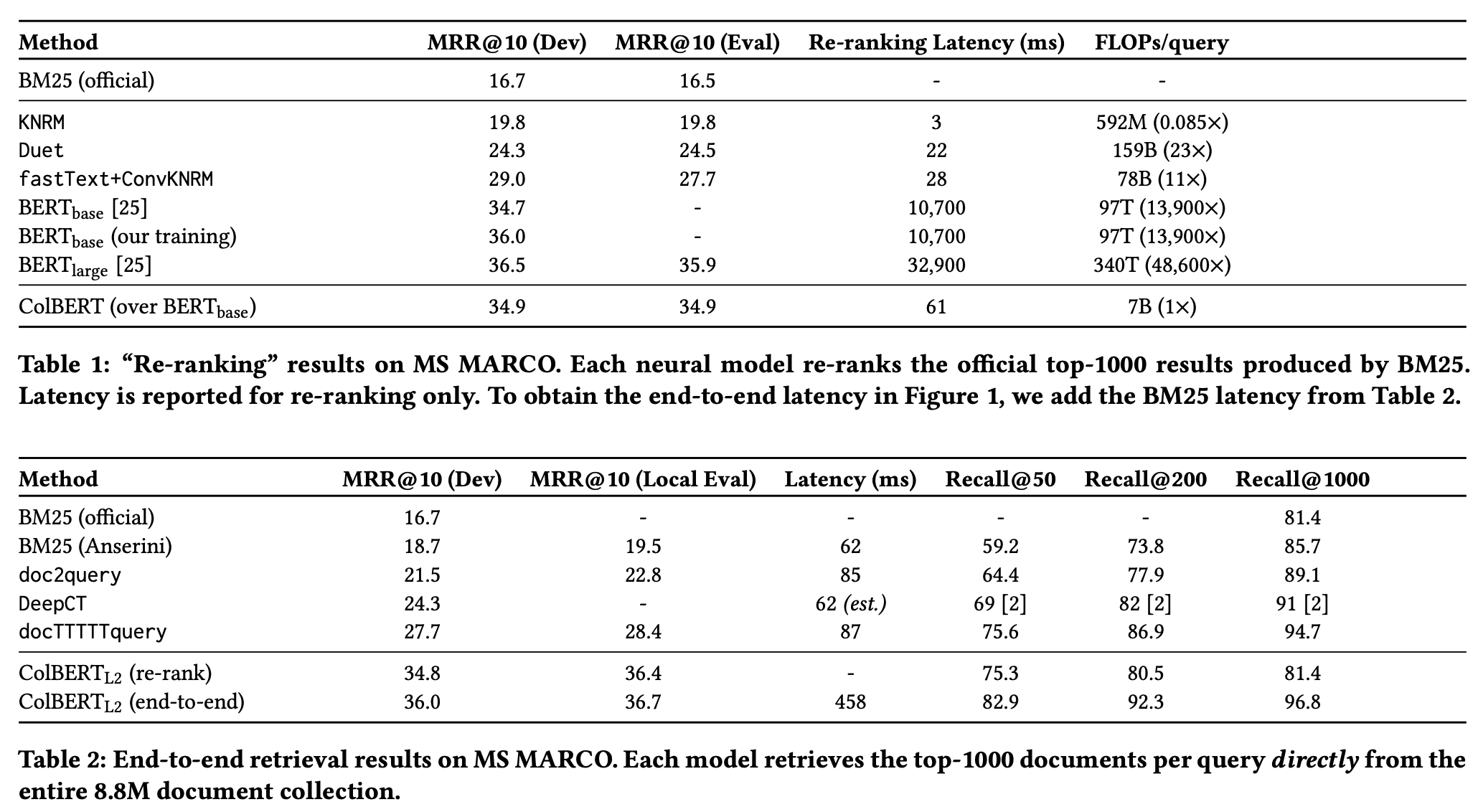
Reranking의 경우 MRR은 BERT에 비해 조금 낮지만 latency는 훨씬 좋다.
End-to-end retrieval은 BM25보다 latency가 많이 느리지만 높은 MRR을 보여주고 있다.
4. ColBERTv2 (2022)
4-1 ColBERTv2 등장 배경
ColBERT의 late interaction은 인코더의 부담은 덜었지만 문서의 space 규모에 따라 비용이 크게 영향을 받았다. 싱글 벡터에서 멀티 벡터로 넘어갔기 때문에 발생한 trade off이다.
한편 IR 연구에서 벡터 representation을 압축하는 연구들이 많이 나오고 있다. ColBERTv2는 이러한 연구를 기반으로 lightweight token representation을 사용하여 효율적으로 스토리지를 사용한다.
4-2 Modeling
ColBERTv2의 모델은 ColBERT의 아키텍처를 그대로 가지고 왔다. 쿼리와 문서들은 BERT에 의해 각각 인코딩되고 output 임베딩은 낮은 차원으로 만들어진다. Offline 색인 과정에서 각 문서 d는 벡터 셋으로 인코딩되고 저장된다. 쿼리 q 역시 멀티 벡터로 인코딩되고 문서 d에 대해 MaxSim으로 점수를 계산한다.
4-3 Representation
ColBERT 벡터 클러스터의 region에는 비슷한 의미를 가진 토큰들이 모여있는 것을 실험을 통해 검증했다. 이를 residual representation에 사용하여 space footprint를 줄이고 off-the-shelf 달성했다.
주어진 어떤 centroid 셋 C에 대해 ColBERTv2는 각 벡터 v를 가장 가까운 centroid Ct의 인덱스로 인코딩하고 residual 벡터(r로 표기)를 v-Ct로 구하였다. 이 residual 벡터를 quantized해 근접한 벡터(~r로 표기)로 저장한다. 이를 통해 검색시 centroid 인덱스 t와 ~r만 있으면 원본 벡터와 근접한 ~v를 구할 수 있다.
~r을 인코딩하기 위해 r의 각 차원을 하나 혹은 두 개의 비트로 quantize한다. n차원의 벡터를 b-bit로 인코딩하려면 벡터당 log|C| + bn 비트가 필요함이 알려져 있다. 논문에서는 n = 128을 사용하고 b=1,2를 사용하여 residual을 인코딩하였다. ColBERT가 16 bit precision에서 256바이트 벡터 인코딩을 사용하는데 반해 20 혹은 36바이트로 벡터 인코딩을 하는 성과를 보였다.
4-4 Indexing
ColBERTv2에서는 인덱싱을 3가지 스테이지로 나눠 수행한다.
(1) Centroid Selection
Residual 인코딩을 위해 centroids 클러스터 셋 C를 선택한다. 보통 |C|의 크기는 임베딩 개수의 root 값에 비례하여 설정한다. 하지만 메모리 소비를 줄이기 위해 컬렉션 크기의 root값에 비례한 문서 샘플들을 BERT 인코더에 넣어 생성된 임베딩으로 k-means 클러스터링을 해 생성했고 실제로 더 잘 작동하는 것을 확인했다.
(2) Passage Encoding
선택된 centroid로 모든 문서를 인코딩한다. 앞서 살펴본대로 각 임베딩에 가장 가까운 centroid를 찾고 quantized residual을 계산한다. 이렇게 압축된 representation을 디스크에 저장한다.
(3) Index Inversion
fast nearest neighbor 검색을 지원하기 위해 같은 centroid를 사용한 임베딩 ID를 그루핑하고 이를 inverted list로 만들어 디스크에 저장한다. 이를 통해 쿼리가 들어왔을 때 토큰 레벨 임베딩으로 빠르게 찾을 수 있다.
4-5 Retrieval
주어진 쿼리 Q의 모든 벡터 Qi에 대해 가장 가까운 centroid를 한 개 이상 찾는다. Inverted list를 이용해 각 centroid에 가까운 문서 임베딩들을 찾고 압축을 풀어 각 쿼리 벡터에 대해 cosine similarity를 계산한다.
각각의 쿼리 토큰에 대해 top-n개의 문서를 후보로 뽑는다. 이 문서들은 완전한 임베딩을 로드할 문서들이다. 이 문서들로 앞서 우리가 보았던 Sqd를 계산해 랭킹을 매긴다.
4-6 Evaluation
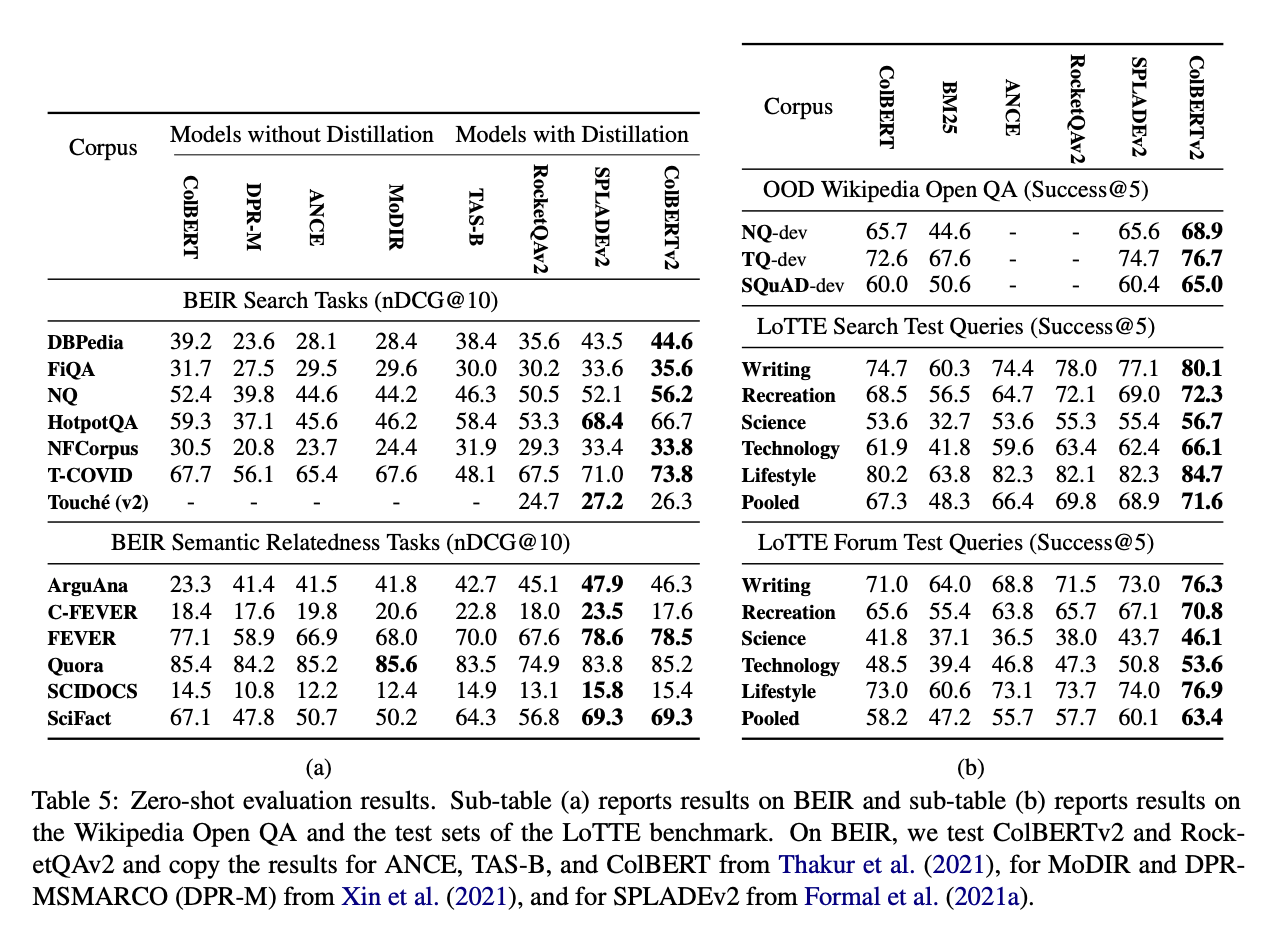
BEIR : out of domain test 용 컬렉션
LoTTE: 논문에서 소개한 데이터 셋으로 Long-Tail Topic-stratified Evaluation.
ColBERTv2의 추천 성능이 타 모델에 비해 좋게 나온 것을 확인할 수 있다. 다만 latency에 대한 evaluation이 나와있지 않아 아쉬웠다.
[Reference]
Stanford CS224U Nerual IR youtube
Standford CS224U Information Retrieval handout
ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction